Hi, currently I am trying to get the gradient of the neural network in terms of input (hoping to find the optimal input from the trained model). I have read some posts, such as [How to get "image gradient" in PyTorch?], which pointed out ‘requires_grad = True’ would automatically store the gradient and the gradient can be seen from ‘.grad’ field. However, my problem is a little different from their setting.
First, I need to train the neural network based on the given input datasets. Once the parameters of the network are determined, then I load the trained model to calcualte the gradient with respect to input (32 features), part of the codes are shown as follows:
model = Net()
model.load_state_dict(torch.load('model.pkl'))
bat_size = 3
loss_func = torch.nn.MSELoss() # mean squared error
n_items = len(training_x)
batches_per_epoch = n_items // bat_size
gradient_input = np.zeros(32)
for b in range(batches_per_epoch):
curr_bat = np.random.choice(n_items, bat_size, replace=False)
X = torch.Tensor(training_x[curr_bat])
X.requires_grad_(True)
Y = torch.Tensor(training_y[curr_bat]).view(bat_size,1)
print(X.grad) ## print None
oupt = model(X)
loss_obj = loss_func(oupt, Y)
loss_obj.backward()
print(X.grad) ## it gives me all zeros?
gradient_input = np.add(np.mean(X.grad.numpy(), axis = 0), gradient_input) ## get the average of gradient of all training samples.
where the ‘Net()’ is a neural network structure defined as:
class Net(torch.nn.Module):
def __init__(self):
super(Net, self).__init__()
self.hid1 = torch.nn.Linear(32, 20)
self.hid2 = torch.nn.Linear(20, 10)
self.oupt = torch.nn.Linear(10, 1)
torch.nn.init.xavier_uniform_(self.hid1.weight) # glorot
torch.nn.init.zeros_(self.hid1.bias)
torch.nn.init.xavier_uniform_(self.hid2.weight)
torch.nn.init.zeros_(self.hid2.bias)
torch.nn.init.xavier_uniform_(self.oupt.weight)
torch.nn.init.zeros_(self.oupt.bias)
def forward(self, x):
z = torch.tanh(self.hid1(x))
z = torch.tanh(self.hid2(z))
z = self.oupt(z) # no activation, aka Identity()
return z
When I run my codes, it gives me no errors, but the X.grad are always zeros.
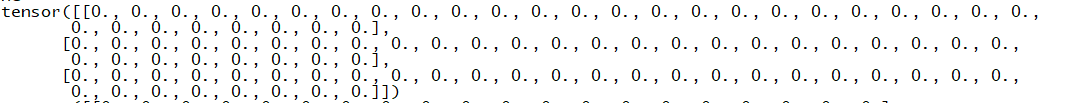
I would really appreciate if someone could give me some suggestions on debugging this issue.