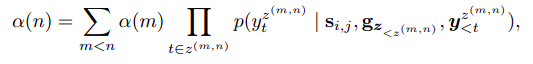I am pasting the code here, alternatively, the code and data can be cloned from here.
The model won’t work well for longer sequences as it takes the product of probabilities, however, I am getting the error even when I am testing on a smaller sequence length (say 5). If length is restricted on random input data then the error can be reproduced.
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchtext.datasets import TranslationDataset
from torchtext.data import Field, BucketIterator
import spacy
import numpy as np
import random
import math
import time
SEED = 1234
random.seed(SEED)
np.random.seed(SEED)
torch.manual_seed(SEED)
torch.cuda.manual_seed(SEED)
torch.backends.cudnn.deterministic = True
torch.autograd.set_detect_anomaly(True)
spacy_en = spacy.load('en')
def tokenize_en(text):
"""
Tokenizes English text from a string into a list of strings (tokens) and reverses it
"""
return [tok.text for tok in spacy_en.tokenizer(text)][::-1]
def tokenize_hi(text):
"""
Tokenizes Hindi text from a string into a list of strings (tokens)
"""
return text.split()
SRC = Field(tokenize = tokenize_en,
init_token = '<sos>',
eos_token = '<eos>',
lower = True)
TRG = Field(tokenize = tokenize_hi,
init_token = '<sos>',
eos_token = '<eos>',
lower = True)
train_data, valid_data, test_data = TranslationDataset.splits(
path='IITB_small',
validation='dev',
exts = ('.en', '.hi'),
fields = (SRC, TRG))
print(f"Number of training examples: {len(train_data.examples)}")
print(f"Number of validation examples: {len(valid_data.examples)}")
print(f"Number of testing examples: {len(test_data.examples)}")
vars(train_data.examples[0])
SRC.build_vocab(train_data, min_freq = 2)
TRG.build_vocab(train_data, min_freq = 2,specials=['<pad>','<sop>','<eop>'])
print(f"Unique tokens in source (en) vocabulary: {len(SRC.vocab)}")
print(f"Unique tokens in target (hi) vocabulary: {len(TRG.vocab)}")
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
device
BATCH_SIZE = 2
train_iterator, valid_iterator, test_iterator = BucketIterator.splits(
(train_data, valid_data, test_data),
batch_size = BATCH_SIZE,
device = device)
"""# EnCoder Parameters"""
input_dim = len(SRC.vocab)
embed_dim = 10
hidden_dim = 10
segment_dim = 10
n_layers = 6
dropout = 0.4
segment_threshold = 5
temperature = 0.1
"""# Building Encoder"""
class Encoder(nn.Module):
def __init__(self,input_dim,embed_dim,hidden_dim,segment_dim,n_layers,dropout,segment_threshold,device):
super().__init__()
self.input_dim = input_dim
self.hidden_dim = hidden_dim
self.n_layers = n_layers
self.segment_threshold = segment_threshold
self.segment_dim = segment_dim
self.device = device
self.embedding = nn.Embedding(input_dim,embed_dim)
self.rnn = nn.GRU(embed_dim,hidden_dim,n_layers,dropout=dropout,bidirectional=True)
self.segmentRnn = nn.GRU(hidden_dim*2,segment_dim,n_layers,dropout=dropout)
self.fc = nn.Linear(hidden_dim*2,hidden_dim)
self.dropout = nn.Dropout(dropout)
def forward(self,input):
#input = [src len, batch size]
embedded = self.dropout(self.embedding(input))
#embedded = [src len, batch size, emb dim]
outputs, hidden = self.rnn(embedded)
#outputs = [src len, batch size, hid dim * num directions]
#hidden = [n layers * num directions, batch size, hid dim]
segment_encoding, hidden = self.segment_rnn(outputs)
#segment_encoding = [src len* (src len+1)/2, batch size, segment_dim*num_directions]
#hidden = [n layers * num_directions, batch size, hid dim]
