I am getting various problem in pytorch about the Dataloader.
I created a custom dataloader but after every batch the GPU allocated memory increases even if the gpu memory utilziation is constant after the initial batches. I would expect the same for the GPU allocated memory, but since it does not happen my training crashes for OOM issues.
That’s the snippet of my dataloader:
class PairedJP2Dataset(Dataset):
def __init__(self, dir2, dir3, transform2=None):
super(PairedJP2Dataset, self).__init__()
# Ensure directories exist
assert os.path.isdir(dir2), f"{dir2} is not a directory."
assert os.path.isdir(dir3), f"{dir3} is not a directory."
self.dir2_files = sorted([os.path.join(dir2, fname) for fname in os.listdir(dir2) if fname.endswith('.jp2')])
self.dir3_files = sorted([os.path.join(dir3, fname) for fname in os.listdir(dir3) if fname.endswith('.jp2')])
assert len(self.dir2_files) == len(self.dir3_files), "Directories have different number of .jp2 files."
self.transform2 = transform2
def __len__(self):
return len(self.dir2_files)
def __getitem__(self, idx):
data2 = Image.open(self.dir2_files[idx])
data3 = Image.open(self.dir3_files[idx])
data2 = to_tensor(data2)
data3 = to_tensor(data3)
# Apply any transformations if provided
if self.transform2:
data2 = self.transform2(data2)
if self.transform2:
data3 = self.transform2(data3)
return data2, data3
train_data = DataLoader(train_dataset, batch_size=2,
shuffle=False,
