Summary of the problem
I’m implementing PPO for a combinatorial optimization task. The Actor and Critic network share an Encoder network module at the beginning, and then each follows a different path of Modules for different Policy and Value outputs. Roughly speaking it would be like this:
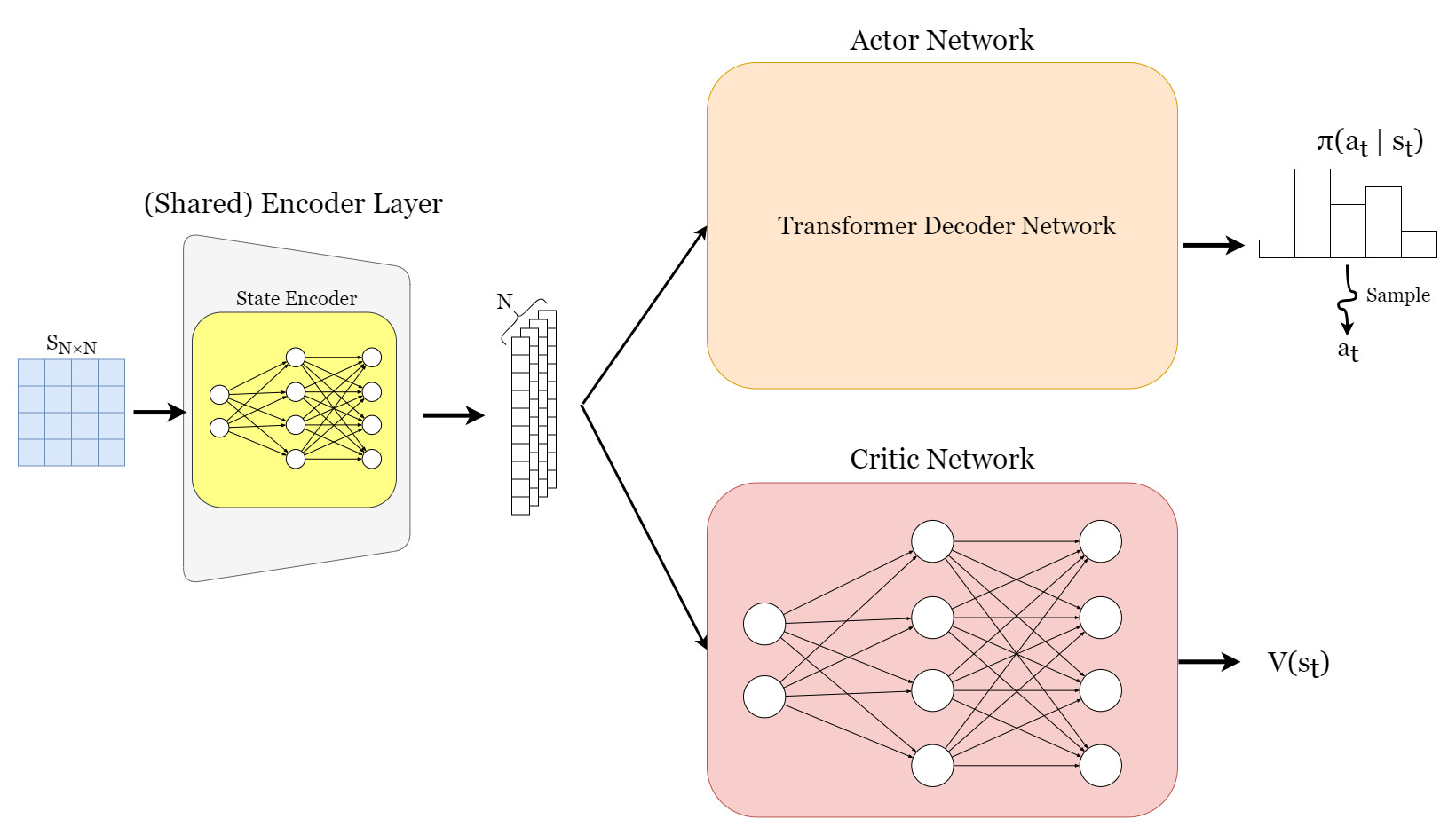
While doing a round of updates on the Actor and Critic networks after an episode is finished, I get the following runtime error. After following
RuntimeError: one of the variables needed for gradient computation
has been modified by an inplace operation:
[torch.cuda.FloatTensor [128, 128]], which is output 0 of AsStridedBackward0,
is at version 2; expected version 1 instead.