# hidden = torch.tanh(self.fc(torch.cat((hidden[-2],hidden[-1]),dim=1)))
return segment_encoding,hidden
def segment_rnn(self,outputs):
N = outputs.shape[0]
batch_size = outputs.shape[1]
dp_forward = torch.zeros(N, N, batch_size, self.segment_dim).to(self.device)
dp_backward = torch.zeros(N, N, batch_size, self.segment_dim).to(self.device)
for i in range(N):
hidden_forward = torch.randn(self.n_layers, batch_size, self.hidden_dim).to(self.device)
for j in range(i, min(N, i + self.segment_threshold)):
# outputs[j] = [batch size, hidden_dim* num_direction]
next_input = outputs[j].unsqueeze(0)
# next_input = [1, batch size, hidden_dim* num_direction]
out, hidden_forward = self.segmentRnn(next_input,hidden_forward)
#out = [1, batch size, segment_dim]
#hidden_forward = [n layers , batch size, hid dim]
dp_forward[i][j] = out.squeeze(0)
for i in range(N):
hidden_backward = torch.randn(self.n_layers, batch_size, self.hidden_dim).to(self.device)
for j in range(i, max(-1, i - self.segment_threshold), -1):
# outputs[j] = [batch size, hidden_dim* num_direction]
next_input = outputs[j].unsqueeze(0)
# next_input = [1, batch size, hidden_dim* num_direction]
out, hidden_backward = self.segmentRnn(next_input,hidden_backward)
#out = [1, batch size, segment_dim]
#hidden_backward = [n layers , batch size, hid dim]
dp_backward[j][i] = out.squeeze(0)
dp = torch.cat((dp_forward,dp_backward),dim=3)
dp_indices = torch.triu_indices(N, N)
dp = dp[dp_indices[0],dp_indices[1]]
return dp,torch.cat((hidden_forward,hidden_backward),dim=2)
"""# Defining Attn Network"""
'''
Attention is calculated over encoder_outputs S(i,j) and context representation
of previously generated segments (from Target Decoder)
'''
class Attention(nn.Module):
def __init__(self, enc_hid_dim, dec_hid_dim):
super().__init__()
self.attn = nn.Linear((enc_hid_dim * 2) + dec_hid_dim, dec_hid_dim)
self.v = nn.Linear(dec_hid_dim, 1, bias = False)
def forward(self, encoder_outputs, output_target_decoder):
#encoder_outputs = [no. of segments, batch size, enc hid dim * 2]
#output_target_decoder = [batch size, dec hid dim]
batch_size = encoder_outputs.shape[1]
src_len = encoder_outputs.shape[0]
#repeat decoder hidden state src_len times
output_target_decoder = output_target_decoder.unsqueeze(1).repeat(1, src_len, 1)
encoder_outputs = encoder_outputs.permute(1, 0, 2)
#output_target_decoder = [batch size, no. of segments, dec hid dim]
#encoder_outputs = [batch size, no. of segments, enc hid dim * 2]
energy = torch.tanh(self.attn(torch.cat((output_target_decoder, encoder_outputs), dim = 2)))
#energy = [batch size, no. of segments, dec hid dim]
attention = self.v(energy).squeeze(2)
#attention= [batch size, no. of segments]
a = F.softmax(attention, dim=1)
#a = [batch size, no. of segments]
a = a.unsqueeze(1)
#a = [batch size, 1, no. of segments]
weighted = torch.bmm(a, encoder_outputs)
#weighted = [batch size, 1, enc hid dim * 2]
weighted = weighted.permute(1, 0, 2)
#weighted = [1, batch size, enc hid dim * 2]
return weighted
"""# Decoder Parameters"""
output_dim = len(TRG.vocab)
DEC_HEADS = 8
DEC_PF_DIM = 512
# embed_dim = 256
# hidden_dim = 256
# segment_dim = 256
# n_layers = 6
# dropout = 0.4
# segment_threshold = 5
"""# Building Decoder"""
class Decoder(nn.Module):
def __init__(self, output_dim, embed_dim, hidden_dim,segment_dim,n_layers, dropout, attention):
super().__init__()
self.output_dim = output_dim
self.n_layers = n_layers
self.hidden_dim = hidden_dim
self.attention = attention
self.device = device
