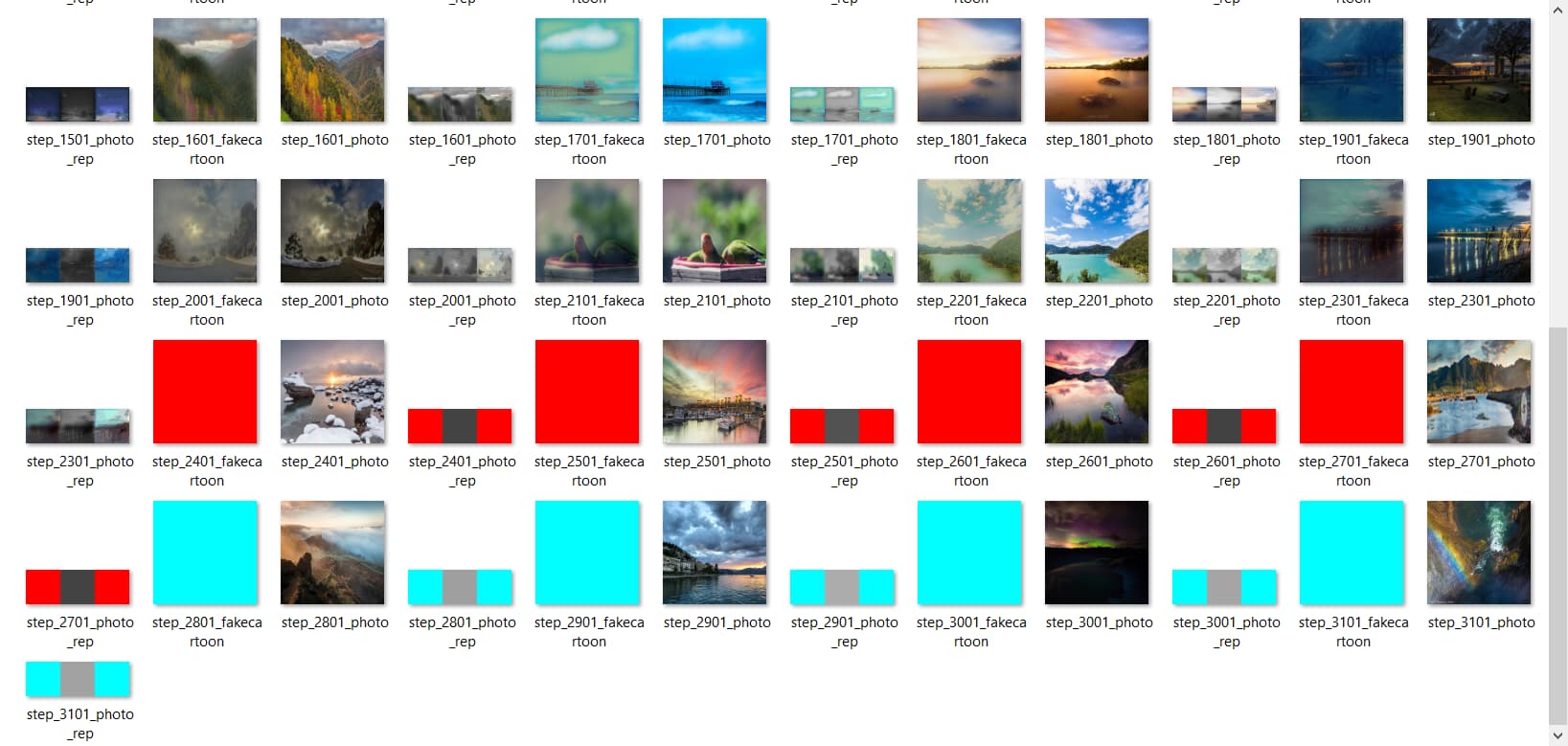
I am implementing a White-box cartoonization GAN model from scratch in PyTorch. I ran into this issue. After the initialization phase, the generator starts giving weird outputs after a few iterations in the training phase. I have been debugging it for a week but to no avail. Does anyone know what this phenomenon means?
