I get this error nd I am new to pytorch..Pls help ..It will be really grateful ..Thanks in Advance!!!
I SHALL COPY PASTE THE ERROR :
RuntimeError Traceback (most recent call last)
in
4 # specify optimizer
5 optimizer = optim.Adam(model_1.parameters(), lr=0.001)
----> 6 model_1_validation_losses = train_by_model_and_custom_loader(model_1, train_loader_1, valid_loader_1, criterion, optimizer, ‘model_ecg_heartbeat_categorization_1.pt’, num_epochs, train_on_gpu)
in train_by_model_and_custom_loader(model, train_loader, valid_loader, criterion, optimizer, best_model_name, n_epochs, train_on_gpu)
32 optimizer.zero_grad()
33 # forward pass: compute predicted outputs by passing inputs to the model
—> 34 output = model(data.float())
35 #print(“o/pT”)(
36 #print(output.shape)
/opt/conda/lib/python3.7/site-packages/torch/nn/modules/module.py in _call_impl(self, *input, **kwargs)
725 result = self._slow_forward(*input, **kwargs)
726 else:
→ 727 result = self.forward(*input, **kwargs)
728 for hook in itertools.chain(
729 _global_forward_hooks.values(),
in forward(self, input)
33 #input = input.view(32, -1, 187)
34 input = input.unsqueeze(0)
—> 35 x = self.conv1(input)
36 x = self.conv2(x)
37 x = self.conv3(x)
/opt/conda/lib/python3.7/site-packages/torch/nn/modules/module.py in _call_impl(self, *input, **kwargs)
725 result = self._slow_forward(*input, **kwargs)
726 else:
→ 727 result = self.forward(*input, **kwargs)
728 for hook in itertools.chain(
729 _global_forward_hooks.values(),
in forward(self, input)
50
51 def forward(self, input):
—> 52 conv1 = self.conv_1(input)
53 x = self.normalization_1(conv1)
54 x = self.swish_1(x)
/opt/conda/lib/python3.7/site-packages/torch/nn/modules/module.py in _call_impl(self, *input, **kwargs)
725 result = self._slow_forward(*input, **kwargs)
726 else:
→ 727 result = self.forward(*input, **kwargs)
728 for hook in itertools.chain(
729 _global_forward_hooks.values(),
/opt/conda/lib/python3.7/site-packages/torch/nn/modules/conv.py in forward(self, input)
257 _single(0), self.dilation, self.groups)
258 return F.conv1d(input, self.weight, self.bias, self.stride,
→ 259 self.padding, self.dilation, self.groups)
260
261
RuntimeError: Given groups=1, weight of size [128, 1, 5], expected input[1, 32, 187] to have 1 channels, but got 32 channels instead
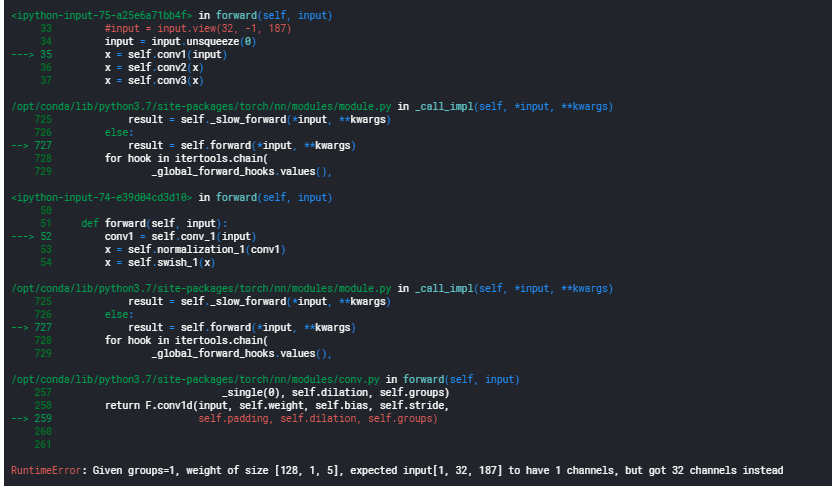
The following is the code that I used…I called the model using:
model_1 = CNN(num_classes=5, hid_size=128).to(device)
The model code is:
class ConvNormPool(nn.Module):
def __init__(
self,
input_size,
hidden_size,
kernel_size,
norm_type='bachnorm'
):
super().__init__()
self.kernel_size = kernel_size
self.conv_1 = nn.Conv1d(
in_channels=input_size,
out_channels=hidden_size,
kernel_size=kernel_size
)
self.conv_2 = nn.Conv1d(
in_channels=hidden_size,
out_channels=hidden_size,
kernel_size=kernel_size
)
self.conv_3 = nn.Conv1d(
in_channels=hidden_size,
out_channels=hidden_size,
kernel_size=kernel_size
)
self.swish_1 = Swish()
self.swish_2 = Swish()
self.swish_3 = Swish()
if norm_type == 'group':
self.normalization_1 = nn.GroupNorm(
num_groups=8,
num_channels=hidden_size
)
self.normalization_2 = nn.GroupNorm(
num_groups=8,
num_channels=hidden_size
)
self.normalization_3 = nn.GroupNorm(
num_groups=8,
num_channels=hidden_size
)
else:
self.normalization_1 = nn.BatchNorm1d(num_features=hidden_size)
self.normalization_2 = nn.BatchNorm1d(num_features=hidden_size)
self.normalization_3 = nn.BatchNorm1d(num_features=hidden_size)
self.pool = nn.MaxPool1d(kernel_size=2)
def forward(self, input):
conv1 = self.conv_1(input)