self.embedding = nn.Embedding(self.output_dim, embed_dim)
self.rnn = nn.GRU(embed_dim,hidden_dim,n_layers,dropout=dropout)
self.rnn = nn.GRU(embed_dim,hidden_dim,n_layers,dropout=dropout)
self.segmentRnn = nn.GRU(hidden_dim,hidden_dim,n_layers,dropout=dropout)
self.fc_out = nn.Linear((hidden_dim * 2) + hidden_dim + embed_dim, self.output_dim)
# self.soft = nn.LogSoftmax(dim=1)
self.soft = nn.Softmax(dim=1)
self.dropout = nn.Dropout(dropout)
def stable_softmax(self,x):
z = x - torch.max(x,dim=1,keepdim=True).values
numerator = torch.exp(z)
denominator = torch.sum(numerator, dim=1, keepdims=True)
softmax = numerator / denominator
return softmax
def forward(self, input, hidden, encoder_outputs):
#input = [target_len,batch size]
#hidden = [batch size, dec hid dim]
#encoder_outputs = [src len, batch size, enc hid dim * 2]
embedded = self.embedding(input)
#embedded = [target_len, batch size, emb dim]
output_target_decoder,hidden_target_decoder = self.rnn(embedded)
#output_target_decoder = [target_len, batch size, hidden_dim]
#hidden_target_decoder = [n layers , batch size, hidden_dim]
trg_len = input.shape[0]
batch_size = input.shape[1]
trg_vocab_size = self.output_dim
# later to be passed in constructor (currently accessing through Globals)
sop_symbol = TRG.vocab.stoi['<sop>']
eop_symbol = TRG.vocab.stoi['<eop>']
alpha = torch.zeros(batch_size,trg_len).to(self.device)
alpha[:,0] = 1
for end in range(1,trg_len):
for phraseLen in range(end,0,-1):
start = end - phraseLen + 1
weighted = self.attention(encoder_outputs, output_target_decoder[start-1])
sop_vector = (torch.ones(1,batch_size,dtype=torch.int64)*sop_symbol).to(self.device)
input_phrase = input[start:end+1,:]
input_phrase = torch.cat((sop_vector,input_phrase),0)
eop_vector = (torch.ones(1,batch_size,dtype=torch.int64)*eop_symbol).to(self.device)
input_phrase = torch.cat((input_phrase,eop_vector),0)
phraseEmbedded = self.embedding(input_phrase)
# currEmbedded = phraseEmbedded[0,:,:]
# rnn_input = torch.cat((currEmbedded.unsqueeze(0), weighted), dim = 2)
phraseProb = torch.ones(batch_size).to(self.device)
for t in range(input_phrase.shape[0]-1):
rnn_input = phraseEmbedded[t].unsqueeze(0)
output, hidden = self.segmentRnn(rnn_input)
output = output.squeeze(0)
weighted = weighted.squeeze(0)
rnn_input = rnn_input.squeeze(0)
prediction = self.fc_out(torch.cat((output, weighted, rnn_input), dim = 1))
#prediction = [batch size, output dim]
# probabilities = self.soft(prediction)
# phraseProb *= torch.exp(probabilities[torch.arange(batch_size),input_phrase[t+1]])
probabilities = self.stable_softmax(prediction)
phraseProb *= probabilities[torch.arange(batch_size),input_phrase[t+1]]
alpha[:,end] = alpha[:,end].clone() + phraseProb*alpha[:,start-1].clone()
return alpha
class NP2MT(nn.Module):
def __init__(self, encoder, decoder, device):
super().__init__()
self.encoder = encoder
self.decoder = decoder
self.device = device
def forward(self, src, trg, teacher_forcing_ratio = 0.5):
#src = [src len, batch size]
#trg = [trg len, batch size]
#teacher_forcing_ratio is probability to use teacher forcing
#e.g. if teacher_forcing_ratio is 0.75 we use teacher forcing 75% of the time
batch_size = src.shape[1]
trg_len = trg.shape[0]
trg_vocab_size = self.decoder.output_dim
''' moved this to Decoder now
# later to be passed in constructor (currently accessing through Globals)
sop_symbol = TRG.vocab.stoi['<sop>']
eop_symbol = TRG.vocab.stoi['<eop>']
#tensor to store decoder outputs
