Hello Community,
I’m relativly new to Pytorch and wanted to try something out.
My Idea was to generate a voice, using the DCGAN Example from the Tutorial,
found on this website: Using the PyTorch C++ Frontend — PyTorch Tutorials 2.2.0+cu121 documentation
So I changed the Generator and Discriminator to work with 1-dimensional Convolutions, since
that makes more sense for Soundsequences. I created Functions to transform Tensors to Wave-Files (16bit/Mono/44100 Samples/Second) and vice versa using this: GitHub - adamstark/AudioFile: A simple C++ library for reading and writing audio files. Wavefile Converter from Adam Stark.
The functions are described in WaveKonverter1D.hpp :
#pragma once
#include <torch/torch.h>
#include <vector>
#include "AudioFile.h"
void Tensor2Wave(torch::Tensor source, std::string name, std::string destination, const int64_t length)
{
std::stringstream ss;
ss << destination << name;
//We don't change source
torch::Tensor data = source.view({ length, });
auto acc = data.accessor<float, 1>();
AudioFile<float> audioFile;
audioFile.setBitDepth(16);
audioFile.setSampleRate(44100);
audioFile.setAudioBufferSize(1, length);
for (int i = 0; i < length; ++i)
{
audioFile.samples[0][i] = acc[i];
}
audioFile.save(ss.str(), AudioFileFormat::Wave);
}
torch::Tensor Wave2Tensor(std::string source, const int64_t length)
{
//Vektor
torch::Tensor output = torch::zeros({ length, });
auto acc = output.accessor<float, 1>();
AudioFile<float> audioFile;
audioFile.load(source);
int sampleRate = audioFile.getSampleRate();
int bitDepth = audioFile.getBitDepth();
int numSamples = audioFile.getNumSamplesPerChannel();
double lengthInSeconds = audioFile.getLengthInSeconds();
int numChannels = audioFile.getNumChannels();
float* samples = new float[numSamples];
if (length != numSamples && numChannels != 1)
{
std::cout << "Fehler, Channelmenge oder Länge des Tensors passt nicht" << std::endl;
std::cout << "Either # of Channels or length of Tensor inapproriate" << std::endl;
return output;
}
for (int i = 0; i < numSamples; i++)
{
samples[i] = audioFile.samples[0][i];
acc[i] = samples[i];
}
delete[] samples;
return output;
}
std::vector<torch::Tensor> Wave2TensorSplit(std::string source, const int64_t length)
{
std::vector<torch::Tensor> result;
AudioFile<float> audioFile;
if (!audioFile.load(source))
{
std::cout << "Fehler, kann Audiodatei nicht öffnen" << std::endl;
std::cout << "Cannot open Audiofile" << std::endl;
return result;
}
//Get #Samples
int sampleRate = audioFile.getSampleRate();
int bitDepth = audioFile.getBitDepth();
int numSamples = audioFile.getNumSamplesPerChannel();
int numChannels = audioFile.getNumChannels();
int numClips = numSamples / length;
if (numClips <= 0)
{
std::cout << "Fehler, Audiodatei zu kurz" << std::endl;
std::cout << "Audio too short" << std::endl;
return result;
}
if (numChannels != 1)
{
std::cout << "Fehler, Audiodatei nicht Mono" << std::endl;
std::cout << "Audio not Mono" << std::endl;
return result;
}
if (bitDepth != 16)
{
std::cout << "Fehler, Audiodatei nicht in 16bit Auflösung" << std::endl;
std::cout << "Audio not 16bit PCM" << std::endl;
return result;
}
if (sampleRate != 44100)
{
std::cout << "Fehler, Sample Rate ist nicht 44100 Samples/Sekunde" << std::endl;
std::cout << "Samplerate not at 44100 Samples/Second" << std::endl;
return result;
}
//For all Soundclips
for (int k = 0; k < numClips; ++k)
{
//Create Tensor-Vector and add to std::vector
float* samples = new float[length];
result.push_back(torch::empty({ length, }));
auto acc = result[k].accessor<float, 1>();
//Read one Audioclip per Tensor
for (int i = 0; i < length; ++i)
{
//Absolute Positon in Audiostream
samples[i] = audioFile.samples[0][k * length + i];
acc[i] = samples[i];
}
delete[] samples;
}
return result;
}
Then I create a DCGAN Model and train it with about 5 Minutes of me, reading a text as a .wav File.
