Name Self CPU % Self CPU CPU total % CPU total CPU time avg CPU Mem Self CPU Mem CUDA Mem Self CUDA Mem # of Calls
aten::resize_ 0.10% 69.000us 0.10% 69.000us 8.625us 0 b 0 b 4.74 Gb 4.74 Gb 8
aten::cat 0.04% 27.000us 0.22% 159.000us 39.750us 0 b 0 b 4.73 Gb 0 b 4
aten::_cat 0.08% 60.000us 0.19% 132.000us 33.000us 0 b 0 b 4.73 Gb 0 b 4
attention_embedding2 0.13% 90.000us 0.74% 523.000us 523.000us -4 b -4 b 4.71 Gb 0 b 1
aten::mul 0.18% 129.000us 0.23% 162.000us 23.143us 0 b 0 b 1.57 Gb 1.57 Gb 7
attention_embedding1 0.08% 54.000us 0.16% 112.000us 112.000us -4 b -4 b 1.56 Gb 0 b 1
aten::empty 0.70% 498.000us 0.70% 498.000us 4.835us 2.19 Kb 2.19 Kb 235.99 Mb 235.99 Mb 103
aten::lstm 0.15% 109.000us 92.66% 65.808ms 16.452ms 0 b 0 b 94.76 Mb 0 b 4
aten::_cudnn_rnn 35.10% 24.929ms 92.45% 65.656ms 16.414ms 0 b 0 b 94.76 Mb -135.34 Mb 4
output_embedding 0.54% 380.000us 14.40% 10.229ms 10.229ms -4 b -372 b 58.78 Mb -31.27 Mb 1
I reimplemented Bidaf by myself.
I’ve been having trouble dealing with GPU memory leak
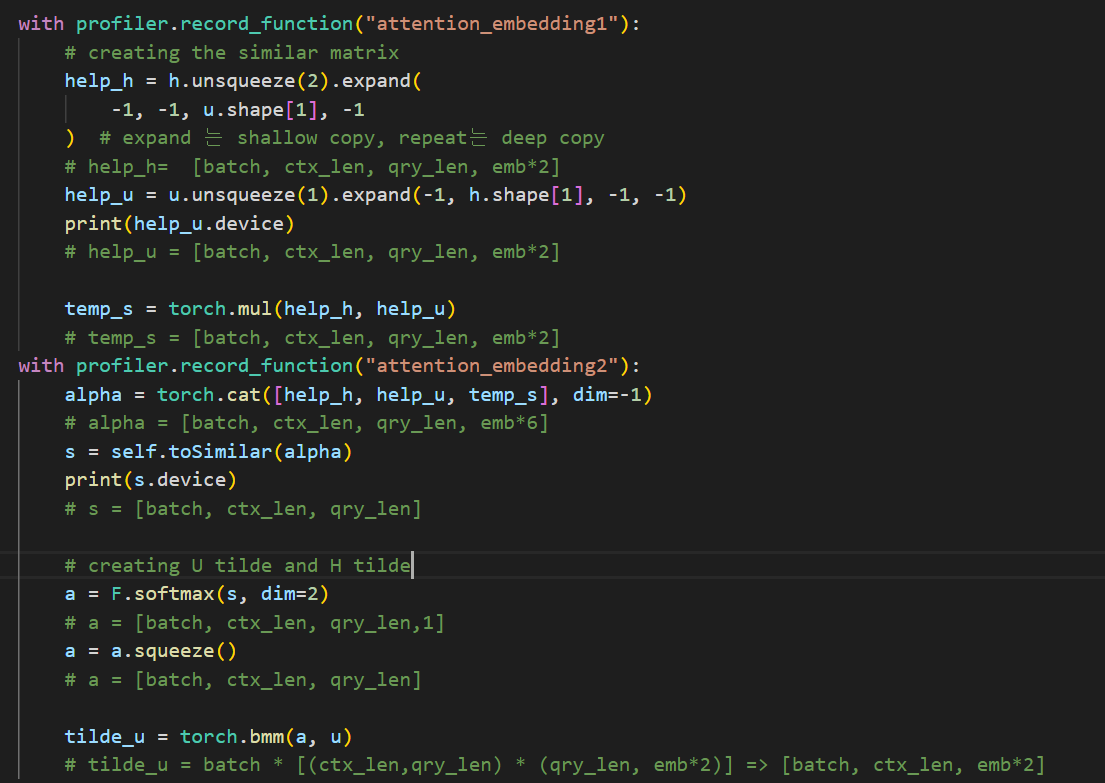
The first image I attached is the codes inside model’s forward function
The table is created by pytorch profiler.
Only a few codes occupy 4GB memory, especially torch.cat.
I’ve been trying to look up the solution to fix it, I haven’t made it.
Is there anyone who knows how to fix it??