Files explanation:
photois the inputfakecartoonis the output of generatorphoto_outputis a processed image depended onfakecartoonphoto_repis a processed image depended onfakecartoon
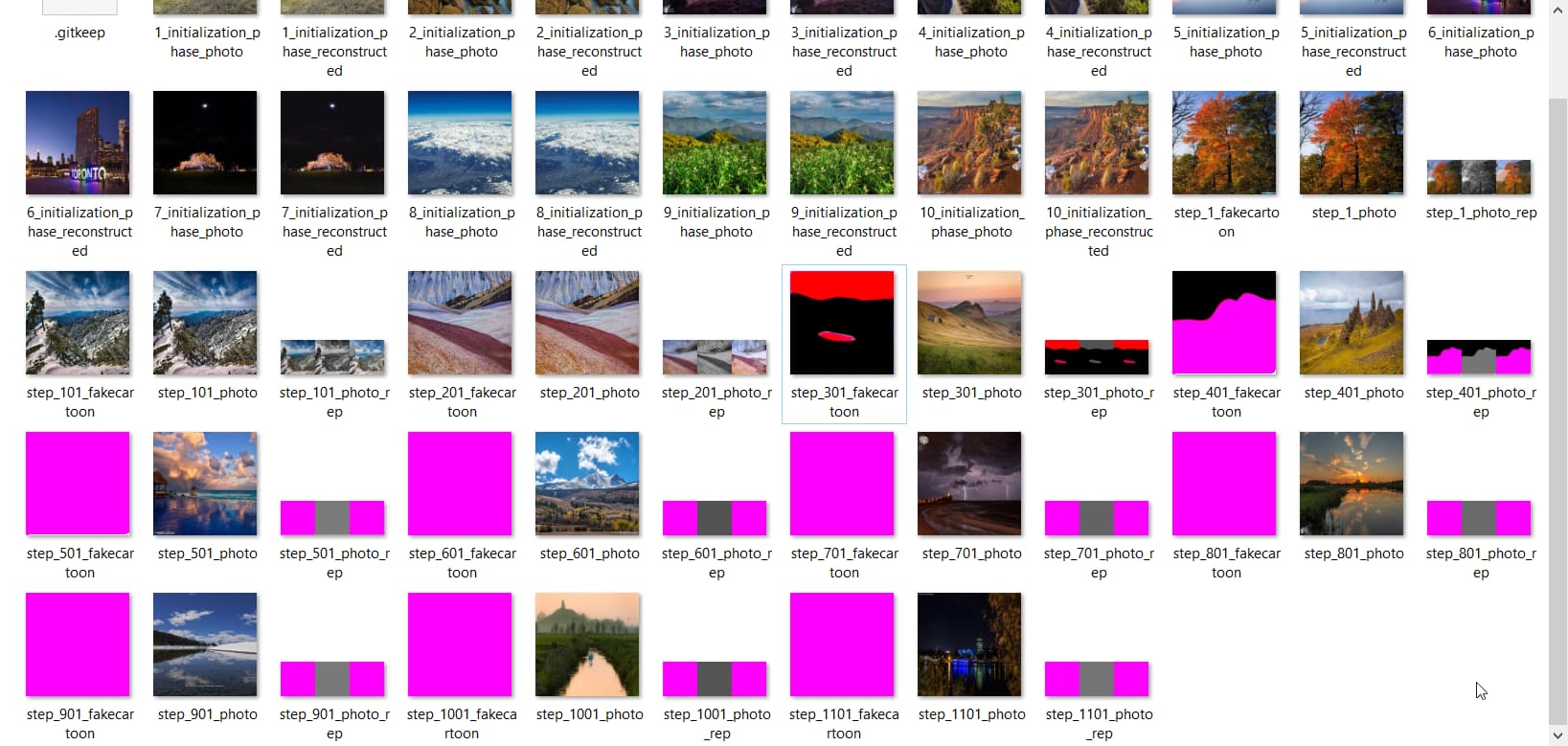
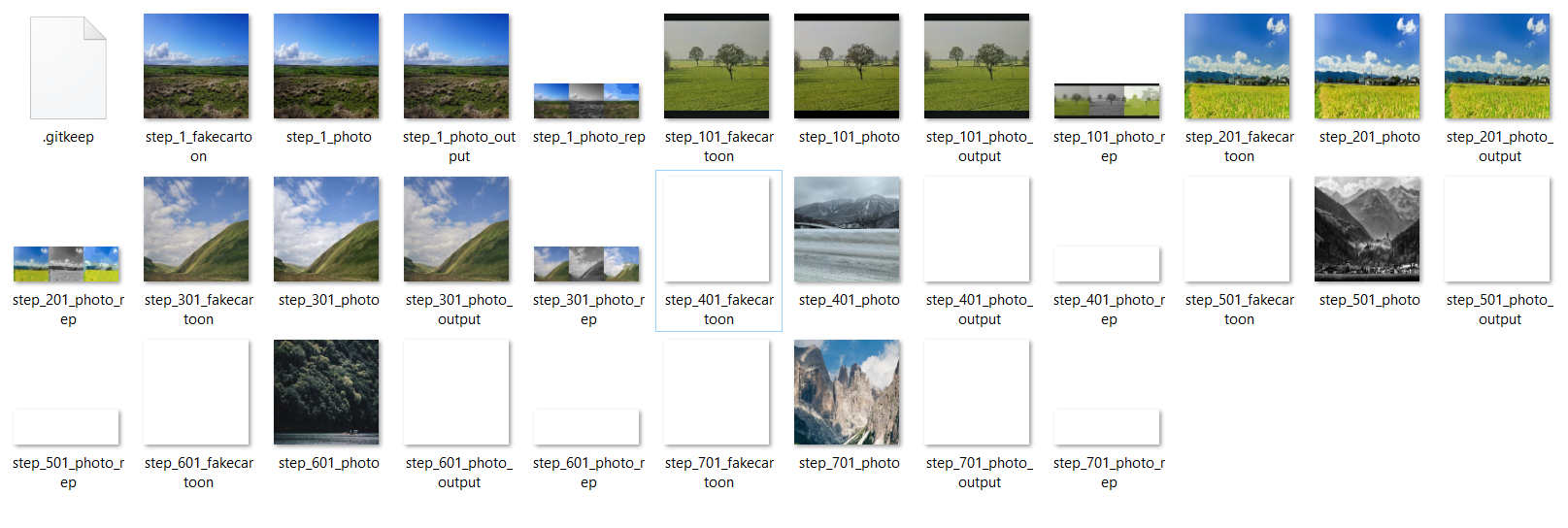
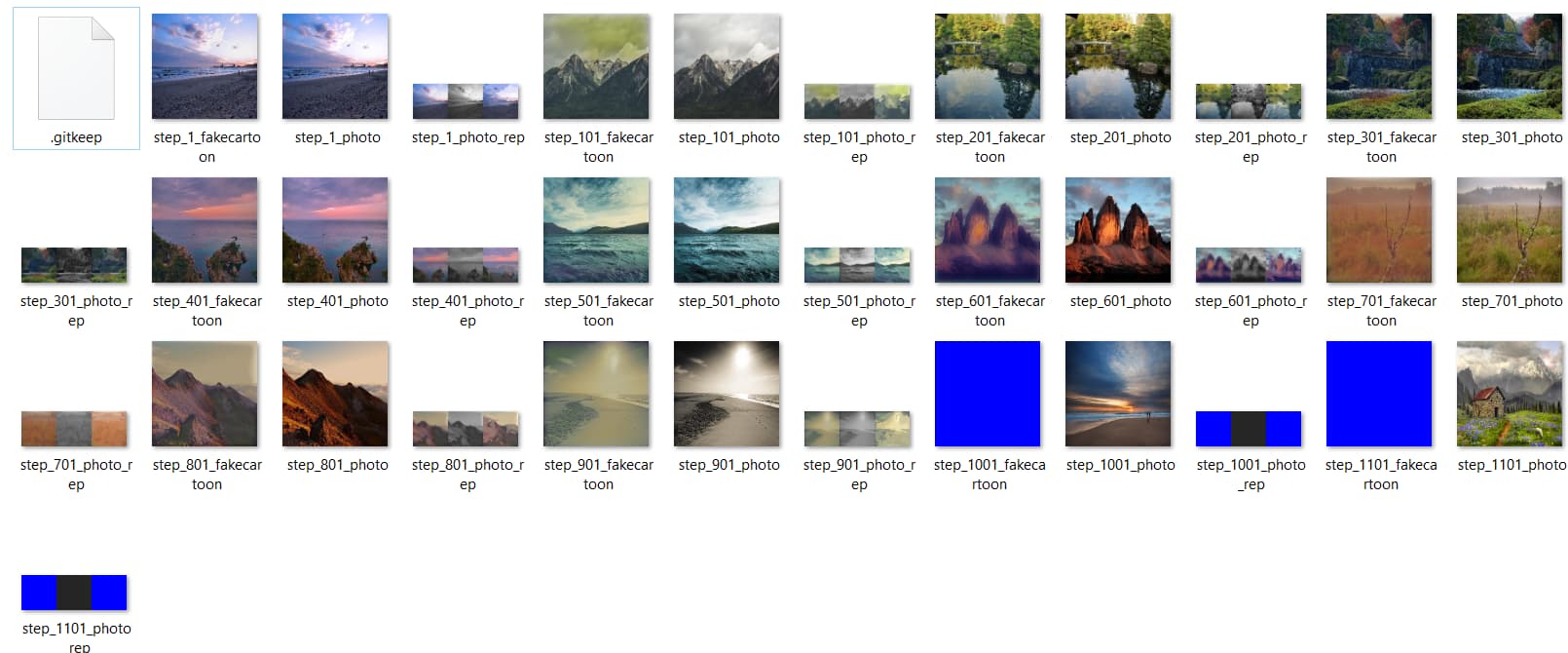
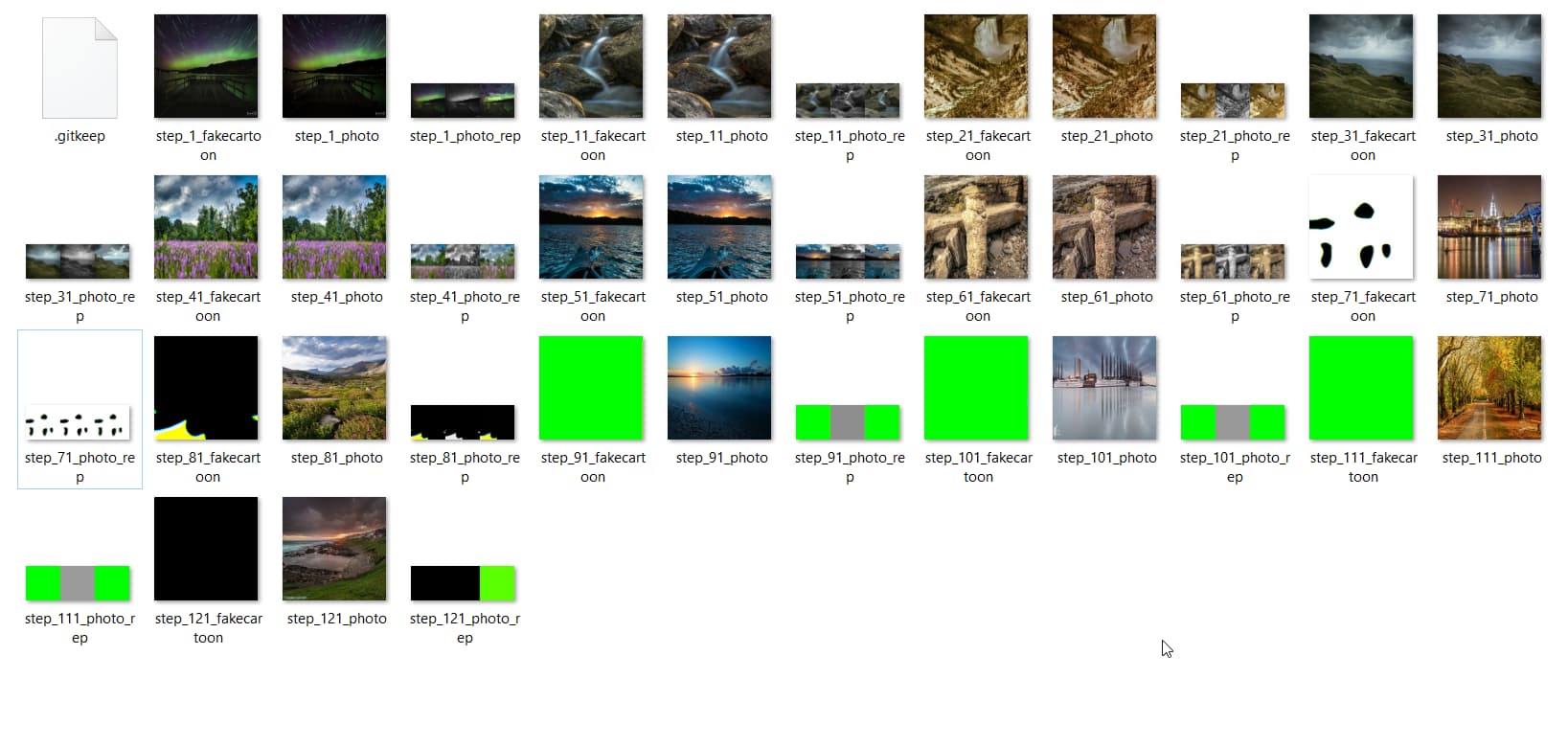
My train.py code:
def initialization_phase(gen, loader, opt_gen, l1_loss, VGG, pretrain_epochs):
for epoch in range(pretrain_epochs):
loop = tqdm(loader, leave=True)
losses = []
for idx, (sample_photo, _) in enumerate(loop):
sample_photo = sample_photo.to(config.DEVICE)
reconstructed = gen(sample_photo)
sample_photo_feature = VGG(sample_photo)
reconstructed_feature = VGG(reconstructed)
reconstruction_loss = l1_loss(reconstructed_feature, sample_photo_feature.detach())
losses.append(reconstruction_loss.item())
opt_gen.zero_grad()
reconstruction_loss.backward()
opt_gen.step()
loop.set_postfix(epoch=epoch)
print('[%d/%d] - Recon loss: %.8f' % ((epoch + 1), pretrain_epochs, torch.mean(torch.FloatTensor(losses))))
save_image(sample_photo*0.5+0.5, os.path.join(config.RESULT_TRAIN_DIR, str(epoch + 1) + "_initialization_phase_photo.png"))
save_image(reconstructed*0.5+0.5, os.path.join(config.RESULT_TRAIN_DIR, str(epoch + 1) + "_initialization_phase_reconstructed.png"))
