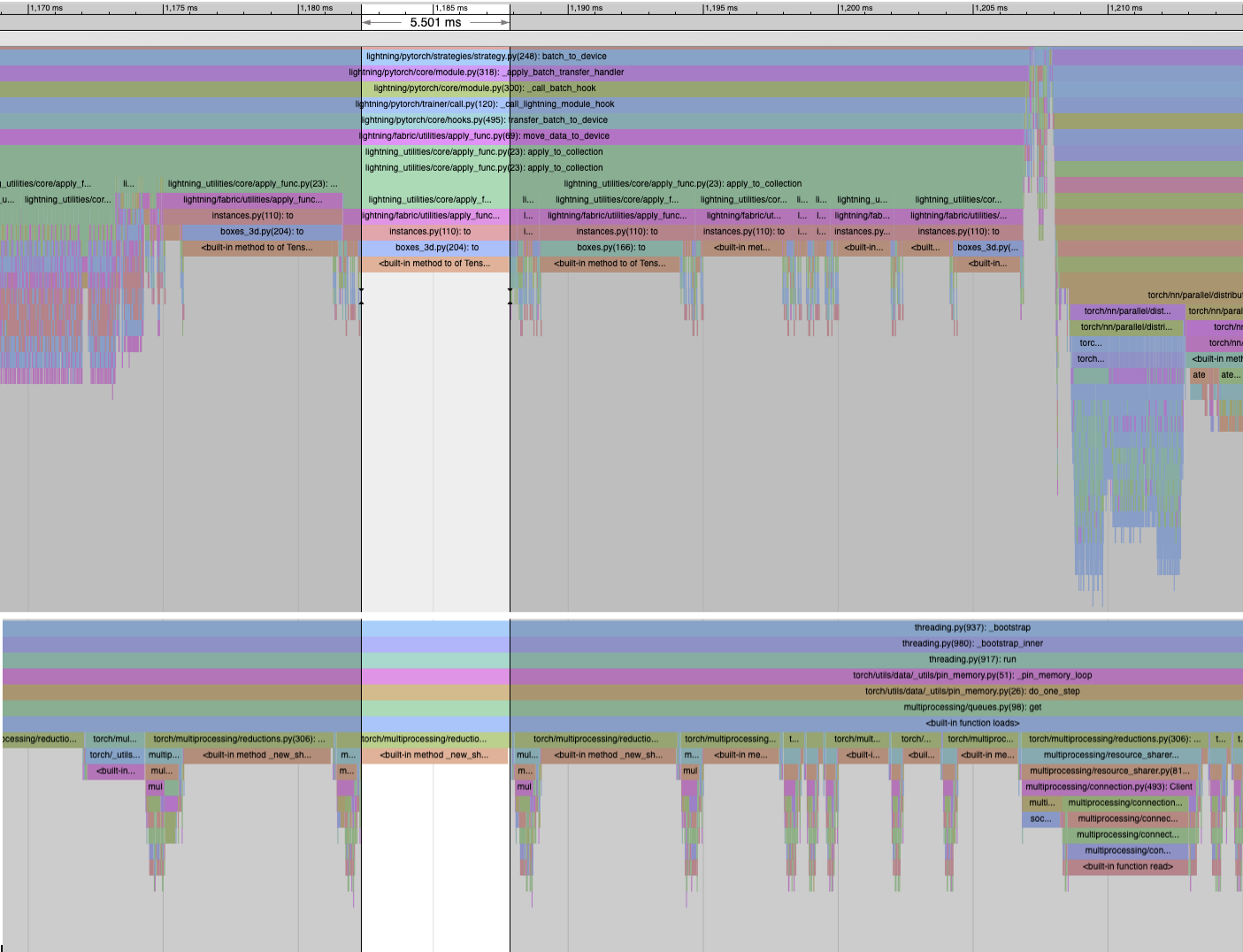
We’re observing what looks like recurring patterns of significant competition for the GIL between the pin_memory and the main trainer threads. See in the trace below: the trainer thread seems to be stalled by the pin_memory thread repeatedly holding the GIL during some long operations.
In this case, it’s PyTorch code that’s holding the GIL in THPStorage_newSharedFd. But I’ve observed other instances of this pattern, e.g. in the Python built-in _io module. And there was another report of a similar issue (now mitigated) with the pin_memory thread.
So it appears we are looking at a pattern of long-running operations holding the GIL, rather than an isolated problem. To make things worse, the performance hit is greatly amplified in a distributed training environment, as the probability of any rank hitting this GIL contention pattern increases.
I can’t think of a straightforward solution. I understand from this discussion that memory pinning cannot be moved to a different process. Do you see a mitigation, short of rewriting the multiprocessing queue and memory pinning logic in C++?
Hey!
This is a very good question!
I think the long term solution here is going to switch to no-gil python. If you have this flexibility, 3.13 should have this as an opt-in feature and so is not that far away!
If this is not an option, then I guess yes moving part of this in C++ could help. But it’s not super clear to me because the only parts that you can really move to c++ are the ones that don’t use python, and these ones we should be releasing the GIL today (do open issues / send PR to fix that if we don’t!).
So short of re-writing the whole queuing system, I’m not sure this is going to help indeed.
The thing is the multiprocessing module supports a lot of features and will be quite daunting to rewrite. If you’re only sending Tensors over the wire though, it might be “relatively” simple to have such an extension. Integrating it within PyTorch dataloader might be a bit challenging though.
So a good middle ground (between moving to the latest beta CPython version and rewriting a whole multiprocessing comm protocal) here might be to systematically hunt down any missing gil release?
Thanks for the thorough answer, @albanD ! For a long term solution, I agree the C++ rewrite option is not a clear case given the level of effort and unknowns. The case becomes even more difficult to make if the PyTorch team is considering adopting the no-gil Python developments. In the meantime, hunting down the worst offenders seems like the most practical option. We’ll look in that direction.
FWIW to facilitate this, I have added GIL monitoring capability to Python (new GIL release / wait / acquire event notifications sent to the built-in Python profiler hook) and I also patched the PyTorch profiler to surface these events in traces. See highlights in trace below. I’m planning to release these patches as PRs for anybody else interested in analyzing GIL contention issues.
Pretty cool, interested in trying out the GIL monitoring in PyTorch profiler. Do you have the PRs for it (not sure if it is already out there)? Thanks.