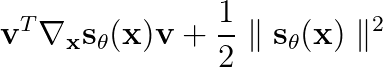Hi there! I am trying to use torch autograd to get the gradient of the output of a CNN, with respect to the input features. I can do this for a single batch element, but can’t see a way to do this for a batch of inputs.
We take some 28x28 data vector, pass it through a CNN that preserves the input shape, and then project this down to a single scalar using a dot product. I am trying to find the gradient of that scalar, with respect to the 28x28 input features. A simple example below:
import torch
import torch.nn as nn
import torch.nn.functional as F
torch.manual_seed(0)
# Here's a simple CNN:
class SimpleCNN(nn.Module):
def __init__(self):
super(SimpleCNN, self).__init__()
self.conv1 = nn.Conv2d(1, 32, 3, 1,padding="same")
self.conv2 = nn.Conv2d(32, 32, 3, 1,padding="same")
self.conv2 = nn.Conv2d(32, 1, 3, 1,padding="same")
def forward(self, x):
if len(x)<4: ## Enable processing of batch_size=1
x=x.unsqueeze(0)
x = self.conv1(x)
x = F.relu(x)
x = self.conv2(x)
x = F.relu(x)
return x
if torch.cuda.is_available():
print("CUDA Available")
device = torch.device('cuda')
else:
print('CUDA Not Available')
device = torch.device('cpu')
batch_size = 64
data = torch.randn(batch_size, 1, 28, 28, device=device,requires_grad=True)
vectors=torch.rand((batch_size,28*28),device=device,requires_grad=True)
model = SimpleCNN().to(device=device)
def get_single_grad(x,vector,model):
""" Get gradient of our dot product with respect to a single batch element """
y_single=model(x)
prod=torch.dot(y_single.view(28*28),vector)
grads=torch.autograd.grad(prod,x)[0]
return grads
We can get the grad of the dot product for each batch, by looping in the following way, which works:
%%time
single_grads=[]
for aa in range(len(data)):
grads=get_single_grad(data[aa],vectors[aa],model)
single_grads.append(grads)
## output:
#CPU times: user 14.8 ms, sys: 1.02 ms, total: 15.9 ms
#Wall time: 15.4 ms
But when I try and vmap this function over the batch dimension:
batched_grad=torch.func.vmap(get_single_grad,in_dims=(0,0,None))
batched_grad(data,vectors,model)
I get the error:
---------------------------------------------------------------------------
RuntimeError Traceback (most recent call last)
Input In [59], in <cell line: 2>()
1 batched_grad=torch.func.vmap(get_single_grad,in_dims=(0,0,None))
----> 2 batched_grad(data,vectors,model)
File /ext3/miniconda3/lib/python3.9/site-packages/torch/_functorch/apis.py:188, in vmap.<locals>.wrapped(*args, **kwargs)
187def wrapped(*args, **kwargs):
--> 188return vmap_impl(func, in_dims, out_dims, randomness, chunk_size, *args, **kwargs)
File /ext3/miniconda3/lib/python3.9/site-packages/torch/_functorch/vmap.py:278, in vmap_impl(func, in_dims, out_dims, randomness, chunk_size, *args, **kwargs)
274return _chunked_vmap(func, flat_in_dims, chunks_flat_args,
275 args_spec, out_dims, randomness, **kwargs)
277 # If chunk_size is not specified.
--> 278return _flat_vmap(
279 func, batch_size, flat_in_dims, flat_args, args_spec, out_dims, randomness, **kwargs
280 )
File /ext3/miniconda3/lib/python3.9/site-packages/torch/_functorch/vmap.py:44, in doesnt_support_saved_tensors_hooks.<locals>.fn(*args, **kwargs)
41 @functools.wraps(f)
42def fn(*args, **kwargs):
43with torch.autograd.graph.disable_saved_tensors_hooks(message):
---> 44return f(*args, **kwargs)
File /ext3/miniconda3/lib/python3.9/site-packages/torch/_functorch/vmap.py:391, in _flat_vmap(func, batch_size, flat_in_dims, flat_args, args_spec, out_dims, randomness, **kwargs)
389try:
390 batched_inputs = _create_batched_inputs(flat_in_dims, flat_args, vmap_level, args_spec)
--> 391 batched_outputs = func(*batched_inputs, **kwargs)
392return _unwrap_batched(batched_outputs, out_dims, vmap_level, batch_size, func)
393finally:
Input In [57], in get_single_grad(x, vector, model)
31 y_single=model(x)
32 prod=torch.dot(y_single.view(28*28),vector)
---> 33 grads=torch.autograd.grad(prod,x)[0]
34return grads
File /ext3/miniconda3/lib/python3.9/site-packages/torch/autograd/__init__.py:411, in grad(outputs, inputs, grad_outputs, retain_graph, create_graph, only_inputs, allow_unused, is_grads_batched, materialize_grads)
407 result = _vmap_internals._vmap(vjp, 0, 0, allow_none_pass_through=True)(
408 grad_outputs_
409 )
410else:
--> 411 result = Variable._execution_engine.run_backward( # Calls into the C++ engine to run the backward pass
412 t_outputs,
413 grad_outputs_,
414 retain_graph,
415 create_graph,
416 inputs,
417 allow_unused,
418 accumulate_grad=False,
419 ) # Calls into the C++ engine to run the backward pass
420if materialize_grads:
421if any(
422 result[i]isNoneandnot is_tensor_like(inputs[i])
423for iin range(len(inputs))
424 ):
RuntimeError: element 0 of tensors does not require grad and does not have a grad_fn
Given there are no issues with the single element grad, I’m guessing the dot product operation is not tracking gradients inside of vmap? Any insight/suggestions would be much appreciated.