def train_fn(disc_texture, disc_surface, gen, loader, opt_disc, opt_gen, l1_loss, mse,
VGG, extract_structure, extract_texture, extract_surface, var_loss):
step = 0
for epoch in range(config.NUM_EPOCHS):
loop = tqdm(loader, leave=True)
# Training
for idx, (sample_photo, sample_cartoon) in enumerate(loop):
sample_photo = sample_photo.to(config.DEVICE)
sample_cartoon = sample_cartoon.to(config.DEVICE)
# Train Discriminator
fake_cartoon = gen(sample_photo)
output_photo = extract_surface.process(sample_photo, fake_cartoon, r=1)
# Surface Representation
blur_fake = extract_surface.process(output_photo, output_photo, r=5, eps=2e-1)
blur_cartoon = extract_surface.process(sample_cartoon, sample_cartoon, r=5, eps=2e-1)
D_blur_real = disc_surface(blur_cartoon)
D_blur_fake = disc_surface(blur_fake.detach())
d_loss_surface_real = mse(D_blur_real, torch.ones_like(D_blur_real))
d_loss_surface_fake = mse(D_blur_fake, torch.zeros_like(D_blur_fake))
d_loss_surface = (d_loss_surface_real + d_loss_surface_fake)/2.0
# Textural Representation
gray_fake, gray_cartoon = extract_texture.process(output_photo, sample_cartoon)
D_gray_real = disc_texture(gray_cartoon)
D_gray_fake = disc_texture(gray_fake.detach())
d_loss_texture_real = mse(D_gray_real, torch.ones_like(D_gray_real))
