If I use different weights for the same network, the forward pass speeds are very different. One takes around 0.017s the other takes 0.6s I am unsure why this is happening. Both the weights file have the same size (101M).
The first one is provided by author of a repository, while the other is just retrained. So I am guessing the pytorch version while saving the first model would have been different. So I am wondering if there is anything extra that needs to be done while using torch.save in pytorch 1.0
How do you time your code? Is it the CPU or GPU time?
Are you using exactly the same code and just swap the weights?
If so, could you provide these weights, so that we could try to replicate this issue?
I simply downloaded VOC2007, and VOC2012, extracted them and then create a symlink to the VOCdevkit in the folder data/ after setting up VOC dataset. I think there is should be an easier approach, but that would require a bit more changes to the code so I have not done that.
Thanks for the information.
Something seems to be strange in your current code.
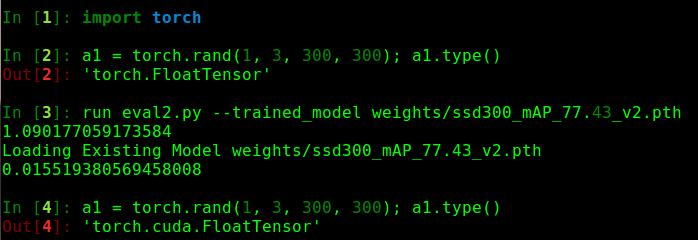
It seems you are pushing the model to the GPU, but are passing CPU tensors.
Is it a typo in the posted code or am I missing something, e.g. a push to the device in the forward method?
Also, if you are trying to time CUDA calls, note that they are asynchronous.
That means you should call torch.cuda.synchronize() before starting and stopping the timer.
Could you add these lines of code and time it again? I would just want to make sure it’s not a timing issue.
The default type is set at the beginning of the script, so that should be alright,
It’s sometimes hard to tell which operations are still being executed in the background and might therefore influence the timing. Apparently, the synch calls do not change anything.
Do you see the same speed difference on the CPU or just using the GPU?
I also tried to do a full run of eval.py. The evaluation for the pretrained networks takes around 15 mins, while the other one takes more than 2 hours.
Sorry for the late reply. I’ve reproduced the timing issue, profiled your code using torch.utils.bottleneck, and it seems run with random weights just performs a lot more calls to layers/box_utils.py.
It’s a guess as I’m not familiar with the code, but I think the random weights just might create a lot of more detection candidates which are evaluated one after the other.
Could you confirm the assumption?
You are absolutely correct. I didn’t realize that nms was being called in the forward method itself. nms contains a while loop, which is causing the time difference. Thank you.