outputs = torch.zeros(trg_len, batch_size, trg_vocab_size).to(self.device)
'''
#encoder_outputs is representation of all phrases states of the input sequence, back and forwards
#hidden is the final forward and backward hidden states, passed through a linear layer (batch_size*hidden_dim)
encoder_outputs, hidden = self.encoder(src)
output = self.decoder(trg, hidden, encoder_outputs)
return output[:,-1]
attn = Attention(hidden_dim, hidden_dim)
enc = Encoder(input_dim, embed_dim, hidden_dim, segment_dim, n_layers, dropout, segment_threshold, device)
dec = Decoder(output_dim, embed_dim, hidden_dim, segment_dim, n_layers, dropout, attn)
model = NP2MT(enc, dec, device).to(device)
def init_weights(m):
for name, param in m.named_parameters():
if 'weight' in name:
nn.init.normal_(param.data, mean=0, std=0.01)
else:
nn.init.constant_(param.data, 0)
model.apply(init_weights)
def count_parameters(model):
return sum(p.numel() for p in model.parameters() if p.requires_grad)
print(f'The model has {count_parameters(model):,} trainable parameters')
optimizer = optim.Adam(model.parameters())
TRG_PAD_IDX = TRG.vocab.stoi[TRG.pad_token]
criterion = nn.CrossEntropyLoss(ignore_index = TRG_PAD_IDX)
def train(model, iterator, optimizer, criterion, clip):
model.train()
epoch_loss = 0
for i, batch in enumerate(iterator):
src = batch.src
trg = batch.trg
optimizer.zero_grad()
output = model(src, trg)
loss = -torch.log(output).mean()
loss.backward()
# print("Before optimization step\n\n")
# for name, param in model.named_parameters():
# if param.requires_grad:
# print(name, torch.isnan(param.data).any())
torch.nn.utils.clip_grad_norm_(model.parameters(), clip)
optimizer.step()
# print("After optimization step\n\n")
# for name, param in model.named_parameters():
# if param.requires_grad:
# print(name, torch.isnan(param.data).any())
epoch_loss += loss.item()
return epoch_loss / len(iterator)
def evaluate(model, iterator, criterion):
model.eval()
epoch_loss = 0
with torch.no_grad():
for i, batch in enumerate(iterator):
src = batch.src
trg = batch.trg
output = model(src, trg, 0) #turn off teacher forcing
#trg = [trg len, batch size]
#output = [trg len, batch size, output dim]
output_dim = output.shape[-1]
output = output[1:].view(-1, output_dim)
trg = trg[1:].view(-1)
#trg = [(trg len - 1) * batch size]
#output = [(trg len - 1) * batch size, output dim]
loss = criterion(output, trg)
epoch_loss += loss.item()
return epoch_loss / len(iterator)
def epoch_time(start_time, end_time):
elapsed_time = end_time - start_time
elapsed_mins = int(elapsed_time / 60)
elapsed_secs = int(elapsed_time - (elapsed_mins * 60))
return elapsed_mins, elapsed_secs
N_EPOCHS = 10
CLIP = 1
best_valid_loss = float('inf')
for epoch in range(N_EPOCHS):
start_time = time.time()
train_loss = train(model, train_iterator, optimizer, criterion, CLIP)
# valid_loss = evaluate(model, valid_iterator, criterion)
end_time = time.time()
epoch_mins, epoch_secs = epoch_time(start_time, end_time)
# if valid_loss < best_valid_loss:
# best_valid_loss = valid_loss
# torch.save(model.state_dict(), 'npmt-model.pt')
print(f'Epoch: {epoch+1:02} | Time: {epoch_mins}m {epoch_secs}s')
print(f'\tTrain Loss: {train_loss:.3f} | Train PPL: {math.exp(train_loss):7.3f}')
# print(f'\t Val. Loss: {valid_loss:.3f} | Val. PPL: {math.exp(valid_loss):7.3f}')
# model.load_state_dict(torch.load('npmt-model.pt'))
# test_loss = evaluate(model, test_iterator, criterion)
# print(f'| Test Loss: {test_loss:.3f} | Test PPL: {math.exp(test_loss):7.3f} |')