d_loss_texture_fake = mse(D_gray_fake, torch.zeros_like(D_gray_fake))
d_loss_texture = (d_loss_texture_real + d_loss_texture_fake)/2.0
d_loss_total = d_loss_surface + d_loss_texture
opt_disc.zero_grad()
d_loss_total.backward()
opt_disc.step()
#===============================================================================
# Train Generator
fake_cartoon = gen(sample_photo)
output_photo = extract_surface.process(sample_photo, fake_cartoon, r=1)
# Guided Filter
blur_fake = extract_surface.process(output_photo, output_photo, r=5, eps=2e-1)
D_blur_fake = disc_surface(blur_fake)
g_loss_surface = config.LAMBDA_SURFACE * mse(D_blur_fake, torch.ones_like(D_blur_fake))
# Color Shift
gray_fake, = extract_texture.process(output_photo)
D_gray_fake = disc_texture(gray_fake)
g_loss_texture = config.LAMBDA_TEXTURE * mse(D_gray_fake, torch.ones_like(D_gray_fake))
# SuperPixel
input_superpixel = extract_structure.process(output_photo.detach())
vgg_output = VGG(output_photo)
_, c, h, w = vgg_output.shape
vgg_superpixel = VGG(input_superpixel)
superpixel_loss = config.LAMBDA_STRUCTURE * l1_loss(vgg_superpixel, vgg_output) / (c*h*w)
# Content Loss
vgg_photo = VGG(sample_photo)
content_loss = config.LAMBDA_CONTENT * l1_loss(vgg_photo, vgg_output) / (c*h*w)
# Variation Loss
tv_loss = config.LAMBDA_VARIATION * var_loss(output_photo)
