while I am going to train my transfer learning model I am getting this error .

I am using CIFAR-10 dataset for my training purpose for implementing the ResNet101*3 from scratch
data_transforms = {
'train': transforms.Compose([
transforms.ToTensor(),
transforms.RandomHorizontalFlip(0.5),
transforms.RandomVerticalFlip(0.5),
transforms.Resize(448),
transforms.CenterCrop(384),
]),
'val': transforms.Compose([
transforms.ToTensor(),
transforms.RandomHorizontalFlip(0.5),
transforms.RandomVerticalFlip(0.5),
transforms.Resize(448),
transforms.CenterCrop(384),
]),
}
trainset = torchvision.datasets.CIFAR10(root=‘./data’ , train=True,
download=True , transform = data_transforms)
testset = torchvision.datasets.CIFAR10(root=‘./data’ , train=False,
download=True , transform = data_transforms)
data_generator = {‘train’ : trainset,‘val’: testset}
data_loader = {k: torch.utils.data.DataLoader(data_generator[k], batch_size=512,
shuffle=True, num_workers=0) for k in ['train' , 'val']}
classes = (‘plane’, ‘car’, ‘bird’, ‘cat’,
'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
in the data_loader variable ; I have converted the dataset to pytorch data_loader
data_loader = {k: torch.utils.data.DataLoader(data_generator[k], batch_size=512,
shuffle=True, num_workers=0) for k in ['train' , 'val']}
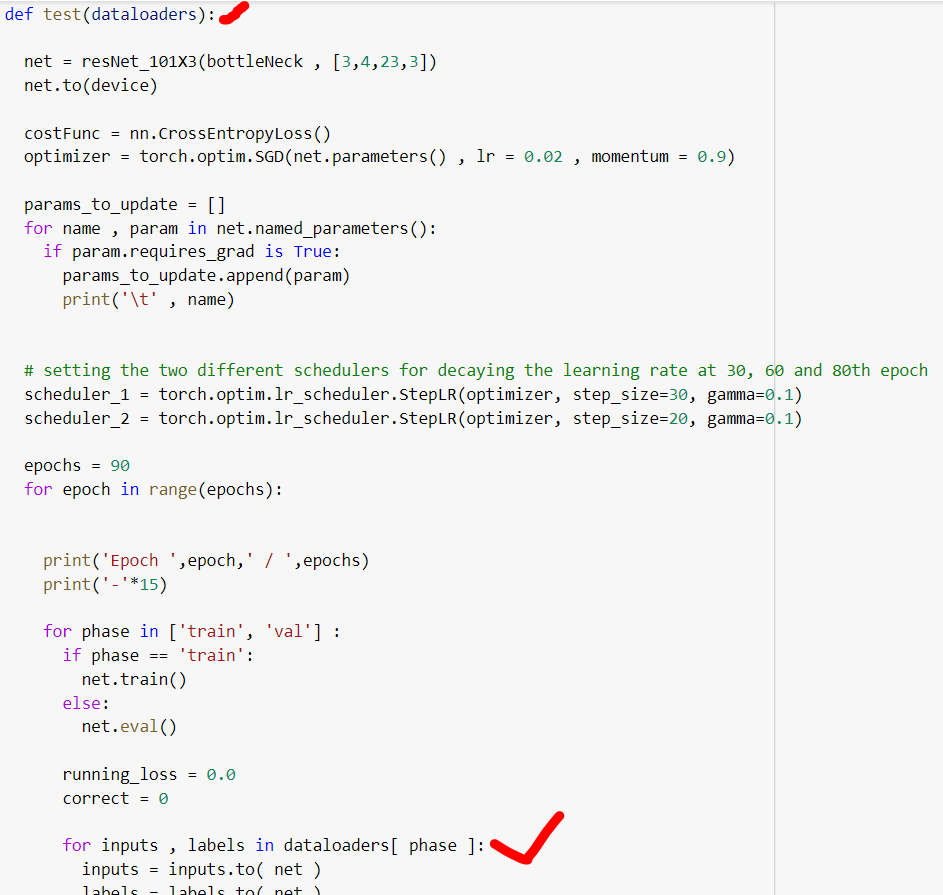
After that I have used it in training method here .
def test(dataloaders):
net = resNet_101X3(bottleNeck , [3,4,23,3])
net.to(device)
costFunc = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(net.parameters() , lr = 0.02 , momentum = 0.9)
params_to_update =
for name , param in net.named_parameters():
if param.requires_grad is True:
params_to_update.append(param)
print('\t' , name)
setting the two different schedulers for decaying the learning rate at 30, 60 and 80th epoch
scheduler_1 = torch.optim.lr_scheduler.StepLR(optimizer, step_size=30, gamma=0.1)
scheduler_2 = torch.optim.lr_scheduler.StepLR(optimizer, step_size=20, gamma=0.1)
epochs = 90
for epoch in range(epochs):
print('Epoch ',epoch,' / ',epochs)
print('-'*15)
for phase in ['train', 'val'] :
if phase == 'train':
net.train()
else:
net.eval()
running_loss = 0.0
correct = 0
**for inputs , labels in dataloaders[ phase ]:**
inputs = inputs.to( net )
labels = labels.to( net )
optimizer.zero_grad()
# we will use the gradients from only training mode not for validation mode
with torch.set_grad_enabled(phase == 'train'):
outputs = net(inputs)
loss = creterion(outputs , labels)
_ , preds = torch.max(outputs , 1)
if phase == 'train':
loss.backward()
optimizer.step()
running_loss += loss.item() * inputs.size(0)
correct += torch.sum(preds == labels.data)
epoch_loss = running_loss / len(data_loaders[phase].dataset )
epoch_acc = correct.double() / len(data_loaders[phase].dataset )
print(phase , " Loss: ", epoch_loss , " epoch_acc: " ,epoch_acc)
# decaying the learning rate by a factor of 10
if epoch <= 60:
scheduler_1.step()
else :
scheduler_2.step()
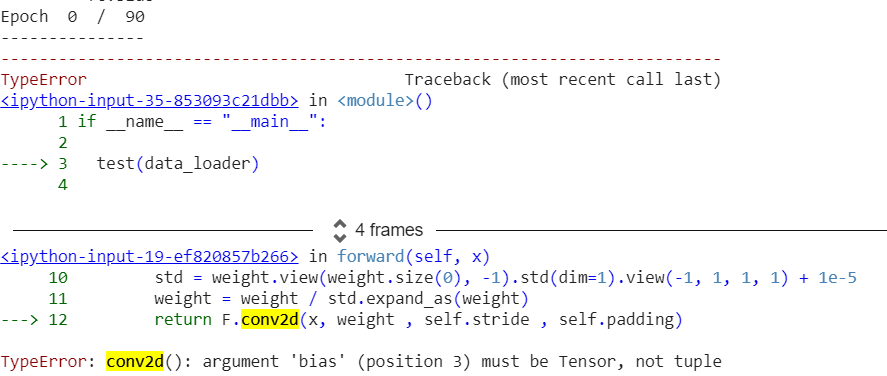
and when I am running this main function , I am getting the error
if __ name __ == “__ main __”:
test(data_loader)
please suggest @admins