This is a toy code (which is exactly similar to your example, but much simpler for the sake of sanity!).
class TmpModel(torch.nn.Module):
def __init__(self):
super().__init__()
self.x = [nn.Parameter(torch.Tensor(1))]
self.x[0].requires_grad = False
self.y = nn.Parameter(torch.Tensor(1))
self.z = nn.Parameter(torch.Tensor(1))
def forward(self, i1):
o1 = self.y * i1
self.x[0].zero_().add_(o1)
return self.x[0] * self.z
for i in range(2):
i1 = torch.ones(1)
out = model_new(i1)
out.backward()
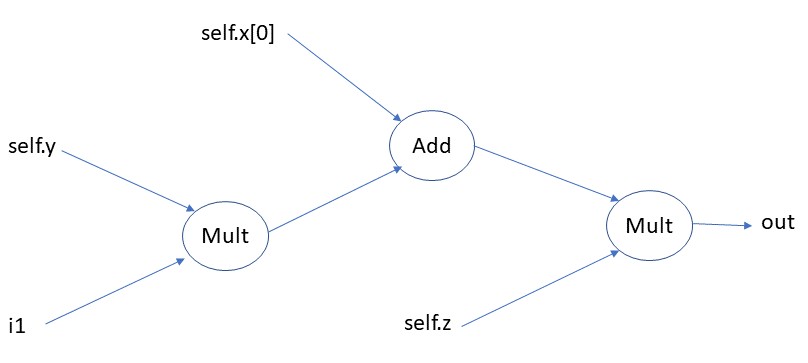
If you traverse the autograd graph (by repeatedly using out.grad_fn.next_functions). You will find the below autograd graph. First image is the computation graph for iteration 0 & second image is the computation graph for iteration 1.
Computation graph 1
Computation graph 2
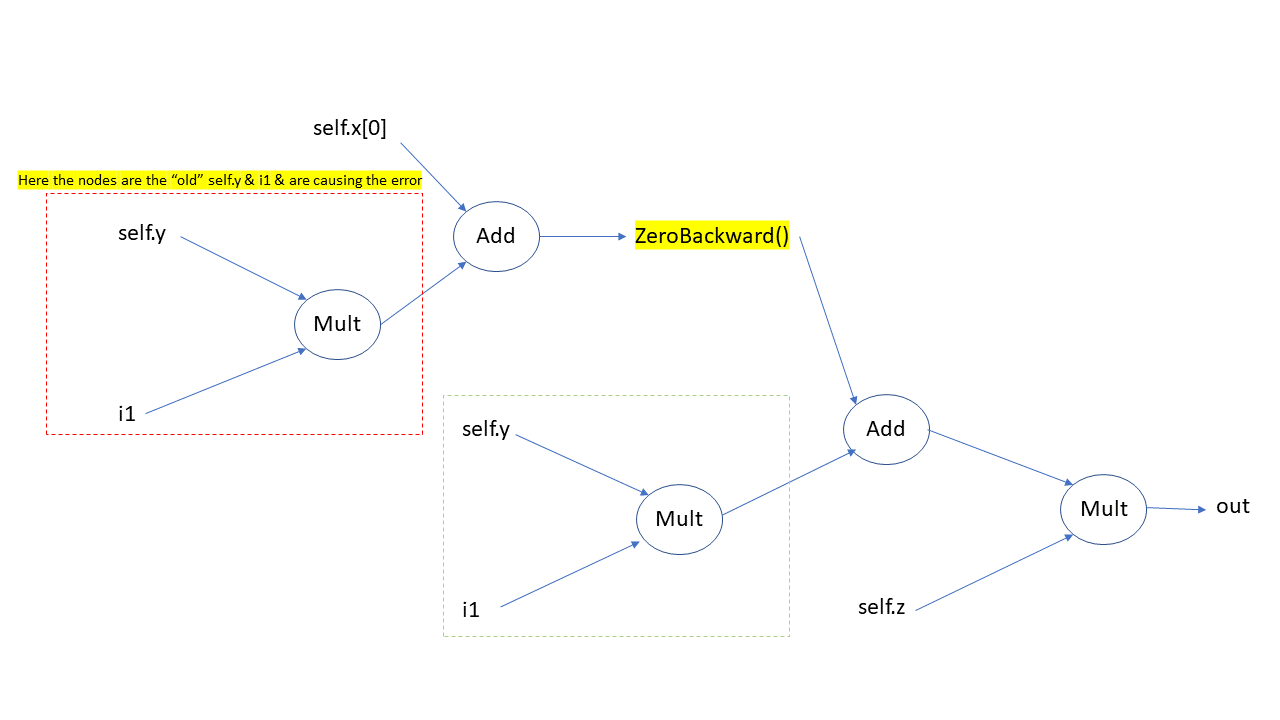
The dashed “red” box has the old nodes of i1 and self.y. Why? This is due to how in-place operation combines with autograd (see this post : link ). Since the computation graph 2 has old values as one of the nodes, you get the RunTime error.
Just for reference, the things I used to debug this was using .grad_fn.next_functions & running the code within a with torch.autograd.set_detect_anomaly(True) block. You can ping me if you need any more details regarding debugging. ![]()