g_loss_total = g_loss_surface + g_loss_texture + superpixel_loss + content_loss + tv_loss
opt_gen.zero_grad()
g_loss_total.backward()
opt_gen.step()
#===============================================================================
if step % config.SAVE_IMG_PER_STEP == 0:
save_image(torch.cat((blur_fake*0.5+0.5,gray_fake*0.5+0.5,input_superpixel*0.5+0.5), axis=3), os.path.join(config.RESULT_TRAIN_DIR, "step_" + str(step+1) + "_photo_rep.png"))
save_image(sample_photo*0.5+0.5, os.path.join(config.RESULT_TRAIN_DIR, "step_" + str(step+1) + "_photo.png"))
save_image(fake_cartoon*0.5+0.5, os.path.join(config.RESULT_TRAIN_DIR, "step_" + str(step+1) + "_fakecartoon.png"))
print('[Epoch: %d| Step: %d] - D Surface loss: %.12f' % ((epoch + 1), (step+1), d_loss_surface.item()))
print('[Epoch: %d| Step: %d] - D Texture loss: %.12f' % ((epoch + 1), (step+1), d_loss_texture.item()))
print('[Epoch: %d| Step: %d] - G Surface loss: %.12f' % ((epoch + 1), (step+1), g_loss_surface.item()))
print('[Epoch: %d| Step: %d] - G Texture loss: %.12f' % ((epoch + 1), (step+1), g_loss_texture.item()))
print('[Epoch: %d| Step: %d] - G Structure loss: %.12f' % ((epoch + 1), (step+1), superpixel_loss.item()))
print('[Epoch: %d| Step: %d] - G Content loss: %.12f' % ((epoch + 1), (step+1), content_loss.item()))
