Hi,
I have trained my model using GPU. Now I want to run inference using CPU from my local machine. But I got two different outputs with the same input and same model. I already checked all the weights and biases of every layer in my model when loading on GPU vs CPU and they are exactly the same. What might be the problem?
Below I reproduce my implementation:
The model architecture is:
FCNs(
(pretrained_net): VGGNet(
(features): Sequential(
(0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU(inplace)
(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): ReLU(inplace)
(4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(5): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(6): ReLU(inplace)
(7): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(8): ReLU(inplace)
(9): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(10): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(11): ReLU(inplace)
(12): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(13): ReLU(inplace)
(14): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(15): ReLU(inplace)
(16): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(17): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(18): ReLU(inplace)
(19): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(20): ReLU(inplace)
(21): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(22): ReLU(inplace)
(23): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(24): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(25): ReLU(inplace)
(26): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(27): ReLU(inplace)
(28): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(29): ReLU(inplace)
(30): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(avgpool): AdaptiveAvgPool2d(output_size=(7, 7))
)
(relu): ReLU(inplace)
(deconv1): ConvTranspose2d(512, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), output_padding=(1, 1))
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(deconv2): ConvTranspose2d(512, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), output_padding=(1, 1))
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(deconv3): ConvTranspose2d(256, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), output_padding=(1, 1))
(bn3): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(deconv4): ConvTranspose2d(128, 64, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), output_padding=(1, 1))
(bn4): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(deconv5): ConvTranspose2d(64, 32, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), output_padding=(1, 1))
(bn5): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(classifier): Conv2d(32, 2, kernel_size=(1, 1), stride=(1, 1))
)
Initialize model:
vgg_model = VGGNet(requires_grad=False)
fcn_model = FCNs(pretrained_net=vgg_model, n_class=2)
Loading the model from checkpoint file on GPU:
fcn_model.load_state_dict(torch.load('path_to_checkpoint_file'))
fcn_model.to(torch.device("cuda:0"))
Loading the model from checkpoint file on CPU:
fcn_model.load_state_dict(torch.load('path_to_checkpoint_file', map_location=torch.device("cpu")))