Hint: the backtrace further above shows the operation that failed to compute its gradient.
The variable in question was changed in there or anywhere later. Good luck!
Implementation details
The basic structure of the models is as follows:
#######################
#### ENCODER MODEL ####
#######################
class Encoder(nn.Module):
def __init__(self, num_instances, embed_dim, device):
super(Encoder, self).__init__()
self.num_instances = num_instances # n
self.embed_dim = embed_dim # d
self.device = device
self.lin1 = nn.Linear(num_instances, embed_dim)
self.lin2 = nn.Linear(embed_dim, embed_dim)
def forward(self, state):
# state: [b, n, n]
state_emb = F.relu(self.lin1(state))
state_emb = F.relu(self.lin2(state_emb))
# state_emb: [b, n, d]
return state_emb
#####################
#### ACTOR MODEL ####
#####################
class Actor(nn.Module):
def __init__(self, shared_encoder: nn.Module, config):
super(Actor, self).__init__()
self.num_instances = config.num_instances # n
self.embed_dim = config.embed_dim # d
self.shared_encoder = shared_encoder
self.device = config.device
self.transformer_decoder = nn.TransformerEncoderLayer(
d_model=config.embed_dim,
nhead=config.num_heads,
dim_feedforward=config.embed_dim*2,
dropout=config.dropout,
batch_first=True
)
self.linear = nn.Linear(config.embed_dim * config.num_instances, config.num_instances)
def forward(self, state):
# state: [b, n, n]
batch_size = state.size(0) # b
n = state.size(1) # n
embed_dim = self.embed_dim # d
emb = self.shared_encoder(state) # -> (b, n, d)
# transform the embeddings using transformer decoder
src_mask = torch.zeros(n, n).bool().to(self.device)
x = self.transformer_decoder(emb, src_mask) # (b, n, d)
x = x.view(batch_size, -1) # (b, n*d)
x = self.linear(x) # (b, n)
return x # (b, n) => Policy logits to construct probabilities during training
######################
#### CRITIC MODEL ####
######################
class Critic(nn.Module):
def __init__(self, shared_encoder: nn.Module, config):
""" Critic network for the actor-critic algorithm.
Only uses Fully Connected layers after the shared encoder.
