I have a quick question. What I noticed is that GPU leads the model overfitting while CPU gets good result. My data is very small so I built the model basic. But interestingly CPU gave good results then I wanted the model runs through GPU so that it moves fast. But i am seeing dramatic bad results in val_loss. But the results can be considered as good in CPU.
I searched from somewhere, then it is said that CPU accidentally regulates the model by moving slow in updating gradients. Is it correct? What are your thoughts?
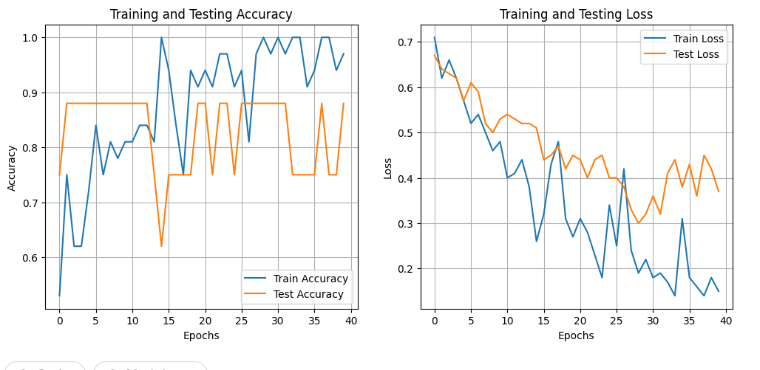
I did as @Naming-isDifficult mentioned. But when i kept searching, i discovered that each results after every single training are different from each other. I was thinking that randomness would be the same in each run if i set seeds with a generic number. But some results are very dramatically different somehow. It is very annoying to catch the best model evaluation. Even without doing anything btw these 2 runs, i got these scores.
Note: testing accuracy was meant to say ‘validation’. it is written wrong.
My data would be exposed by image augmentation (cv2.compose) with random.choice. the data is splitted into train and val in a random way (seed = 42), torch tensor would gather the data in a shuffle way.
Is there any proper solution to get the model to give the same results in each run? Did i miss anyhing in this concept?
Could you try to initialize a model (cpu or gpu), then save the initialized state of the weights and run it without shuffles and augmentations, then port the initial model to the 2nd device and repeat.
It should come back identical (i think).
You might want to see this paper about randomness and results: Hadges, A., & Bellur, S. (2025). Statistical Validity of Neural-Net Benchmarks. IEEE Open Journal of the Computer Society, 6(01), 211-222. CSDL | IEEE Computer Society