print('[Epoch: %d| Step: %d] - G Variation loss: %.12f' % ((epoch + 1), (step+1), tv_loss.item()))
step += 1
loop.set_postfix(step=step, epoch=epoch+1)
if config.SAVE_MODEL and epoch % 5 == 0:
save_checkpoint(gen, opt_gen, epoch, folder=config.CHECKPOINT_FOLDER, filename=config.CHECKPOINT_GEN)
def main():
print(config.DEVICE)
disc_texture = Discriminator(in_channels=3).to(config.DEVICE)
disc_surface = Discriminator(in_channels=3).to(config.DEVICE)
gen = Generator(img_channels=3).to(config.DEVICE)
opt_disc = optim.Adam(itertools.chain(disc_surface.parameters(),disc_texture.parameters()), lr=config.LEARNING_RATE, betas=(0.5, 0.999))
opt_gen = optim.Adam(gen.parameters(), lr=config.LEARNING_RATE, betas=(0.5, 0.999))
VGG19 = VGGNet(in_channels=3, VGGtype="VGG19", init_weights=config.VGG_WEIGHTS, batch_norm=False, feature_mode=True)
VGG19 = VGG19.to(config.DEVICE)
VGG19.eval()
extract_structure = SuperPixel(config.DEVICE, mode='sscolor')
extract_texture = ColorShift(config.DEVICE, mode='uniform', image_format='rgb')
extract_surface = GuidedFilter()
#BCE_Loss = nn.BCELoss()
L1_Loss = nn.L1Loss()
MSE_Loss = nn.MSELoss() # went through the author's code and found him using LSGAN, LSGAN should gives better training
var_loss = VariationLoss(1)
train_dataset = MyDataset(config.TRAIN_PHOTO_DIR, config.TRAIN_CARTOON_DIR)
