Hello everyone,
I’m trying to figure out how an fully convolutional image for segmentation works.
I found the following image
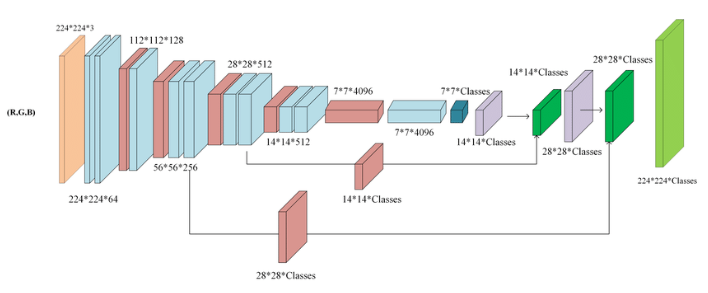
(https://www.researchgate.net/figure/Fully-convolutional-neural-network-architecture-FCN-8_fig1_327521314)
I understand the structure till the last blue rectangle (7x7x4096), because this is just a normal cnn structure.
After that we are doing a 1x1 convolution to reduce the number of feature maps right? To be precise, according to the image the number of filters are reduced to the number of classes?
After that the process of umsampling reaches the same resolution as the input image.
Two questions now:
-
I don’t understand it why we are using K filters, if K is the number of classes. How is the output of 224x244xK interpreted? How do we get the colored/segmented output image like in this picture?
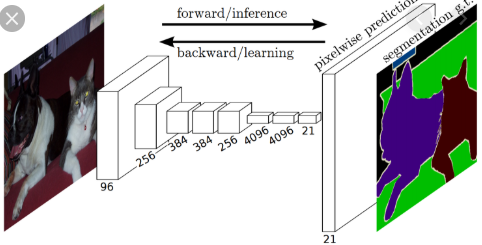
-
What does the train data look like? What is the ground truth and what is the loss function? How do we calculate the loss between the segmented image and ground truth?
Thanks for helping.