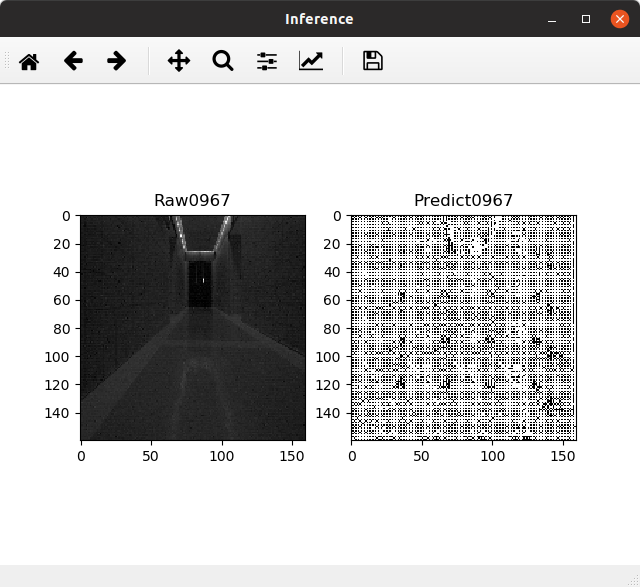
Result after running inference on GPU (correct result):
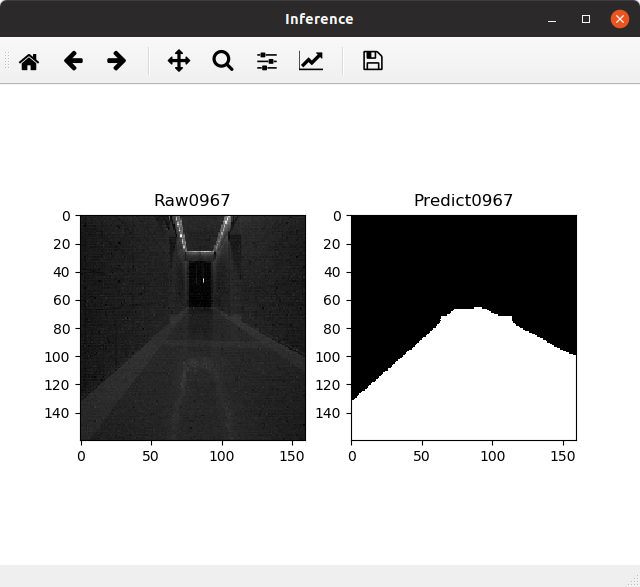
Result after running inference on CPU (incorrect result):
in the comment section. Sorry I cannot embed more than one image at this time
Then I thought what if I manually do the computation using the learned parameters from my pre-trained model. I extracted the learned parameters from the very first layer of my model (a Conv2d layer) using:
features_0 = fcn_model.pretrained_net.features[0]
Then I manually performed the 2d convolution using:
intermediate_output = features_0(input)
The above line of code gave two different results on GPU vs CPU, hence I supposed thing was wrong from here. I’ll copy partial outputs from both of them below for reference:
- On GPU:
tensor([[[[-0.2016, 0.3093, 0.3351, ..., 0.3285, 0.4559, 0.9779],
[-0.4843, 0.2606, 0.3323, ..., 0.2836, 0.3424, 1.1509],
[-0.4700, 0.2490, 0.2797, ..., 0.3783, 0.3949, 1.2118],
...,
[-1.1802, 0.2835, 0.2135, ..., 0.3620, 0.3109, 1.6714],
[-1.1745, 0.2435, 0.2224, ..., 0.3399, 0.2948, 1.6283],
[-1.0869, -0.1562, -0.1577, ..., -0.0661, -0.1139, 0.8225]],
[[-3.6574, -0.0526, 0.0080, ..., -0.0518, -0.0092, 3.2213],
[-3.3878, 0.4641, 0.5140, ..., 0.4185, 0.4046, 4.0703],
[-3.3437, 0.4760, 0.5175, ..., 0.4995, 0.3719, 3.9881],
...,
[-2.7212, 0.3976, 0.3944, ..., 0.3914, 0.3778, 3.6903],
[-2.7968, 0.3921, 0.4078, ..., 0.3579, 0.3871, 3.7424],
[-0.0957, 2.3573, 2.3298, ..., 2.4258, 2.4754, 4.5567]],
[[ 2.5700, 3.7657, 3.7913, ..., 3.6274, 3.7048, 6.2832],
[ 0.4378, 0.3566, 0.4138, ..., 0.4373, 0.3591, 2.5253],
[ 0.4370, 0.3188, 0.3944, ..., 0.3619, 0.3539, 2.4210],
...,
[ 0.2449, 0.3636, 0.3329, ..., 0.2692, 0.3070, 2.4730],
[ 0.2143, 0.2934, 0.2797, ..., 0.3979, 0.3467, 2.5309],
[ 0.7306, 0.6692, 0.6219, ..., 0.6413, 0.7033, 1.3527]],
...,
- On CPU:
tensor([[[[-0.4159, -1.3772, -1.3416, ..., -1.2730, -1.3515, -1.2631],
[-2.0944, -2.3655, -2.4092, ..., -2.3181, -2.3037, -2.0000],
[-2.0807, -2.4129, -2.3905, ..., -2.3652, -2.2306, -2.1509],
...,
[-1.9574, -2.0659, -2.0698, ..., -2.2020, -2.2160, -1.9520],
[-1.9367, -2.0827, -2.0875, ..., -2.2003, -2.1830, -1.9771],
[-2.0715, -1.6564, -1.6758, ..., -1.8386, -1.7863, -1.5557]],
[[-0.3932, -2.7367, -2.7323, ..., -2.5983, -2.6812, -3.0192],
[ 0.2744, -2.9499, -2.9782, ..., -2.7598, -2.8371, -3.6151],
[ 0.2419, -2.8837, -2.9761, ..., -2.8423, -2.8306, -3.6625],
...,
[ 0.2423, -2.6376, -2.6443, ..., -2.8489, -2.8633, -3.3964],
[ 0.2293, -2.6639, -2.6504, ..., -2.8309, -2.8116, -3.4940],
[ 0.8327, -0.8394, -0.8547, ..., -0.9290, -0.8949, -1.6848]],
[[ 0.9653, -0.9997, -1.0080, ..., -0.9294, -0.9508, -1.8505],
[ 1.6886, -1.7326, -1.7481, ..., -1.6317, -1.6249, -3.0301],
[ 1.6722, -1.6812, -1.7285, ..., -1.6332, -1.6878, -2.8707],
...,
[ 1.5246, -1.5172, -1.5334, ..., -1.6433, -1.6948, -2.7261],
[ 1.4972, -1.5355, -1.5414, ..., -1.6559, -1.6186, -2.8281],
[ 1.2256, -0.8062, -0.8274, ..., -0.9059, -0.9693, -1.7866]],
...,
Have you ever experienced this type of problem? If you need more details please let me know in the comment.
