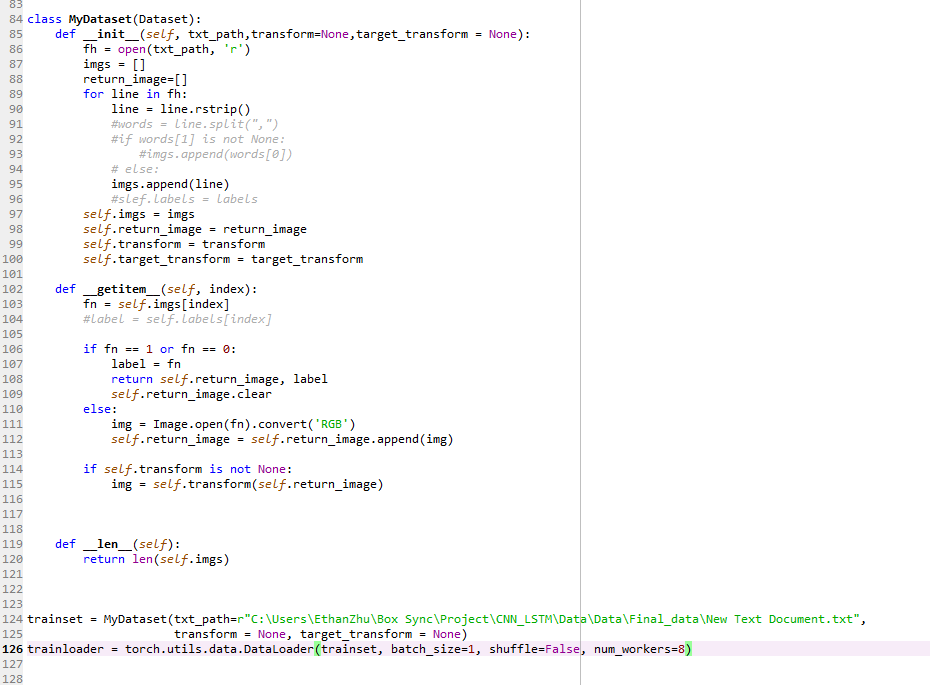
I have a lot of images data and I am trying to pack 8 images with 1 label interactively. After that, I will feed the data into the neural network accordingly. But I’m unable to extract the images from my customized Dataset(). Here is my code below
Yes there sure is Instead of having imgs as a list, try having it as a deafultdict where the key is the index, and value is a list of images. But, you might want to rethink this a bit. The txt_path is just 8 images and one label right? You have several of these files I suppose? Then you want to put them all in the dataset, no?
This code should get you started.
from collections import defaultdict
dict_imgs = defaultdict(list)
with open(txt_path) as f:
lines = f.read().splitlines()
dict_imgs[0] = lines # dictimgs will contain 8 image paths & one label
I rethinked a little bit about it and I changed the format of the paths in the text file. Basically, I just put all 8 file paths in one line and separate them with a comma and put the label in the end. It looks like this:
To help you figure out the torch.cat stuff, do some printouts before and after the cat.
print(img1.shape)
print(img2.shape)
In this case I can see that your code is missing a parenthesis. It should be img2 = torch.cat((img1,img2)). Just a heads up, if you do a batch size with more than 1, you will probably want to write a custom collate function, just fyi
 Instead of having imgs as a list, try having it as a deafultdict where the key is the index, and value is a list of images. But, you might want to rethink this a bit. The txt_path is just 8 images and one label right? You have several of these files I suppose? Then you want to put them all in the dataset, no?
Instead of having imgs as a list, try having it as a deafultdict where the key is the index, and value is a list of images. But, you might want to rethink this a bit. The txt_path is just 8 images and one label right? You have several of these files I suppose? Then you want to put them all in the dataset, no?