"""
super(Critic, self).__init__()
self.num_instances = config.num_instances
self.embed_dim = config.embed_dim
self.device = config.device
self.shared_encoder = shared_encoder
self.linear1 = nn.Linear(config.embed_dim * config.num_instances, config.embed_dim)
self.linear2 = nn.Linear(config.embed_dim, config.embed_dim)
self.linear3 = nn.Linear(config.embed_dim, 1)
def forward(self, state):
# state: [b, n, n]
batch_size = state.size(0)
state_emb = self.shared_encoder(state) # -> (b, n, d)
x = state_emb.view(batch_size, -1) # (b, n*d)
x = self.linear1(x)
x = F.relu(x)
x = self.linear2(x) # (b, d)
x = F.relu(x)
x = self.linear3(x) # (b, 1)
return x # (b, 1) => V(s)
And the whole training procedure of the PPO algorithm is implemented this way:
class PPO:
def __init__(self, config):
self.config = config
self.n = config.num_instances
self.batch_size = config.batch_size
self.lr_actor = config.lr_actor
self.lr_critic = config.lr_critic
self.gamma = config.gamma
self.clip_ratio = config.clip_ratio
self.epochs = config.epochs
self.shared_encoder = Encoder(self.n, config.embed_dim, config.dropout, config.device).to(config.device)
self.actor = Actor(self.shared_encoder, config).to(config.device)
self.critic = Critic(self.shared_encoder, config).to(config.device)
self.actor_optimizer = torch.optim.Adam(self.actor.parameters(), lr=self.lr_actor)
self.critic_optimizer = torch.optim.Adam(self.critic.parameters(), lr=self.lr_critic)
self.critic_loss_fn = nn.MSELoss()
self.memory = []
def get_action(self, state, action_mask):
if isinstance(state, np.ndarray):
state = torch.tensor(state, dtype=torch.float32).unsqueeze(0).to(self.config.device)
logits = self.actor(state).squeeze()
masked_logits = logits.detach().cpu() + (1 - np.squeeze(action_mask)) * -1e8
dist = torch.distributions.Categorical(logits=masked_logits)
action = dist.sample()
log_prob = dist.log_prob(action)
return action.item(), log_prob
def store_transition(self, state, action, reward, next_state, done, log_prob):
self.memory.append((state, action, reward, next_state, done, log_prob))
def update(self):
states, actions, rewards, next_states, dones, old_log_probs = zip(*self.memory)
dev = self.config.device
states = torch.tensor(states, dtype=torch.float32).to(dev)
actions = torch.tensor(actions, dtype=torch.int64).view(-1, 1).to(dev)
rewards = torch.tensor(rewards, dtype=torch.float32).view(-1, 1).to(dev)
next_states = torch.tensor(next_states, dtype=torch.float32).to(dev)
dones = torch.tensor(dones, dtype=torch.float32).view(-1, 1).to(dev)
old_log_probs = torch.tensor(old_log_probs, dtype=torch.float32).view(-1, 1).to(dev)
# Compute the advantages
with torch.no_grad():
target_values = rewards + self.gamma * (1 - dones) * self.critic(next_states)
advantages = target_values - self.critic(states)
# PPO update for the actor and critic
for _ in range(self.epochs):
logits = self.actor(states)
dist = torch.distributions.Categorical(logits=logits)
log_probs = dist.log_prob(actions)
ratios = torch.exp(log_probs - old_log_probs)
# Clipped surrogate objective for the policy fn
actor_loss = -torch.min(ratios * advantages, torch.clamp(
ratios, 1 - self.clip_ratio, 1 + self.clip_ratio) * advantages).mean()
# Value function loss
critic_loss = self.critic_loss_fn(self.critic(states), target_values)
self.actor_optimizer.zero_grad()
actor_loss.backward()
self.actor_optimizer.step()
self.critic_optimizer.zero_grad()
critic_loss.backward()
self.critic_optimizer.step()
def train(self, env, num_episodes):
self.actor.train()
self.critic.train()
for episode in range(num_episodes):
state, _ = env.reset()
done = False
total_reward = 0
while not done:
action_mask = env.get_action_mask()
action, log_prob = self.get_action(state, action_mask)
next_state, reward, done, _, _ = env.step(action)
self.store_transition(state, action, reward, next_state, done, log_prob)
total_reward += reward
state = next_state
self.update()
del self.memory[:]
print(f"Episode: {episode + 1}, Total Reward: {total_reward}")
Where the issue happens during the update method.