train_loader = DataLoader(train_dataset, batch_size=config.BATCH_SIZE, shuffle=True, num_workers=config.NUM_WORKERS)
if config.LOAD_MODEL:
is_gen_loaded = load_checkpoint(
gen, opt_gen, config.LEARNING_RATE, folder=config.CHECKPOINT_FOLDER, checkpoint_file=config.LOAD_CHECKPOINT_GEN
)
is_disc_loaded = load_checkpoint(
disc_texture, opt_disc, config.LEARNING_RATE, folder=config.CHECKPOINT_FOLDER, checkpoint_file=config.LOAD_CHECKPOINT_DISC
)
is_disc_loaded = load_checkpoint(
disc_surface, opt_disc, config.LEARNING_RATE, folder=config.CHECKPOINT_FOLDER, checkpoint_file=config.LOAD_CHECKPOINT_DISC
)
# Initialization Phase
if not(is_gen_loaded):
print("="*80)
print("=> Initialization Phase")
initialization_phase(gen, train_loader, opt_gen, L1_Loss, VGG19, config.PRETRAIN_EPOCHS)
print("Finished Initialization Phase")
print("="*80)
if config.SAVE_MODEL:
save_checkpoint(gen, opt_gen, 'i', folder=config.CHECKPOINT_FOLDER, filename=config.CHECKPOINT_GEN)
# Do the training
print("=> Start Training")
train_fn(disc_texture, disc_surface, gen, train_loader, opt_disc, opt_gen, L1_Loss, MSE_Loss,
VGG19, extract_structure, extract_texture, extract_surface, var_loss)
print("=> Training finished")
if __name__ == "__main__":
main()
I would be so grateful if anyone could give me some help or insight into how this phenomenon happens.