Hello Everyone!
I am building a Neural Image Caption Generator using Flickr8K dataset which is available here on Kaggle. I have uploaded the dataset to Google Drive and I am using Colab in order to build my Encoder-Decoder Network to generate captions from images.
However, I come across this error. The strange part is that the model successfully trains for several batches before throwing this error.
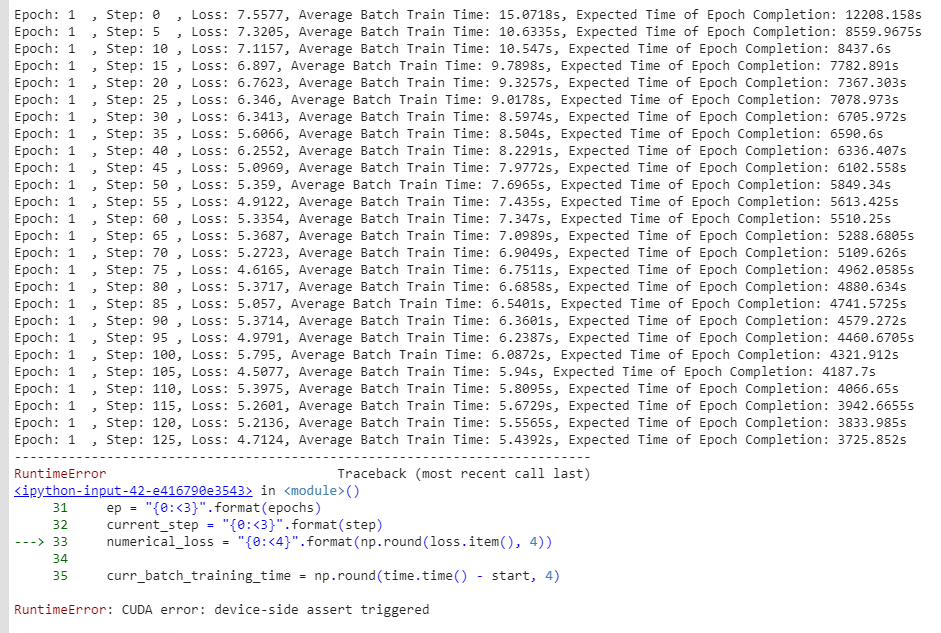
I have looked across several threads in this forum and tried to implement them but to no effect. Also, let me tell you that after this error happens, I am not able to use cuda at all. Since I am only allowed to post one image, I have attached a snapshot here.
I have enabled the CUDA_LAUNCH_BLOCKING in order to print the error message.
os.environ['CUDA_LAUNCH_BLOCKING'] = "1"
But I cannot discern any problem with the line that it’s pointing(i.e. line 33 in second to last screenshot above) since it has worked for all other iterations.
Can anyone kindly help me with this issue? I would be grateful for any suggestions in earnest.
Attaching Training Loop Code FYR
os.environ['CUDA_LAUNCH_BLOCKING'] = "1"
num_batches = total_steps
for epochs in range(1, num_epochs+1):
batch_train_time = 0
for step in range(num_batches):
start = time.time()
train_images, train_captions = next(iter(training_generator))
# Move to cuda if GPU is available
train_images = train_images.to(device)
train_captions = train_captions.to(device)
# Reset the gradients else they'll get accumulated
decoder.zero_grad()
encoder.zero_grad()
# Forward Pass
image_features = encoder(train_images)
output = decoder(image_features, train_captions)
# Find the batch loss
loss = criterion(output.view(-1, vocab_size), train_captions.view(-1))
# Backpropogate the loss
loss.backward()
# Update the parameters in the optimizer
optimizer.step()
# Get the statistics
ep = "{0:<3}".format(epochs)
current_step = "{0:<3}".format(step)
numerical_loss = "{0:<4}".format(np.round(loss.item(), 4))
curr_batch_training_time = np.round(time.time() - start, 4)
batch_train_time += curr_batch_training_time
avg_batch_train_time = "{0:<4}".format(np.round(batch_train_time / (1 + step), 4))
expected_remaining_time = "{0:<4}".format(np.round(float(avg_batch_train_time) * (num_batches - step), 4))
measures = f"Epoch: {ep}, Step: {current_step}, Loss: {numerical_loss}, Average Batch Train Time: {avg_batch_train_time}s, Expected Time of Epoch Completion: {expected_remaining_time}s"
print(f'\r{measures}', end = "")
sys.stdout.flush()
if step % periodic_check == 0:
print(f'\r{measures}')
if (1 + step) % 100 == 0:
torch.save(decoder.state_dict(), os.path.join('/content/drive/My Drive', f'batch_decoder-{step*100 + epochs}.pkl'))
torch.save(encoder.state_dict(), os.path.join('/content/drive/My Drive', f'batch_encoder-{step*100 + epochs}.pkl'))