It is very difficult to adjust the best hyper-parameters in the process of studying the deep learning model.

Is there some great function in PyTorch to get the best learning rate?
2 Likes
I’m sure that if you find such function, your easily get the best paper award at NeurIPS !
This is an active area of research so no solution exists 
5 Likes
That’s right.
Thanks for the best answer.
Hi @shirui-japina,
There is actually a guy called Leslie N. Smith who created this paper.
Based on this paper, some other guy created the learning rate finder.
What, it does, it measures the loss for the different learning rates and plots the diagram as this one:
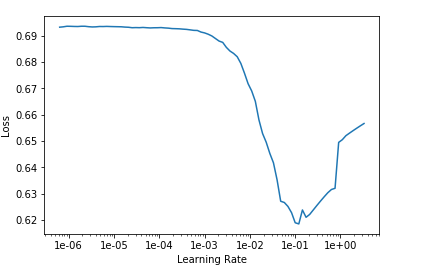
It shows up (empirically) that the best learning rate is a value that is approximately in the middle of the sharpest downward slope.
However, the modern practice is to alter the learning rate while training described in here.
At the end you would probable do learning rate annealing.

[first image is the learning rate second is the momentum in time]
It really depends on optimization algorithm but the techniques from fastai work well on Adam and SGD.
Lastly some newer optimizer algorithms don’t even care about the learning rate ;).
11 Likes
Thanks for your help.
I have thought about it for a long time and got the following questions.
There is actually a guy called Leslie N. Smith who created this paper .
-
But in the paper, there is only graph, which learning rate as the x-axis, and accuracy rate as the y-axis. Not like the graph you mentioned, why is the reason?
-
And at the stage of Choose a good learning rate, there is Sylvain Gugger’s post explaining how the learning rate finder works:
Over an epoch begin your SGD with a very low learning rate (like 10−810−8) but change it (by multiplying it by a certain factor for instance) at each mini-batch until it reaches a very high value (like 1 or 10). Record the loss each time at each iteration and once you’re finished, plot those losses against the learning rate.
My question about here is:
-
if change it (by multiplying it by a certain factor for instance) at each mini-batch,
the change of loss will because of: 1. input data(each mini-batch data is different); 2. learning rate.
How can we make sure the change of loss is just because of learning rate? -
during the learning rate finder working, will the weights in the model be updated?
If yes, The loss value will become smaller because of the model learning itself.
How can we know the change of loss is because of learning rate but not model learning itself? -
What is the value of loss in learning rate finder? Is just the average of the model output nodes?
I also asked here, but I’m not sure if I can get an answer.
1 Like
The paper L. Smith created did some things premature because he had a trip, and no enough time to polish the paper. I think this was the main reason.
I think measuring loss is better adoption in here. These are two antipodes, If loss is small the accuracy big, and opposite. If one goes up, the other goes down like so:

Sylvain Gugger’s post was an early version of the algorithm, since then they adopted it a bit (they are using hooks now), but the principles are the same.
One of the rules S. Googer explained:
The first one is that we won’t really plot the loss of each mini-batch, but some smoother version of it.
So how to make it smooth? They used exponentially weighed averages.
This is the same what people do to predict stocks. EWA works as a filter and you basically use lerp in PyTorch to calc this.
PS. The original version of the algorithm doesn’t use lerp though.
during the learning rate finder working, will the weights in the model be updated?
If yes, The loss value will become smaller because of the model learning itself.
How can we know the change of loss is because of learning rate but not model learning itself?
They save the model and then reload the initial state when done, check the on_train_end.
class LRFinder(LearnerCallback):
"Causes `learn` to go on a mock training from `start_lr` to `end_lr` for `num_it` iterations."
def __init__(self, learn:Learner, start_lr:float=1e-7, end_lr:float=10, num_it:int=100, stop_div:bool=True):
super().__init__(learn)
self.data,self.stop_div = learn.data,stop_div
self.sched = Scheduler((start_lr, end_lr), num_it, annealing_exp)
def on_train_begin(self, pbar, **kwargs:Any)->None:
"Initialize optimizer and learner hyperparameters."
setattr(pbar, 'clean_on_interrupt', True)
self.learn.save('tmp')
self.opt = self.learn.opt
self.opt.lr = self.sched.start
self.stop,self.best_loss = False,0.
return {'skip_validate': True}
def on_batch_end(self, iteration:int, smooth_loss:TensorOrNumber, **kwargs:Any)->None:
"Determine if loss has runaway and we should stop."
if iteration==0 or smooth_loss < self.best_loss: self.best_loss = smooth_loss
self.opt.lr = self.sched.step()
if self.sched.is_done or (self.stop_div and (smooth_loss > 4*self.best_loss or torch.isnan(smooth_loss))):
#We use the smoothed loss to decide on the stopping since it's less shaky.
return {'stop_epoch': True, 'stop_training': True}
def on_train_end(self, **kwargs:Any)->None:
"Cleanup learn model weights disturbed during LRFinder exploration."
self.learn.load('tmp', purge=False)
if hasattr(self.learn.model, 'reset'): self.learn.model.reset()
for cb in self.callbacks:
if hasattr(cb, 'reset'): cb.reset()
print('LR Finder is complete, type {learner_name}.recorder.plot() to see the graph.')
if change it (by multiplying it by a certain factor for instance) at each mini-batch ,
the change of loss will because of: 1. input data(each mini-batch data is different); 2. learning rate.
How can we make sure the change of loss is just because of learning rate?
Well, what is loss in PyTorch. It is a tensor representing a scalar value.
You can write it as: loss = loss_fn(y_hat, y) where loss_fn is also know as criterion, y_hat is know as output and y is know as target. So:
loss = criterion(output, target)
But most importantly it is one batch loss.
So the most primitive LR finder may work just on a same batch. First one you take from DataLoader.
However, these batch data is very close if you check std and mean, particularly if the batch size is large enough, so I think this is the reason to slide trough batches as S. Googer wrote in algorithm.
1 Like
The paper L. Smith created did some things premature because he had a trip, and no enough time to polish the paper. I think this was the main reason.
Ok…
I think measuring loss is better adoption in here.
Yes, maybe it’s something like when training the model, it is better to observe the loss value.
They save the model and then reload the initial state when done, check the
on_train_end.
So that means no updating for the weights in the model, during the learning rate finder working, Is it right?
However, these batch data is very close if you check std and mean, particularly if the batch size is large enough, so I think this is the reason to slide trough batches as S. Googer wrote in algorithm.
I did not verify with my own model and input data.
But that, these batch data is very close if you check std and mean, particularly if the batch size is large enough, may be right.
1 Like
No, the weights are updated in the algorithm you can see this from the :
loss.backward()
optimizer.step()
part of the algorithm S. Googer created.
However, I am not saying it is not possible to create LR finder even without updating the weights, but this would not be one cycle learning paper.
I did not verify with my own model and input data.
Yeah, good point. We need to check everything, else we don’t know anything.
You may try this exact S. Googer algorithm from his article, but just instead go trough different batches, try on a single (first) batch.
Hope you will get more feedback from the fastai blog.
1 Like
No, the weights are updated in the algorithm
Thanks… I understand it wrong.![]()
part of the algorithm S. Googer created.
However, I am not saying it is not possible to create LR finder even without updating the weights, but this would not be one cycle learning paper.
I got it. Maybe can do some research on this part.![]()
Hope you will get more feedback from the fastai blog.
Thanks for your reply and help for me so many times.![]()
![]()
1 Like
Hi @shirui-japina I wrote a blog post which might provide a bit more insight on picking learning rates, hope it helps: http://www.bdhammel.com/learning-rates/
TL;DR: Just use the learning rate finder.
For even more in-depth understanding, I strongly recommend giving this blog post a read:
in particular, post #5 on hyperparameters