Hi guys,
I have implemented a model which seems to be working. Howeverm when I kill it, with kill PID, the gpu memory is not freed:
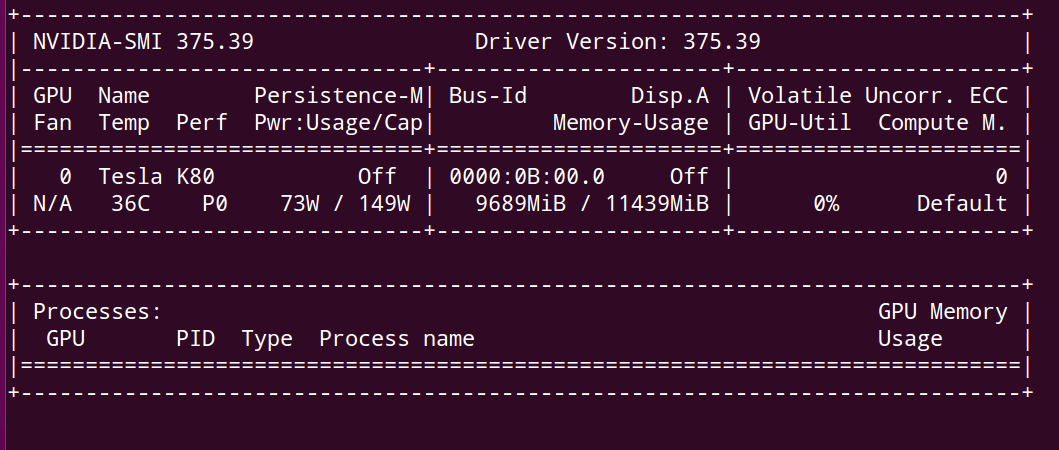
As you can see, there is some memory used and there is no process running.
Here’s the code that I am running:
class seg_GAN(object):
def __init__(self, batch_size=10, height=512,width=512,channels=3, wd=0.0005,nfilters_d=64, checkpoint_dir=None, path_imgs=None, learning_rate=2e-8,lr_step=30000,lam_fcn=1, lam_adv=1,adversarial=False,nclasses=5):
self.adversarial=adversarial
self.channels=channels
self.lam_fcn=lam_fcn
self.lam_adv=lam_adv
self.lr_step=lr_step
self.wd=wd
self.learning_rate=learning_rate
self.batch_size=batch_size
self.height=height
self.width=width
self.checkpoint_dir = checkpoint_dir
self.path_imgs=path_imgs
self.nfilters_d=nfilters_d
self.organ_target=1#1 eso 2 heart 3 trach 4 aorta
self.nclasses=nclasses
self.netG=UNet(self.nclasses,self.channels)
self.netG.apply(weights_init)
if self.adversarial:
self.netD=Discriminator(self.nclasses,self.nfilters_d,self.height,self.width)
self.netD.apply(weights_init)
self.dst = stanfordDataSet(self.path_imgs, is_transform=True)
self.trainloader = data.DataLoader(self.dst, batch_size=self.batch_size, shuffle=True, num_workers=2)
def train(self,config):
print 'verion ',torch.__version__
start=0#TODO change this so that it can continue when loading a model
print("Start from:", start)
label_ones=torch.ones(self.batch_size)
label_zeros=torch.zeros(self.batch_size)
y_onehot = torch.FloatTensor(self.batch_size,self.nclasses,self.height, self.width)
#print 'shape y_onehot ',y_onehot.size()
if self.adversarial:
self.netD.cuda()
self.netG.cuda()
label_ones,label_zeros,y_onehot=label_ones.cuda(),label_zeros.cuda(),y_onehot.cuda()
y_onehot_var= Variable(y_onehot)
label_ones_var = Variable(label_ones)
label_zeros_var = Variable(label_zeros)
if self.adversarial:
optimizerD = optim.Adam(self.netD.parameters(), lr = self.learning_rate, betas = (0.5, 0.999))
optimizerG = optim.Adam(self.netG.parameters(), lr = self.learning_rate, betas = (0.5, 0.999))
for it in range(start,config.iterations):#epochs
for i, (images,GT) in enumerate(self.trainloader):
y_onehot.resize_(GT.size(0),self.nclasses,self.height, self.width)
y_onehot.zero_()
label_ones.resize_(GT.size(0))
label_zeros.resize_(GT.size(0))
images = Variable(images.cuda())
#images = Variable(images)
#print 'unique ',np.unique(GT.numpy())
GT=GT.cuda()
#print 'image size ',images.size()
#print 'GT size ',GT.size()
#print 'shape y_onehot ',y_onehot.size()
y_onehot.scatter_(1,GT.view(GT.size(0),1,GT.size(1),GT.size(2)),1)#we need to add singleton dim so thatnum of dims is equal