I also invert the amplitudes and added another 5 minutes of sound that way. I was hoping it might improve
problems that the model could encounter when it comes to the phase of the soundwaves.
The actual DCGAN and the training-loop can be found in main.cpp :
#include <iostream>
#include <torch/torch.h>
#include <clocale>
#include "WaveKonverter1D.hpp"
#include "AudioFile.h"
//Width of Output Tensor (1D)
const int64_t kLength = 150414; //About 3 - 4 Seconds of Sound at 44100 Samples/Second
//Noise Vektor
const int64_t kNoiseSize = 1000;
// After how many batches to create a new checkpoint periodically.
const int64_t kCheckpointEvery = 100;
//Batchsize
const int64_t kBatchSize = 5;
//Epochs
const int64_t kNumberOfEpochs = 2000; //Would take several days on GTX 980ti to finish
// After how many batches to log a new update with the loss value.
const int64_t kLogInterval = 1;
//Load Models + Optimizers from last session
const bool kRestoreFromCheckpoint = false;
class VoiceDataset : public torch::data::Dataset<VoiceDataset>
{
private:
//Vector from 1D-Tensoren with each kLenght lenght
std::vector<torch::Tensor> soundclips;
public:
explicit VoiceDataset(const std::string& soundclips_path, const int64_t length) : soundclips(Wave2TensorSplit(soundclips_path, length))
{};
//Override of Get-Method
torch::data::Example<> get(size_t index) override;
//Override of size-Method
c10::optional<size_t> size() const override
{
return soundclips.size();
}
};
torch::data::Example<> VoiceDataset::get(size_t index)
{
//We ignore batch.target, we make softlabels
return { soundclips[index], torch::ones({1,}) };
}
int main()
{
//manuel seed? will it improve performance?
torch::manual_seed(1);
//Search for CUDA GPU
torch::Device device(torch::kCPU);
if (torch::cuda::is_available())
{
std::cout << "CUDA is available! Training on GPU." << std::endl;
device = torch::Device(torch::kCUDA);
}
else
{
std::cout << "Using CPU" << std::endl;
}
//Generator from CNN + TCNN, big Kernelsizes for better performance?
torch::nn::Sequential generator(
//Layer 1
torch::nn::Conv1d(torch::nn::Conv1dOptions(1, 32, 80).stride(2).padding(0).with_bias(false)),
torch::nn::BatchNorm(32),
torch::nn::Functional(torch::leaky_relu, 0.2),
//Layer 2
torch::nn::Conv1d(torch::nn::Conv1dOptions(32, 64, 96).stride(2).padding(3).with_bias(false).transposed(true)),
torch::nn::BatchNorm(64),
torch::nn::Functional(torch::relu),
// Layer 3
torch::nn::Conv1d(torch::nn::Conv1dOptions(64, 128, 96).stride(3).padding(3).with_bias(false).transposed(true)),
torch::nn::BatchNorm(128),
torch::nn::Functional(torch::relu),
//Layer 4
torch::nn::Conv1d(torch::nn::Conv1dOptions(128, 128, 64).stride(4).padding(2).with_bias(false).transposed(true)),
torch::nn::BatchNorm(128),
torch::nn::Functional(torch::relu),
// Layer 5
torch::nn::Conv1d(torch::nn::Conv1dOptions(128, 128, 32).stride(3).padding(1).with_bias(false).transposed(true)),
torch::nn::BatchNorm(128),
torch::nn::Functional(torch::relu),
// Layer 6
torch::nn::Conv1d(torch::nn::Conv1dOptions(128, 128, 16).stride(2).padding(0).with_bias(false)),
torch::nn::BatchNorm(128),