pin_memory=True,# pin_memory set to True
num_workers=12,
prefetch_factor=4,
drop_last=False)
val_data = DataLoader(val_dataset, batch_size=2,
shuffle=False,
pin_memory=True,# pin_memory set to True
num_workers=12,
prefetch_factor=4, # pin_memory set to True
drop_last=False)
That’s the snippet of my training loop:
# Training loop
for epoch in range(args.epochs):
logging.info(f"Starting epoch {epoch}:")
pbar = tqdm(train_data)
model.train()
train_loss = 0.0
psnr_train = 0.0
for i, (image_94, image_peak) in enumerate(pbar):
img_24 = image_94.to(device).float().reshape(image_94.shape[0], 1, 1024, 1024)
img_peak = image_peak.to(device).float().reshape(image_peak.shape[0], 1, 1024, 1024)
labels = None
t = torch.rand(size=(img_peak.shape[0],)).to(device)
#t = diffusion.sample_timesteps(img_peak.shape[0]).to(device)
with autocast():
fct = t[:, None, None, None]
transformed_image = (1-fct)*img_24 + fct*img_peak
predicted_peak = model(transformed_image, labels, t).reshape(img_24.shape[0], 1, 1024, 1024)
# t = t[:, None, None, None]
# x_t = (1-t) * img_24 + t * predicted_peak
loss = mse(img_peak, predicted_peak)
optimizer.zero_grad()
scaler.scale(loss).backward()
scaler.step(optimizer)
scaler.update()
ema.step_ema(ema_model, model)
train_loss += loss.detach().item() * img_24.size(0)
psnr_train += psnr(predicted_peak, img_peak, torch.max(predicted_peak))
pbar.set_postfix(MSE=loss.detach().item())
# Delete
del loss
del predicted_peak
