My network cannot utilize the full GPU. Only 10% of the GPU was utilized when the batch size was 8.
I increased the batch size from 8 to 16 and in that case it was giving me a Out of memory issue. Even for batch size 12, the network used only 10/12 % of the GPU.
Any suggestions would be appreciated.
It might be useful to check what the relative time spent processing data is, and if there are any overheads or preprocessing that can be done to this up.
Yea as @eqy mentioned, there could be an instance where you really are using your gpu for a decent amount of it’s capacity, but you don’t “see it” being used because most of the time there’s other things running (non-gpu).
In addition to checking for that, I’d also double check that things aren’t staying on the gpu longer then they should be! (maybe the batch size 12 case said the gpu was too much because as things keep running, more gpu space was getting utilized and not freed? not sure if you’re saying batch size 12 instantly errored out of space, but just an open-end thought
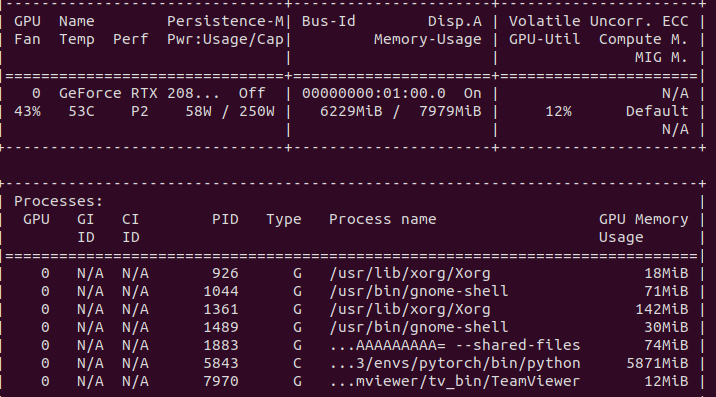
I should have mentioned that my GPU has 8GB RAM and 6.2GB has been used. But on the right side, it is showing 12%is being used. Does that mean the network is computationally expensive but it has been using the GPU fully?
GPU-Util: It indicates the percent of GPU utilization i.e. percent of time when kernels were using GPU. For instance , output in table above shown 13% of the time. In case of low percent, GPU was under-utilised when if code spends time in reading data from disk (mini-batches).
I’m guessing there’s a lot going on in the code besides stuff processing on the GPU!