Hi guys! I’m using this code to inpaint missing parts of the image:
disc = Discriminator(
latent_vector_size = LATENT_VECTOR_SIZE,
features_d = IMAGE_SIZE,
num_channels = CHANNELS
)
disc.build()
disc.apply(Discriminator.init_weights)
disc.define_optim(
learning_rate = LEARNING_RATE,
beta1 = BETA1
)
gen = Generator(
features_g = IMAGE_SIZE,
num_channels = CHANNELS
)
gen.build()
gen.apply(Generator.init_weights)
gen.define_optim(
learning_rate = LEARNING_RATE,
beta1 = BETA1
)
gen.to(device)
disc.to(device)
adversarial_loss = nn.MSELoss()
for epoch in range(EPOCHS):
for batch_num, data in enumerate(train_dataloader, 0):
real_image = data[0].to(device)
masked_image = masker(data)
resized_image = resizer(data)
masked_image = masked_image.to(device)
resized_image = resized_image.to(device)
valid = torch.full((BATCH_SIZE, 1, 8, 8), real_label, dtype = torch.float, device = device)
fake = torch.full((BATCH_SIZE, 1, 8, 8), fake_label, dtype = torch.float, device = device)
## TRAIN GENERATOR ##
gen.zero_grad()
generated_images = gen(masked_image, resized_image)
generator_loss = adversarial_loss(disc(generated_images), valid)
generator_loss.backward()
gen.optimizer.step()
## TRAIN DISCRIMINATOR ##
disc.zero_grad()
real_loss = adversarial_loss(disc(real_image), valid)
fake_loss = adversarial_loss(disc(generated_images.detach()), fake)
discriminator_loss = 0.5 * (real_loss + fake_loss)
discriminator_loss.backward()
disc.optimizer.step()
if batch_num % 50 == 0:
print(
f'[{epoch + 1}/{EPOCHS}][{batch_num}/{len(train_dataloader)}] '
f'D_Loss : {round(discriminator_loss.item(),4)} '
f'G_Loss : {round(generator_loss.item(),4)}'
)
with torch.no_grad():
img_grid_fake = torchvision.utils.make_grid(generated_images[:24], normalize = True)
img_grid_real = torchvision.utils.make_grid(real_image[:24], normalize = True)
if batch_num == 0 and epoch == 0:
img_grid_mask = torchvision.utils.make_grid(masked_image[:24], normalize = True)
writer_mask.add_image("Mask", img_grid_mask, global_step = step)
img_grid_resi = torchvision.utils.make_grid(resized_image[:24], normalize = True)
writer_resi.add_image("Resi", img_grid_resi, global_step = step)
writer_real.add_image("Real", img_grid_real, global_step = step)
writer_fake.add_image("Fake", img_grid_fake, global_step = step)
step = step + 1
if batch_num % 100 == 0:
G_losses.append(generator_loss.item())
D_losses.append(discriminator_loss.item())
batches_done = epoch * len(train_dataloader) + batch_num
if batches_done % 5000 == 0:
gen.eval()
gen.train()
(if needed I’ll post the Generator and Discriminator models themselves as well).
However, the loss values turn up like this:
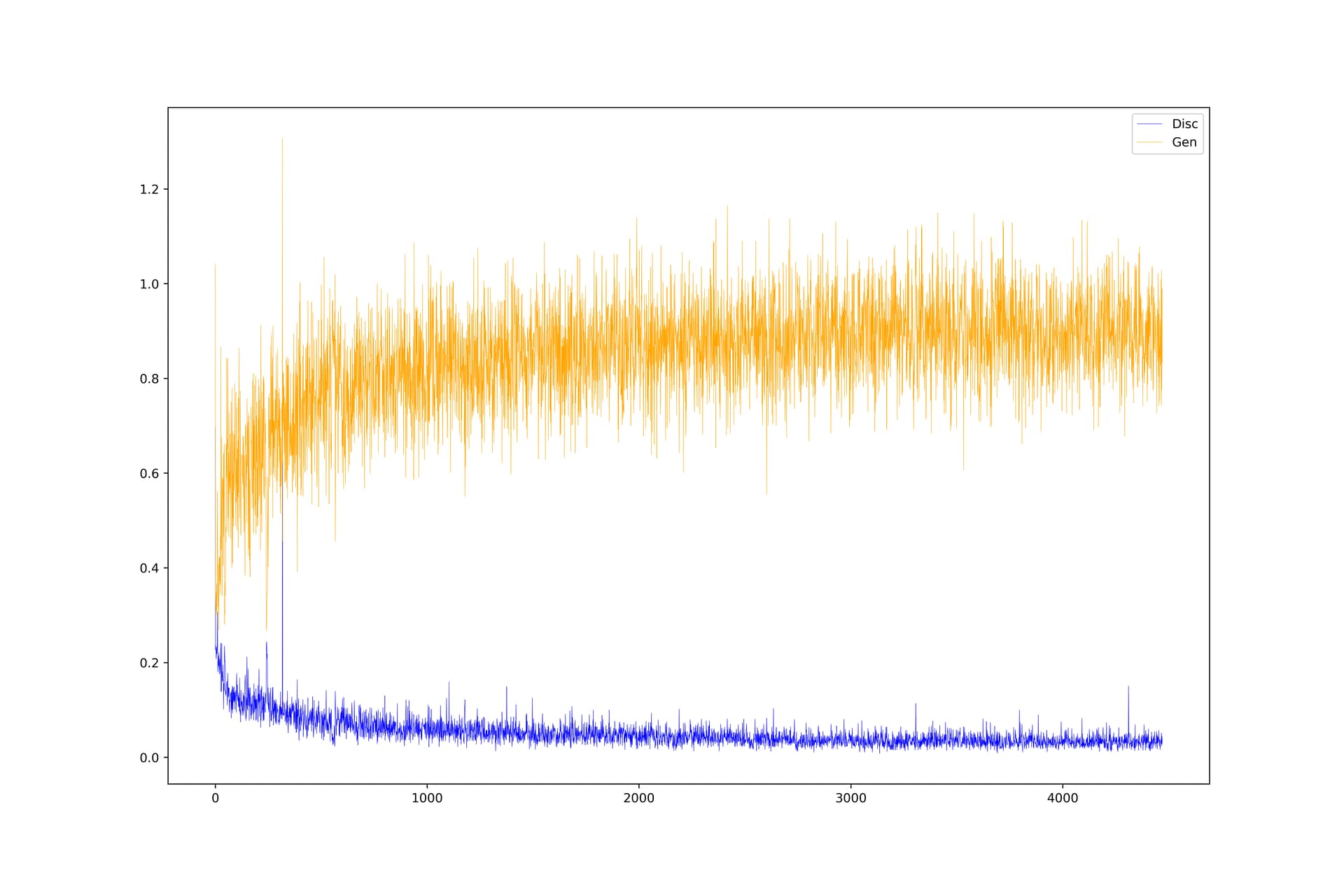
The discriminator converges relatively fast, but the generator is all around the place. The GAN is CCGAN based on this article.
Any tips? Thanks!