Thanks.
P/S: I added below toy example for the sake of simplicity. In short: I define the model on GPU, run inference and save it to a checkpoint file. I then load the saved model on CPU and run inference. The results from running inference on GPU vs CPU are totally different. What is wrong with my implementation?
My code:
import torch
from torch.autograd import Variable
import torch.nn.functional as F
torch.manual_seed(0)
class SimpleCNN(torch.nn.Module):
# Our batch shape for input x is (3, 8, 8)
def __init__(self):
super(SimpleCNN, self).__init__()
# Input channels = 3, output channels = 5
self.conv1 = torch.nn.Conv2d(3, 5, kernel_size=3, stride=1, padding=1)
self.pool = torch.nn.MaxPool2d(kernel_size=2, stride=2, padding=0)
# 80 input features, 64 output features (see sizing flow below)
self.fc1 = torch.nn.Linear(5 * 4 * 4, 64)
# 64 input features, 10 output features for our 10 defined classes
self.fc2 = torch.nn.Linear(64, 10)
def forward(self, x):
# Computes the activation of the first convolution
# Size changes from (3, 8, 8) to (5, 8, 8)
x = F.relu(self.conv1(x))
# Size changes from (5, 8, 8) to (5, 4, 4)
x = self.pool(x)
# Reshape data to input to the input layer of the neural net
# Size changes from (18, 4, 4) to (1, 288)
# Recall that the -1 infers this dimension from the other given dimension
x = x.view(-1, 5 * 4 * 4)
# Computes the activation of the first fully connected layer
# Size changes from (1, 4608) to (1, 64)
x = F.relu(self.fc1(x))
# Computes the second fully connected layer (activation applied later)
# Size changes from (1, 64) to (1, 10)
x = self.fc2(x)
return x
device = torch.device("cuda:0")
# device = torch.device("cpu")
# Define model on GPU
input = torch.randn(1, 3, 8, 8).to(device)
model = SimpleCNN().to(device)
conv1 = model.conv1
# print(model)
hook_output = []
def hook(module, input, output):
hook_output.append(output)
model.conv1.register_forward_hook(hook)
output = model(input)
print('Inference on GPU:')
print(output)
print('---')
torch.save(model.state_dict(), 'checkpoint.pt')
# Load saved model on CPU
device = torch.device("cpu")
new_model = SimpleCNN().to(device)
new_model.load_state_dict((torch.load('checkpoint.pt', map_location=device)))
input_copy = input.to(device)
new_output = new_model(input_copy)
print('Inference on CPU:')
print(new_output)
The output I got:
Inference on GPU:
tensor([[-0.0408, -0.0669, -0.0144, 0.0019, -0.1035, 0.2304, -0.0975, -0.2048,
0.3898, -0.1991]], device='cuda:0', grad_fn=<AddmmBackward>)
---
Inference on CPU:
tensor([[-0.0933, -0.0387, 0.0008, 0.0345, -0.0352, 0.1660, -0.1225, -0.2593,
0.4289, -0.1703]], grad_fn=<AddmmBackward>)