Hi all!
I am trying to implement RankNet (learning to rank) algorithm in PyTorch from this paper:
https://www.microsoft.com/en-us/research/publication/from-ranknet-to-lambdarank-to-lambdamart-an-overview/
I have implemented a 2-layer neural network with RELU activation. I am using Adam optimizer, with a weight decay of 0.01.
I have written a custom loss function as mentioned in the paper. The details are as follows:
Loss/Cost function:
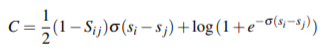
where,
For a given query, S_i j ∈ {0,±1}
S_ij = 1 if document i has been labeled to be more relevant than document j, −1 if document i has been labeled to be less relevant than document j, and 0 if they have the same label.
s_i and s_j are the predicted scores by the model for URLs URL_i and URL_j of a query.
Also, I have implemented the NDCG function as the evaluation metric of the learning to rank algorithm.
I am using the LETOR MQ2008 dataset, with 52k training samples.
# Loss function
def custom_loss_func(x_tr, y_tr):
#x_tr = predicted score by the model
#y_tr = true score
loss_mean = torch.tensor(0.0)
x_tr = torch.squeeze(x_tr)
for i in range(len(x_tr))[::2]:
s_i = x_tr[i]
s_j = x_tr[i+1]
s_ij_diff = s_i - s_j
true_i = y_tr[i]
true_j = y_tr[i+1]
if true_i > true_j:
S_ij = 1
elif true_i < true_j:
S_ij = -1
else:
S_ij = 0
loss = (1 - S_ij) * s_ij_diff / 2. + torch.log(1 + torch.exp(-s_ij_diff))
loss_mean += loss
loss_mean /= (len(x_tr)/2)
return loss_mean
# Define the evaluation metric: NDCG
def calc_ndcg(y_true, y_pred, k):
y_pred = torch.squeeze(y_pred, 1)
dcg = torch.tensor([0.])
ideal_dcg = torch.tensor([0.])
y_true_sorted, index_y_true = torch.sort(y_true, descending=True)
y_pred_sorted, index_y_pred = torch.sort(y_pred, descending=True)
for i in range(k):
ideal_dcg += (torch.tensor(2.) ** y_true_sorted[i] - torch.tensor(1.)) / torch.log2(torch.tensor(i) + torch.tensor(2.))
for i in range(k):
dcg += (torch.tensor(2.) ** y_true[index_y_pred[i]] - torch.tensor(1.)) / torch.log2(torch.tensor(i) + torch.tensor(2.))
ndcg = dcg / ideal_dcg
return ndcg
# Main
for epoch in range(epochs):
#model.train()
running_loss = 0.0
for i, each_batch in enumerate(pairs_dl, start=0):
xb, yb = get_train_batch(each_batch)
pred = model(xb)
loss = custom_loss_func(pred, yb)
running_loss += loss
opt.zero_grad()
loss.backward()
opt.step()
avg_loss = running_loss / (i+1)
print('[%d, %5d] loss: %.10f' % (epoch + 1, i + 1, avg_loss))
running_loss = 0.0
#model.eval()
with torch.no_grad():
y_pred_t = model(X_train_t)
ndcg_epoch = calc_ndcg(y_train_t, y_pred_t, 10)
Below are my results:
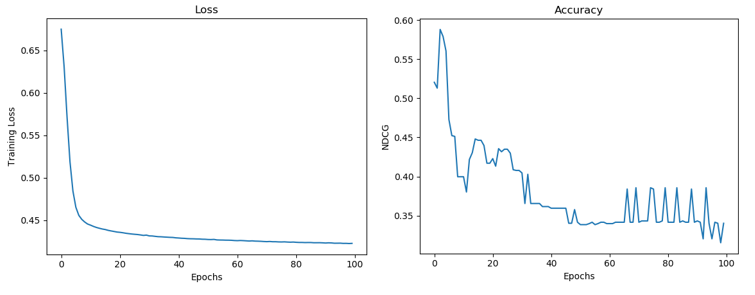
Number of hidden1 units 64
Number of hidden2 layer units 32
Number of epochs 100
Batch size 32
Learning rate 1e-05
NDCG k = 10
As from the figure, the training accuracy (NDCG) is fluctuating a lot and seems to be completely wrong. I have also tried this with different hyperparameter settings, altering the learning rate, batch size, number of layers, number of neurons.
Also tried on the validation set, and it gives errors in both loss and NDCG. So currently I am focusing on first getting the training accuracy right.
I am guessing somewhere in the loss or NDCG function I am making an error, or in the gradients, but not able to figure it out.
I am new to PyTorch and I would really appreciate any help on this. Thanks in advance.