torch::nn::Functional(torch::leaky_relu, 0.2),
// Layer 7
torch::nn::Conv1d(torch::nn::Conv1dOptions(128, 128, 16).stride(2).padding(1).with_bias(false).transposed(true)),
torch::nn::BatchNorm(128),
torch::nn::Functional(torch::relu),
// Layer 8
torch::nn::Conv1d(torch::nn::Conv1dOptions(128, 64, 16).stride(2).padding(0).with_bias(false).transposed(true)),
torch::nn::BatchNorm(64),
torch::nn::Functional(torch::relu),
// Layer 9
torch::nn::Conv1d(torch::nn::Conv1dOptions(64, 1, 4).stride(2).padding(0).with_bias(false).transposed(true)),
torch::nn::Functional(torch::tanh)
);
//To GPU
generator->to(device);
//Diskirminator with CNN + FFNN
torch::nn::Sequential discriminator(
// Layer 1
torch::nn::Conv1d(
torch::nn::Conv1dOptions(1, 64, 64).stride(1).padding(1).with_bias(false)),
torch::nn::Functional(torch::leaky_relu, 0.2),
// Layer 2
torch::nn::Conv1d(
torch::nn::Conv1dOptions(64, 128, 96).stride(3).padding(1).with_bias(false)),
torch::nn::BatchNorm(128),
torch::nn::Functional(torch::leaky_relu, 0.2),
// Layer 3
torch::nn::Conv1d(
torch::nn::Conv1dOptions(128, 128, 96).stride(4).padding(1).with_bias(false)),
torch::nn::BatchNorm(128),
torch::nn::Functional(torch::leaky_relu, 0.2),
// Layer 4
torch::nn::Conv1d(
torch::nn::Conv1dOptions(128, 128, 64).stride(5).padding(0).with_bias(false)),
torch::nn::BatchNorm(128),
torch::nn::Functional(torch::leaky_relu, 0.2),
// Layer 5
torch::nn::Conv1d(
torch::nn::Conv1dOptions(128, 128, 32).stride(2).padding(0).with_bias(false)),
torch::nn::BatchNorm(128),
torch::nn::Functional(torch::leaky_relu, 0.2),
//Layer 6
torch::nn::Conv1d(
torch::nn::Conv1dOptions(128, 1, 16).stride(1).padding(0).with_bias(false)), //1214
torch::nn::Functional(torch::sigmoid),
//Layer 7
torch::nn::Linear(1214, 500),
torch::nn::Functional(torch::sigmoid),
//Layer 8
torch::nn::Linear(500, 1),
torch::nn::Functional(torch::sigmoid)
);
//To GPU
discriminator->to(device);
//Load Data (over 5 min of Recorded Speech + 5 min of recorded Speech with inverted Amplitudes)
auto data_set = VoiceDataset("VoiceMe\\Recording.wav", kLength).map(torch::data::transforms::Stack<>());
const int64_t batches_per_epoch =
std::ceil(data_set.size().value() / static_cast<double>(kBatchSize));
auto data_loader = torch::data::make_data_loader<torch::data::samplers::SequentialSampler>(
std::move(data_set),
kBatchSize);
//Create Optimizer
torch::optim::Adam generator_optimizer(
generator->parameters(), torch::optim::AdamOptions(2e-3).beta1(0.5));
torch::optim::Adam discriminator_optimizer(
discriminator->parameters(), torch::optim::AdamOptions(2e-3).beta1(0.5));
if (kRestoreFromCheckpoint)
{
torch::load(generator, "generator-checkpointX.pt");
torch::load(generator_optimizer, "generator-optimizer-checkpointX.pt");
torch::load(discriminator, "discriminator-checkpointX.pt");
torch::load(discriminator_optimizer, "discriminator-optimizer-checkpointX.pt");
}
int64_t checkpoint_counter = 1;
int64_t exports = 0;
for (int64_t epoch = 1; epoch <= kNumberOfEpochs; ++epoch)
{
int64_t batch_index = 0;
for (torch::data::Example<>& batch : *data_loader) {
