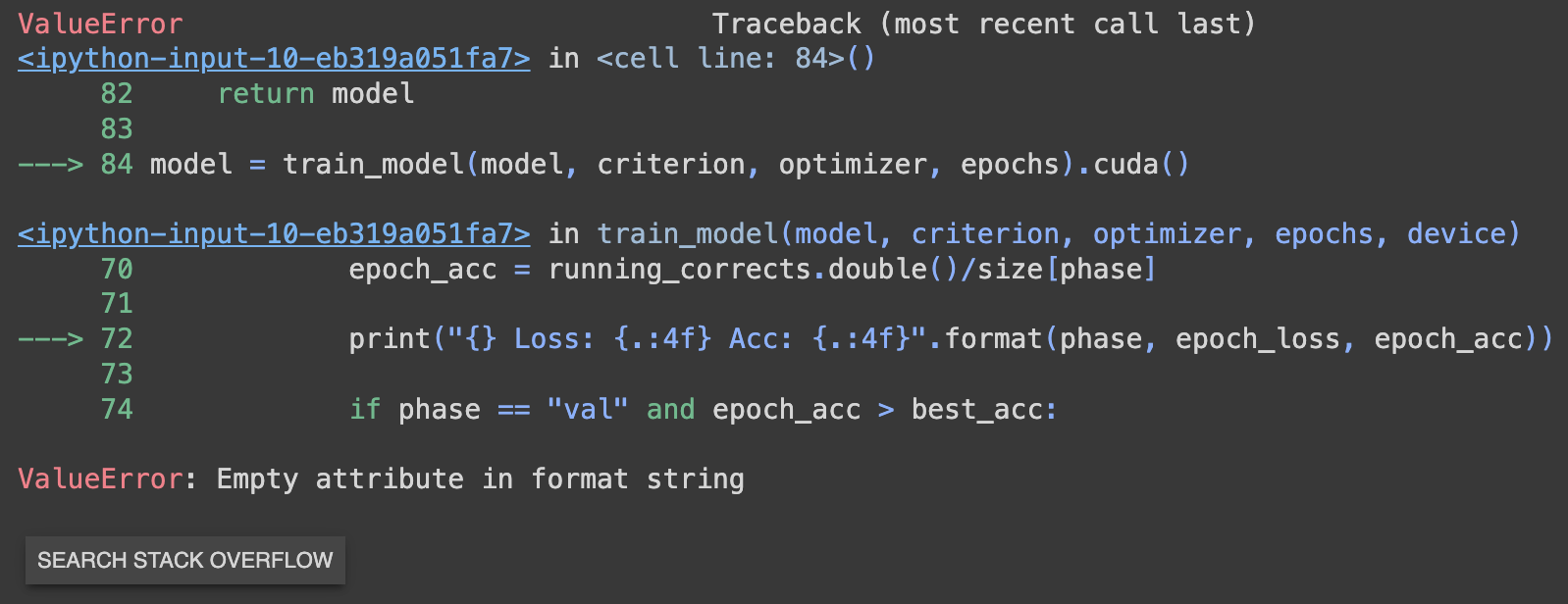
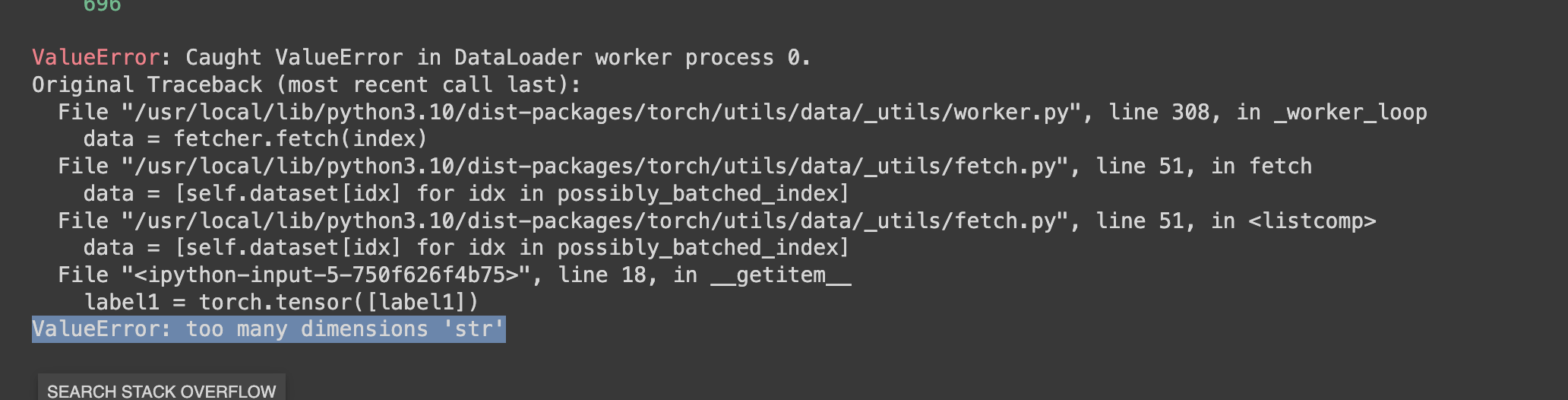
Hi Im training a model for classifying pneumonia detection images I developed a model that goes throgh the training loop once correctly but as soon as it goes through another epoch it starts to throw this error:
#Import math packages
import numpy as np
import os
import time
import copy
from glob import glob
import random
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.metrics import confusion_matrix
from sklearn.model_selection import train_test_split
from PIL import Image
#import pytorch packages
import torch
import torchvision
import torch.nn as nn
import torch.nn.functional as F
from torch.utils.data import DataLoader, Dataset
from torch.optim import Adam
from torchvision import datasets, transforms
from torchvision.utils import make_grid
from torchvision.models import resnet18, vgg16
from tqdm import tqdm
test_N = glob('/content/drive/MyDrive/chest_xray/test/NORMAL/*')
test_P = glob('/content/drive/MyDrive/chest_xray/test/PNEUMONIA/*')
train_N = glob('/content/drive/MyDrive/chest_xray/train/NORMAL/*')
train_P = glob('/content/drive/MyDrive/chest_xray/train/PNEUMONIA/*')
train_paths = train_N + train_P
test_paths = test_N + test_P
train_labels = [0] * len(train_N) + [1] * len(train_P)
test_labels = [0] * len(test_N) + [1] * len(test_P)
print(len(train_paths),len(train_labels))
print(len(test_paths),len(test_labels))
from google.colab import drive
drive.mount('/content/drive')
train_paths, valid_paths, train_labels, valid_labels = train_test_split(train_paths,
train_labels,
stratify=train_labels)
def imShowRandom():
path_random_normal = random.choice(train_N)
path_random_abnormal = random.choice(train_P)
fig = plt.figure(figsize=(10,10))
ax1 = plt.subplot(1,2,1)
ax1.imshow(Image.open(path_random_normal).convert("LA"))
ax1.set_title("Normal X-Ray")
ax2 = plt.subplot(1,2,2)
ax2.imshow(Image.open(path_random_abnormal).convert("LA"))
ax2.set_title("Pneumonia X-Ray")
imShowRandom()
class ModifySet(Dataset):
def __init__(self,paths,labels, transform=None):
self.paths = paths
self.labels = labels
self.transform = transform
def __len__(self):
return len(self.paths)
def __getitem__(self, index):
path = self.paths[index]
image = Image.open(path).convert("RGB")
if self.transform:
image = self.transform(image)
label1 = self.labels[index]
label1 = torch.tensor([label1])
return image, label1
class PneuModel(nn.Module):
def __init__(self, pretrained = True):
super(PneuModel, self).__init__()
self.x = resnet18(pretrained = pretrained)
self.fc = nn.Linear(in_features=512, out_features = 1)
def forward(self, x):
x = self.x.conv1(x)
x = self.x.bn1(x)
x = self.x.relu(x)