#GT=Variable(GT.cuda())#N,H,W
GT=Variable(GT)#N,H,W
if self.adversarial:
##########################
#Update Discriminator
##########################
#train with real samples
self.netD.zero_grad()
#print self.netD
output=self.netD(y_onehot_var)#this must be in one hot
errD_real =F.binary_cross_entropy(output,label_ones_var)#loss_D
errD_real.backward()#update grads of netD
# train with fake
fake = self.netG(images)#this is a prob map which we want to be similar to y_onehot
#print 'fake sz',fake.size()
output = self.netD(fake.detach())#only for speed, so grads of netg are not computed
errD_fake = F.binary_cross_entropy(output, label_zeros_var)
errD_fake.backward()
optimizerD.step()#update the parameters of netD
############################
# Update G network
###########################
self.netG.zero_grad()
if self.adversarial:
output_D=self.netD(fake)
output_G, GT,label_ones,output_D
errG = self.loss_G(fake,GT, label_ones_var,output_D)#here we should use ones with the fakes
else:
fake = self.netG(images)
errG = self.loss_G(fake,GT)
errG.backward()#backprop errors
optimizerG.step()#optimize only netG params
if i%10==0:
print 'epoch ',it
print 'iteration ',i
if self.adversarial:
print 'error real ',errD_real.data
print 'error fake ',errD_fake.data
print 'error Generator ',errG.data
if it%5==0:
print 'testing ...'
name_img='0000047'
meanval=self.dst.mean_rgb
img_test_name=os.path.join(self.path_imgs,'iccv09Data',"images_resized",name_img+'.png')
lab_test_name=os.path.join(self.path_imgs,'iccv09Data',"labels_resized",name_img+'_label.png')
img = Image.open(img_test_name)
img = np.array(img, dtype=np.uint8)
label = Image.open(lab_test_name)
label = np.array(label, dtype=np.uint8)
img = img.astype(np.float32)
img -= meanval
img = img.transpose(2, 0, 1)
img_ = torch.from_numpy(img)#.float()
img_=img_.cuda()
img_var=Variable(img_)
prob_map = self.netG(img_var.view(1,img_.size(0),img_.size(1),img_.size(2)))
prob_np=prob_map.data.cpu().numpy()
prob_np=np.squeeze(prob_np)
label_out=np.argmax(prob_np,0)
print 'unique labout ',np.unique(label_out)
print 'probmap ',prob_map.size()
lab_visual=label2color(label_out)
imsave('out_color.png',lab_visual)
for idlabel in np.unique(label):
diceratio=dice(label, label_out,idlabel)
print 'dice id {} '.format(idlabel),diceratio
def loss_G(self,output_G, GT,label_ones=None,output_D=None):
fcnterm=CrossEntropy2d(output_G,GT)
if self.adversarial:
bceterm=F.binary_cross_entropy(output_D,label_ones)
return fcnterm+self.lam_adv*bceterm
else:
return fcnterm
I tested on 2 different machinesand the same problem is happening. What am I doing wrong? Thanks!!