// Train discriminator with real voice
discriminator->zero_grad();
torch::Tensor real_voices = batch.data.to(device);
//1 as Softlabel goal
torch::Tensor real_labels =
torch::empty(batch.data.size(0), device).uniform_(0.8, 1.0);
//Discriminator test [kBatchsize,1,kLenght]
torch::Tensor real_output = discriminator->forward(real_voices.view({ batch.data.size(0),1,kLength }));
torch::Tensor d_loss_real =
torch::binary_cross_entropy(real_output, real_labels);
d_loss_real.backward();
// Train discriminator with fake voice
torch::Tensor noise =
torch::randn({ batch.data.size(0), 1, kNoiseSize }, device);
torch::Tensor fake_voices = generator->forward(noise);
torch::Tensor fake_labels = torch::empty(batch.data.size(0), device).uniform_(0.0, 0.2);
torch::Tensor fake_output = discriminator->forward(fake_voices.view({ batch.data.size(0),1,kLength }));
torch::Tensor d_loss_fake =
torch::binary_cross_entropy(fake_output, fake_labels);
d_loss_fake.backward();
torch::Tensor d_loss = d_loss_real + d_loss_fake;
discriminator_optimizer.step();
//Not needed on GPU anymore, delete to save Space on VRAM
fake_voices.to(torch::kCPU);
// Train generator.
generator->zero_grad();
fake_labels.fill_(1);
//Must regenerate Fake Voice
torch::Tensor fake_voices_new = generator->forward(noise);
torch::Tensor fake_output_new = discriminator->forward(fake_voices_new.view({ batch.data.size(0),1,kLength }));
torch::Tensor g_loss =
torch::binary_cross_entropy(fake_output_new, fake_labels);
g_loss.backward();
generator_optimizer.step();
exports++;
if (batch_index % kLogInterval == 0) {
std::printf(
"\r[%2ld/%2ld][%3ld/%3ld] D_loss: %.4f | G_loss: %.4f",
epoch,
kNumberOfEpochs,
++batch_index,
batches_per_epoch,
d_loss.item<float>(),
g_loss.item<float>());
}
if (exports % kCheckpointEvery == 0) {
// Checkpoint the model and optimizer state.
torch::save(generator, "generator-checkpointX.pt");
torch::save(generator_optimizer, "generator-optimizer-checkpointX.pt");
torch::save(discriminator, "discriminator-checkpointX.pt");
torch::save(
discriminator_optimizer, "discriminator-optimizer-checkpointX.pt");
// Sample the generator and save the voice
torch::Tensor sample = generator->forward(torch::randn(
{ 1, 1, kNoiseSize }, device));
//Save a generated Voice Sample
std::stringstream ss;
ss << "out" << checkpoint_counter << ".wav";
Tensor2Wave(sample.to(torch::kCPU), ss.str(), "VoiceMe\\", kLength);
std::cout << std::endl << "Resynthesis completed: " << "VoiceMe\\" << ss.str() << std::endl;
std::cout << "\n-> checkpoint " << ++checkpoint_counter << '\n';
}
}
}
std::cout << "Training complete!" << std::endl;
return EXIT_SUCCESS;
}
As mentioned above, I’ve based it on the Code in the Tutorial. Now the problem I have is that
after running this Code for 21 Hours, the results hardly sound any human to me. There’s always a monotone Frequency audible in the background, and the Waveforms don’t look similar to a natural voice:
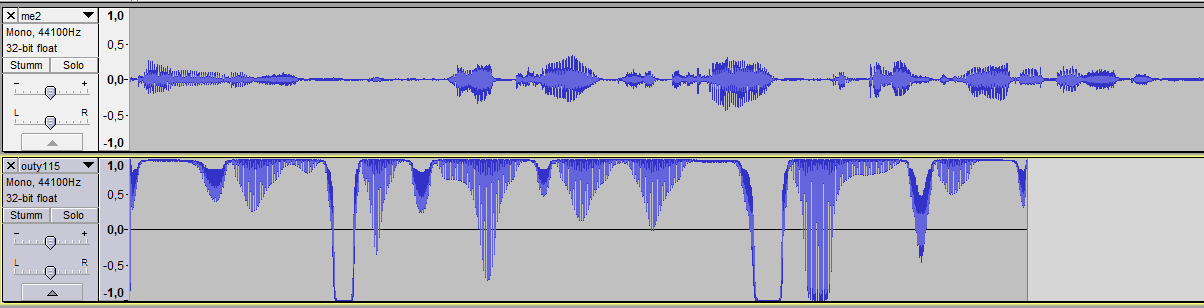
Above: My voice Below: Output after about 21 Hours of Training
What’s weird is, that the Wave is kind of clipping at the maximum.