Reproduction
For reproduction use such env and config:
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
# random env
class RndEnv:
def __init__(self, n ):
self.n = n
self.step = 0
def reset(self):
return np.random.rand(n,n), {}
def step(self, action):
self.step += 1
if self.step == self.n:
return np.random.rand(n,n), np.random.rand(), True, False, {}
return np.random.rand(n,n), {}, False, False, {}
def get_action_mask(self):
return np.ones(self.n, dtype=np.float32)
class TestConfig():
"""The config class."""
num_instances = 7 # (n)
train_episodes = 100
test_episodes = 10
embed_dim = 128
num_heads = 8
dropout = 0.1
lr_actor = 1e-4
lr_critic = 1e-4
gamma = 1.0
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
batch_size = 64
epochs = 10
config = TestConfig()
env = RndEnv(config.num_instances)
ppo = PPO(config)
ppo.train(env)
Solutions tried so far
After using the autograd.set_detect_anomaly(True) it is shown that the error happened while computing the backward through the self.critic network for updating the critic optimizer. meaning at the critic_loss.backward() and it happened at the last linear layer of the Encoder meaning state_emb = F.relu(self.lin2(state_emb)).
Based on what said and reading similar questions to mine on this forum I have found that it is kind of similar to this issue , this issue, or maybe this one.. I tried cloning the states and advantages for each pass, but it didn’t work. I also checked for all in-place operations, but nothing was found.
I mainly suspect the issue is with the encoder being shared and the inputs being used twice. As I tried instantiating to separate encoders and use each for actor and critic, the training will work seamlessly. So the shared layer is causing the issue but I can’t find why.
I appreciate any help or suggestions.
Full error message
---------------------------------------------------------------------------
RuntimeError Traceback (most recent call last)
Cell In[3], line 11
7 ppo_model = PPO(config)
9 env = QAPEnv(config.num_instances)
---> 11 ppo_model.train(env, config.train_episodes)
File c:\Users\...\trainer.py:117, in PPO.train(self, env, num_episodes)
114 total_reward += reward
115 state = next_state
--> 117 self.update()
118 del self.memory[:]
119 print(f"Episode: {episode + 1}, Total Reward: {total_reward}")
File c:\Users\...\trainer.py:92, in PPO.update(self)
89 self.actor_optimizer.step()
91 self.critic_optimizer.zero_grad()
---> 92 critic_loss.backward()
93 self.critic_optimizer.step()
95 # v_ = self.critic(states)
96 # critic_loss = self.critic_loss_fn(v_, target_values)
File c:\Users\...\.venv\Lib\site-packages\torch\_tensor.py:525, in Tensor.backward(self, gradient, retain_graph, create_graph, inputs)
515 if has_torch_function_unary(self):
516 return handle_torch_function(
517 Tensor.backward,
518 (self,),
(...)
523 inputs=inputs,
524 )
--> 525 torch.autograd.backward(
526 self, gradient, retain_graph, create_graph, inputs=inputs
527 )
File c:\Users\...\.venv\Lib\site-packages\torch\autograd\__init__.py:267, in backward(tensors, grad_tensors, retain_graph, create_graph, grad_variables, inputs)
262 retain_graph = create_graph
264 # The reason we repeat the same comment below is that
265 # some Python versions print out the first line of a multi-line function
266 # calls in the traceback and some print out the last line
--> 267 _engine_run_backward(
268 tensors,
269 grad_tensors_,
270 retain_graph,
271 create_graph,
272 inputs,
273 allow_unreachable=True,
274 accumulate_grad=True,
275 )
File c:\Users\...\.venv\Lib\site-packages\torch\autograd\graph.py:744, in _engine_run_backward(t_outputs, *args, **kwargs)
742 unregister_hooks = _register_logging_hooks_on_whole_graph(t_outputs)
743 try:
--> 744 return Variable._execution_engine.run_backward( # Calls into the C++ engine to run the backward pass
745 t_outputs, *args, **kwargs
746 ) # Calls into the C++ engine to run the backward pass
747 finally:
748 if attach_logging_hooks:
RuntimeError: one of the variables needed for gradient computation has been modified by an inplace operation: [torch.cuda.FloatTensor [128, 128]], which is output 0 of AsStridedBackward0, is at version 2; expected version 1 instead. Hint: enable anomaly detection to find the operation that failed to compute its gradient, with torch.autograd.set_detect_anomaly(True).