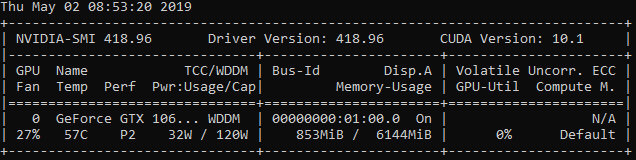
It does change to 3%, 5% sometimes, then back to 0%.
I have various cnn models (none producing great results yet). Shallow and deep, none use GPU like I want it to.
example shallow model:
class CNN1(nn.Module):
def __init__(self):
super(CNN1, self).__init__()
self.layer1 = nn.Sequential(nn.Conv2d(1, 10, 5, 1),
nn.ReLU(),
nn.MaxPool2d(2, 2))
self.fc1 = nn.Linear(170, 2)
def forward(self, x):
x = x.unsqueeze(1)
x = self.layer1(x)
x = x.reshape(x.size(0), -1)
x = self.fc1(x)
return x
example deeper model:
class CNN2(nn.Module):
def __init__(self):
super(CNN2, self).__init__()
self.layer1 = nn.Sequential(
nn.Conv2d(1, 32, kernel_size=5, stride=1, padding=2),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2))
self.layer2 = nn.Sequential(
nn.Conv2d(32, 64, kernel_size=5, stride=1, padding=2),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2))
self.drop_out = nn.Dropout(0.5)
self.fc1 = nn.Linear(576, 1000)
self.fc2 = nn.Linear(1000, 1000)
self.fc3 = nn.Linear(1000, 100)
self.fc4 = nn.Linear(100, 2)
def forward(self, x):
x = x.unsqueeze(1)
out = self.layer1(x)
out = self.layer2(out)
out = out.reshape(out.size(0), -1)
out = out.float()
out = self.drop_out(out)
out = self.fc1(out)
out = self.fc2(out)
out = self.fc3(out)
out = self.fc4(out)
return out
The CNN2 model sometimes shows 14%, 24%, then 0% mostly. But Task Manager performance still shows 0% for GPU 
I am loading data by loading files in getitem() … Is this causing it?