I have encountered an odd problem:
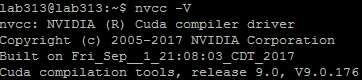
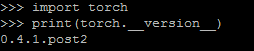
My lab has a server with four 1080Ti GPU(about 12G),and it’s used by multiusers. I have installed CUDA9.0, cuDNN7.4.3 for CUDA9.0, pytorch 0.4.1。
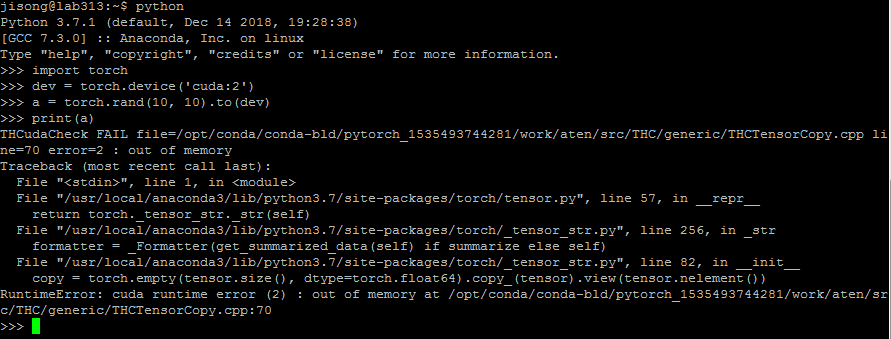
When I create a random tensor, neither small size of big size, when it’s print or copy, it occur an error, which say “cuda runtime error:out of memory”. I check the use of GPU, it’s not utilized and enough for such a tensor.
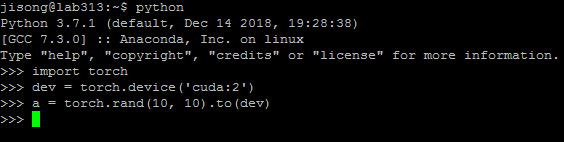
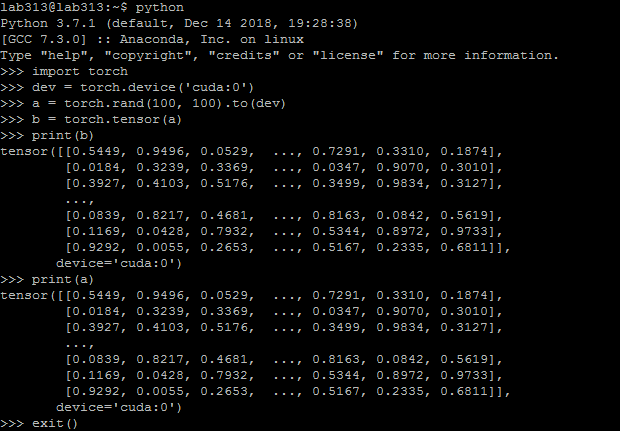
create a tensor:
print this tensor:
Then I think it may be the NVIDIA’s cuda problem, so I reinstall cuda of the same version, and cudnn. And then it works. I can successfully print it and copy it.
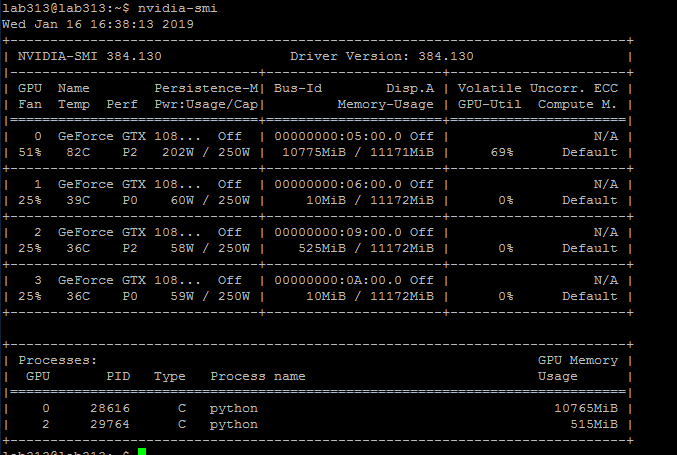
Then I go to take a break, and when I go back to do the same thing, it fail. It occur the same problem as previous. The thing I need to add is, after I reinstall cuda and cudnn, my friend begin to run her tensorflow code with GPU0(I don’t know if it will affect).
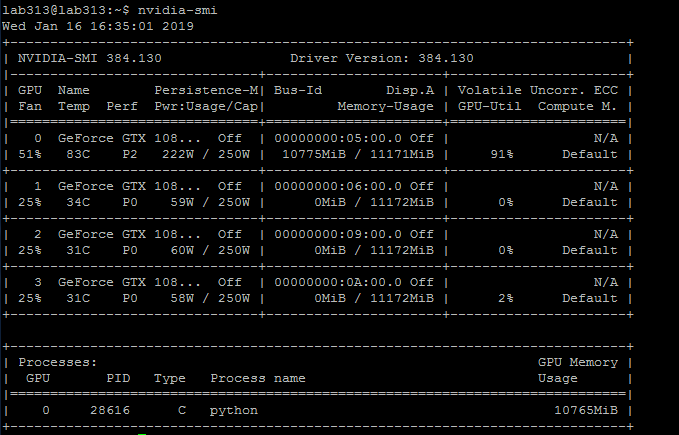
In addition, when I create the tensor and make it to GPU device, it really occupy the GPU usage, but when print or copy, it failed.For example, like the code I show above, I create a 10x10 size of tensor and make it to GPU2,then the GPU usage is as follow, it also seems wired, because it occupies too much.
Tensorflow has the bad habbit of taking all the memory on the device and prevent anything from happening on it as anything will OOM.
There was a small bug in pytorch that was initializing the cuda runtime on device 0 when printing that has been fixed.
A simple workaround is to use CUDA_VISIBLE_DEVICES=2. This will hide all devices but the one you specify and will make sure you never use other devices.
Awesome! Thank you, @albanD!
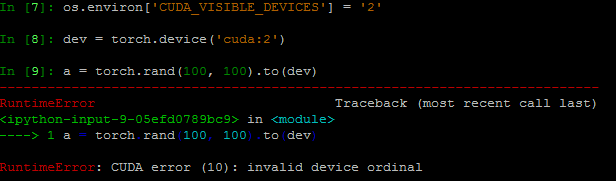
In Python, I import os to set CUDA_VISIBLE_DEVICES, like this.
But when I set to use use GPU2 as previous, It doesn’t work.
The error say “invalid device ordinal”. Then I realize that when I set the CUDA_VISIBLE_DEVICES, there are only the devices set is visible. For example, if I set GPU2 and GPU3 visible,
That means ‘cuda:0’ now refer to GPU2, while ‘cuda:1’ refer to GPU3. Therefore ‘cuda:2’ will make error.
Thanks again to @albanD! You help me a lot!
I would have replied to you soon, but these few day I can’t access to the forum.
Please provide more information, otherwise it’s difficult to know where is your bug. How many gpus you have, and how you write the code to copy to cuda, and maybe your batch size is too large?
By the way, it would be better not to use Chinese to post your problem. It’s not beneficial for you to seek a solution. Therefore, please use English, to get it caught by more viewers.

 ![torch2|690x86]
![torch2|690x86]