x = self.x.maxpool(x)
x = self.x.layer1(x)
x = self.x.layer2(x)
x = self.x.layer3(x)
x = self.x.layer4(x)
x = self.x.avgpool(x)
x.view(x.size(0),512)
x = nn.Flatten(1, -1)(x)
x = self.fc(x)
return x
image_size = (500,500)
train_transforms = transforms.Compose([
transforms.ToTensor(),
transforms.Resize(size = image_size),
transforms.Normalize([0.458,0.456,0.406], [0.229,0.224,0.225]),
])
test_transforms = transforms.Compose([
transforms.ToTensor(),
transforms.Resize(size = image_size),
transforms.Normalize([0.458,0.456,0.406], [0.229,0.224,0.225]),
])
train_ds = ModifySet(train_paths, train_labels, train_transforms)
val_ds = ModifySet(test_paths, test_paths, test_transforms)
model = PneuModel(pretrained = True)
epochs = 5
b_size = 15
train_dl = DataLoader(train_ds, batch_size=b_size,num_workers=5,shuffle=True)
val_dl = DataLoader(val_ds, batch_size = b_size, num_workers=5, shuffle = False)
dataloaders = {
'train': train_dl,
'val': val_dl
}
logging = {
'train': len(dataloaders["train"])//10,
'val': len(dataloaders["val"])//10
}
size = {
'train': len(train_ds),
'val': len(val_ds)
}
criterion = nn.BCEWithLogitsLoss()
optimizer = Adam(model.parameters(),lr = 3e-3)
def train_model(model, criterion, optimizer, epochs, device="cpu"):
start = time.time()
best_model_wts = copy.deepcopy(model.state_dict())
best_acc = 0
for epoch in tqdm(range(epochs),leave=False):
for phase in ["train","val"]:
if phase == "train":
model.train()
else:
model.eval()
running_loss = 0.0
running_corrects = 0
for i, (inputs, labels) in tqdm(enumerate(dataloaders[phase]), leave=False, total = len(dataloaders[phase])):
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
inputs = inputs.to(device)
labels = labels.to(device)
optimizer.zero_grad()
with torch.set_grad_enabled(phase == "train"):
outputs = model(inputs)
preds = outputs.sigmoid() > 0.5
loss = criterion(outputs, labels.float())
if phase == "train":
loss.backward()
optimizer.step()
running_loss += loss.item() * inputs.size(0)
running_corrects += torch.sum(preds == labels.data)
if(i % logging[phase] ==0) & (i > 0):
avg_loss = running_loss/ ((i+1)*16)
avg_corrects = running_corrects/ ((i+1)*16)
print(f"[{phase}]: {epoch+1}/{epochs} | loss: {avg_loss} | acc: {avg_corrects}")
epoch_loss = running_loss/size[phase]
epoch_acc = running_corrects.double()/size[phase]
print(f'Loss: {epoch_loss} Acc: {epoch_acc}')
if phase == "val" and epoch_acc > best_acc:
best_acc = epoch_acc
best_model_wts = copy.deepcopy(model.state_dict())
print()
time_pass = time.time()-start
print("Training took {} seconds".format(time_pass))
model.state_dict(best_model_wts)
return model
model = train_model(model, criterion, optimizer, epochs)