x = self.normalization_1(conv1)
x = self.swish_1(x)
x = F.pad(x, pad=(self.kernel_size - 1, 0))
x = self.conv_2(x)
x = self.normalization_2(x)
x = self.swish_2(x)
x = F.pad(x, pad=(self.kernel_size - 1, 0))
conv3 = self.conv_3(x)
x = self.normalization_3(conv1+conv3)
x = self.swish_3(x)
x = F.pad(x, pad=(self.kernel_size - 1, 0))
x = self.pool(x)
return x
class CNN(nn.Module):
def init(
self,
input_size = 1,
hid_size = 256,
kernel_size = 5,
num_classes = 5,
):
super().__init__()
self.conv1 = ConvNormPool(
input_size=input_size,
hidden_size=hid_size,
kernel_size=kernel_size,
)
self.conv2 = ConvNormPool(
input_size=hid_size,
hidden_size=hid_size//2,
kernel_size=kernel_size,
)
self.conv3 = ConvNormPool(
input_size=hid_size//2,
hidden_size=hid_size//4,
kernel_size=kernel_size,
)
self.avgpool = nn.AdaptiveAvgPool1d((1))
self.fc = nn.Linear(in_features=hid_size//4, out_features=num_classes)
def forward(self, input):
#print("INPUT SHAPE is ")
#print(input.shape)
#input = input.view(32, -1, 187)
#input = input.unsqueeze(0)
x = self.conv1(input)
x = self.conv2(x)
x = self.conv3(x)
x = self.avgpool(x)
# print(x.shape) # num_features * num_channels
x = x.view(-1, x.size(1) * x.size(2))
x = F.softmax(self.fc(x), dim=1)
return x
def train_by_model_and_custom_loader(model, train_loader, valid_loader, criterion, optimizer, best_model_name, n_epochs, train_on_gpu):
model = model.float()
# move tensors to GPU if CUDA is available
if train_on_gpu:
model.cuda()
valid_loss_min = np.Inf # track change in validation loss
valid_losses =
for epoch in range(1, n_epochs+1):
# keep track of training and validation loss
train_loss = 0.0
valid_loss = 0.0
###################
# train the model #
###################
model.train()
for data, target in train_loader:
# move tensors to GPU if CUDA is available
if train_on_gpu:
data, target = data.cuda(), target.cuda()
###print(data)
###print(data.shape)
###print("FLOAT")
######print(data.float())
###print(data.float().shape)
######print(target)
###print(target.shape)
# clear the gradients of all optimized variables
optimizer.zero_grad()
# forward pass: compute predicted outputs by passing inputs to the model
output = model(data.float())
#print("o/pT")(
#print(output.shape)
# calculate the batch loss
loss = criterion(output, target)
# backward pass: compute gradient of the loss with respect to model parameters
loss.backward()
# perform a single optimization step (parameter update)
optimizer.step()
# update training loss
train_loss += loss.item()*data.size(0)
######################
# validate the model #
######################
model.eval()
for data, target in valid_loader:
# move tensors to GPU if CUDA is available
if train_on_gpu:
data, target = data.cuda(), target.cuda()
# forward pass: compute predicted outputs by passing inputs to the model
output = model(data.float())
# calculate the batch loss
loss = criterion(output, target)
# update average validation loss
valid_loss += loss.item()*data.size(0)
# calculate average losses
train_loss = train_loss/len(train_loader.dataset)
valid_loss = valid_loss/len(valid_loader.dataset)
valid_losses.append(valid_loss)
# print training/validation statistics
print('Epoch: {} \tTraining Loss: {:.6f} \tValidation Loss: {:.6f}'.format(
epoch, train_loss, valid_loss))
# save model if validation loss has decreased
if valid_loss <= valid_loss_min:
print('Validation loss decreased ({:.6f} --> {:.6f}). Saving model ...'.format(
valid_loss_min,
valid_loss))
torch.save(model.state_dict(), best_model_name)
valid_loss_min = valid_loss
return valid_losses