Hi. Recently , i replace BN in my network with Group Normalization. However, i find that GN usually consumes more GPU memory. Is it normal?
1 Like
Group normalisation is similar to batchnorm but on subsets of the channels right? So I guess yes it can use more memory because it has more states to save?
Thanks for reply~
But i consider that the state for GN need to be stored is a Bx(C/G) tenosr while Cx1 tensor for BN.(p.s G is channel number for each group) . I think this tensor only occupies tirvial memory. However, for my network, it consumes 4G memory for BN while 6G memory for GN( B=16 G=16). Are there any extra states with big size (like feature map) need to be stored for GN?
Hi,
But the normalization is only on the channel layer no? I may have missed something about batchnorm. But in that case, you keep the other dimensions of your image. So you save Bx(C/G)xHxW compared to Bx1xHxW in the batchnorm. So the difference will be quite significant especially because you need buffers for mean, the std and the output.
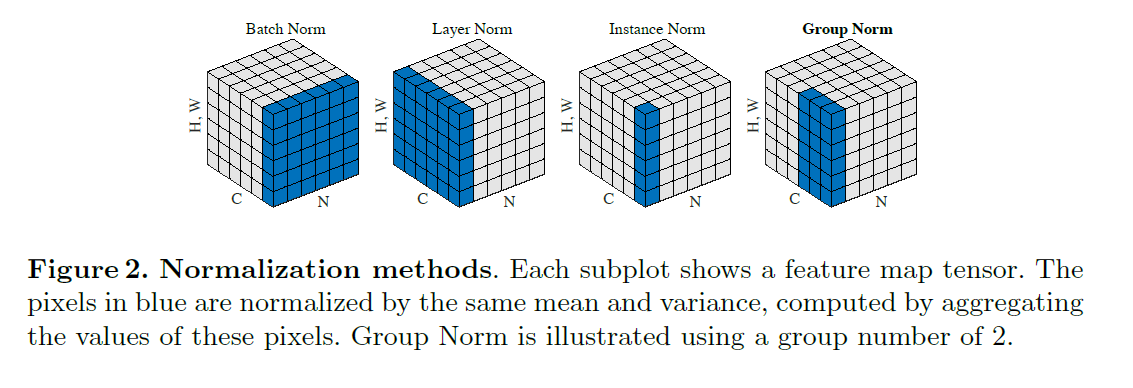
But I think the mean and std are computed along BxHxW dimension for BN. Therefore, only C dimension are keeped(Cx1x1x1)?
This is an unofficial implemantation of GN from GitHub - taokong/group_normalization: pytorch implementation of group normalization in https://arxiv.org/abs/1803.08494
It can be seen that mean is a tensor with size NxGx1 (I confirmed this with a simple test code).
emm… For BN, the mean I think is a tensor with size Cx1? But this still can’t result in huge memory usage…
So i think maybe there is something that consumes large memory in backward pass ?
Still, It’s very kind of you to give me help ~ ![]()
GroupBatchnorm2d(nn.Module):
def __init__(self, c_num, group_num = 16, eps = 1e-10):
super(GroupBatchnorm2d,self).__init__()
self.group_num = group_num
self.gamma = nn.Parameter(torch.ones(c_num, 1, 1))
self.beta = nn.Parameter(torch.zeros(c_num, 1, 1))
self.eps = eps
def forward(self, x):
N, C, H, W = x.size()
x = x.view(N, self.group_num, -1)
mean = x.mean(dim = 2, keepdim = True)
std = x.std(dim = 2, keepdim = True)
print(mean.size())
print(std.size())
x = (x - mean) / (std+self.eps)
x = x.view(N, C, H, W)
return x * self.gamma + self.beta
1 Like
Ho, you use this custom nn.Module to do your GroupNorm? Or do you use the one already in pytorch?
I’ve tried both. Official code and this custom module both results in extra memory. For official code, its extra memory is less than this custom nn.Module~:rofl:
Hi,
Yes one big difference is that your custom module creates a few intermediary results that require extra buffer. While the official module optimize the code to reduce buffer usage.
I know that the batchnorm code has been very heavily optimized for that in particular, maybe the GN code is not as mature?
Hi,
Got it. Very thank you for your reply 