# logger.add_scalar("MSE", loss.item(), global_step=epoch * len(pbar) + i)
# Clean up memory before validation
torch.cuda.empty_cache()
gc.collect()
# Validation step
valid_loss = 0.0
psnr_val = 0.0
pbar_val = tqdm(val_data)
model.eval()
with torch.no_grad():
for i, (image_94, image_peak) in enumerate(pbar_val):
img_24 = image_94.to(device).float().reshape(image_94.shape[0], 1, 1024, 1024)
img_peak = image_peak.to(device).float().reshape(image_peak.shape[0], 1, 1024, 1024)
labels = None
t = torch.rand(size=(img_peak.shape[0],)).to(device)
#t = diffusion.sample_timesteps(img_peak.shape[0]).to(device)
with autocast():
fct = t[:, None, None, None]
transformed_image = (1-fct)*img_24 + fct*img_peak
predicted_peak = model(transformed_image, labels, t).reshape(img_24.shape[0], 1, 1024, 1024)
# t = t[:, None, None, None]
# x_t = (1-t) * img_24 + t * predicted_peak
loss = mse(img_peak, predicted_peak)
valid_loss += loss.detach().item() * img_24.size(0)
psnr_val += psnr(predicted_peak, img_peak, torch.max(predicted_peak))
# Delete
del loss
del predicted_peak
I am monitoring with the WandB tool and these are the images of the GPU utilization I was speaking before:
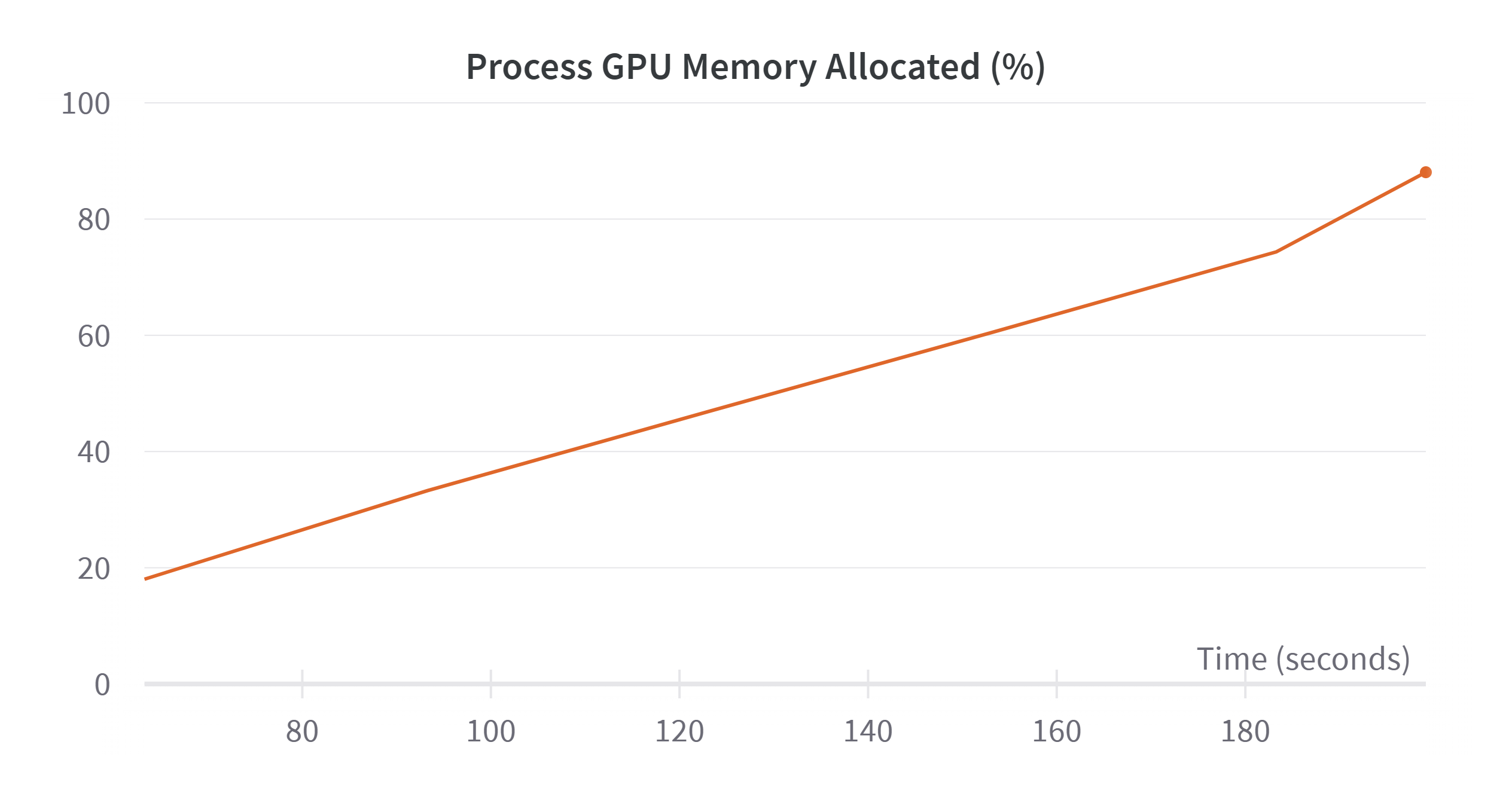
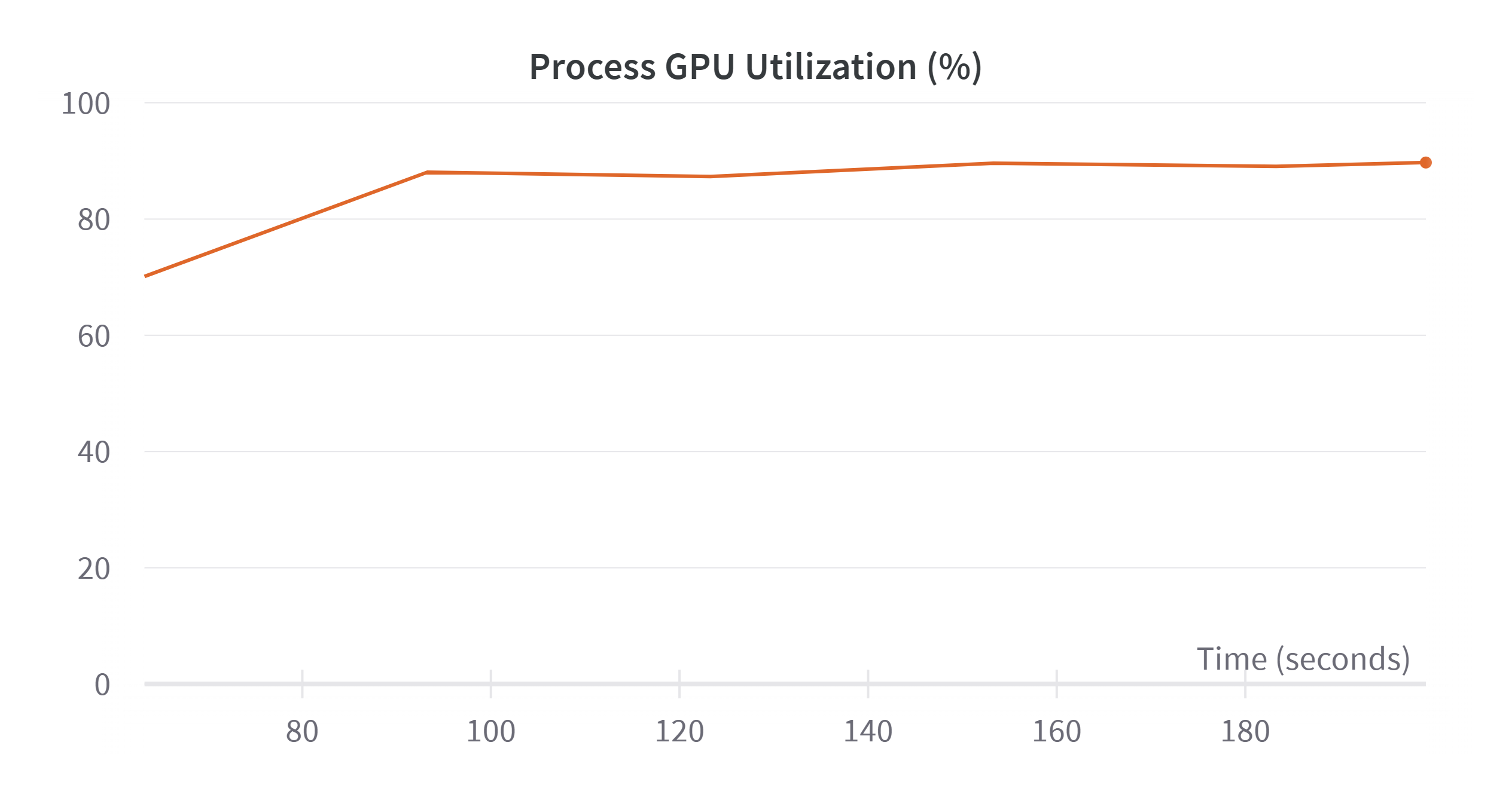
What could I do to mitigate this problem?
I tried the very same architecture and the very same training/validation loop on a different data and I do not have this problem, so i think is how I manage the data.