Now I have two questions:
- Is there any way a DCGAN like the one I’m using could ever generate something that sounds like a human voice?
- If so, what would you change here (Layers/Optimizers/Trainingdata/…)?
I’m open for any suggestions and advice, since I don’t have much experience in deep learning. I also accept python code, I’m only using the C++ API here, because I’m more used to C++.
OS: Windows 10
IDE: Visual Studio Community 2019
GPU: GTX 980ti
Libtorch: Latest Nightly Build for CUDA 10 (I don’t know how to read an accurate version string)
To Mention:
The Discriminator Loss approaches a value of 0.7 very rapidly after the first checkpoint and stays there forever, while the Loss of the Generator stays at around 2.5. I’ve read that a discriminator loss, rapidly approaching 0 is a bad sign, does this apply here as well?
I’ve also bumped up the Kernel sizes in both the Generator and Discriminator, hoping that it would help the networks to learn more complex patterns. Does that make sense? It clearly causes my GPU to require more VRAM, I’m almost using all of the 6GB at this point. So my GPU is at it’s limits with this model, that’s why I can only use a batchsize of 5.
In the originial example, they’re using a manual seed of 1, is this important for successful learning?
If this Post is inappropriate for this category, since it’s a general problem I have, please tell me.
Thank you in advance for any help
Regards,
Florian
Update:
Here are screenshots of my current training session (Checkpoint 1 is actually the 5th one, since I restarted the training)
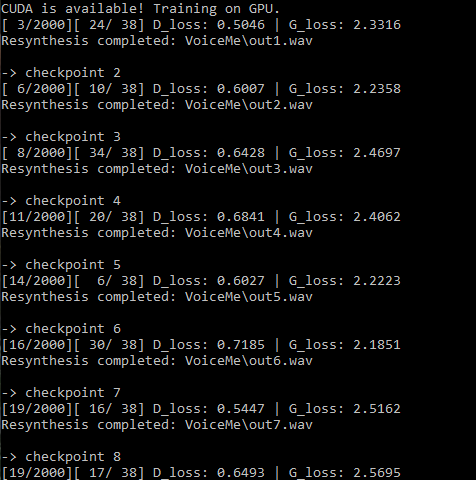
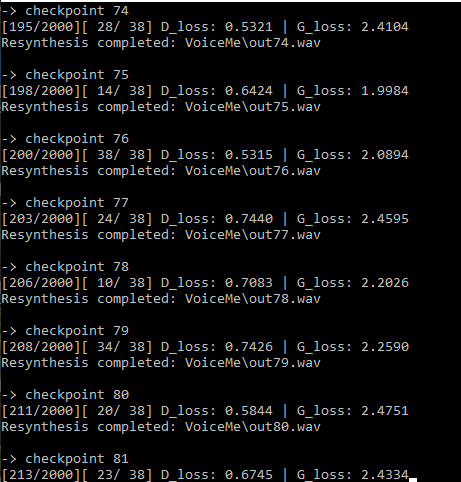
You can see that the loss sticks at around these values
I’ve also uploaded a few output samples, so you can listen for youself, one is a snippet of the recording,
the rest are results from the training. (Warning: High frequency, better turn down your volume!)
Results: Results - Voice Generation - Google Drive