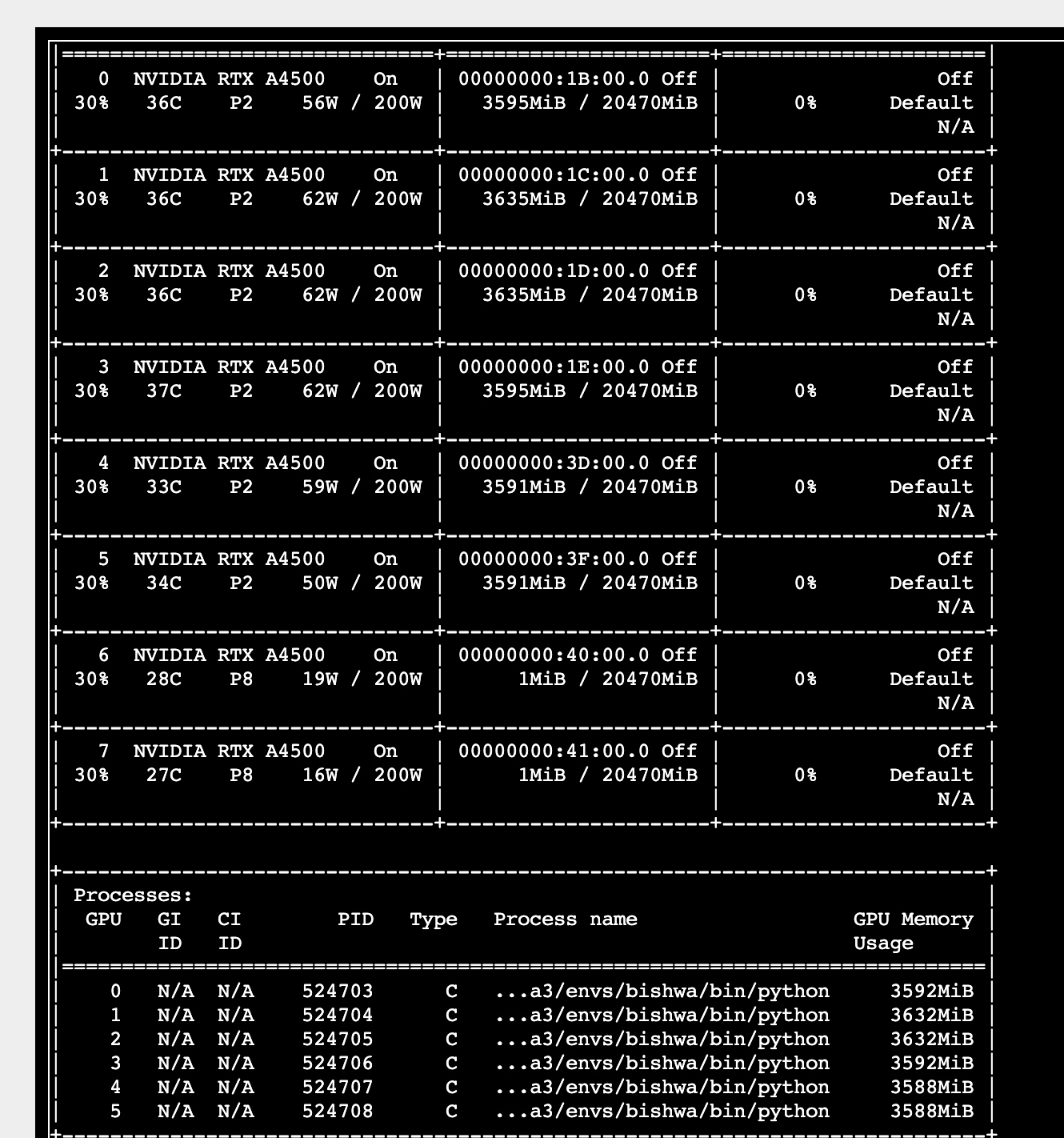
Hello everyone,
I tried using distributed training using the following code:
def ddp_setup(rank, world_size):
os.environ["MASTER_ADDR"] = "localhost"
os.environ["MASTER_PORT"] = '12355'
init_process_group(backend='nccl', rank=rank, world_size=world_size)
torch.cuda.set_device(rank)
class Trainer:
def __init__(self, model, train_data, val_data, optimizer, gpu_id, save_every):
self.gpu_id = gpu_id
self.model = model.to(gpu_id)
self.train_data = train_data
self.val_data = val_data
self.optimizer = optimizer
self.save_every = save_every
self.model = DDP(model, device_ids=[gpu_id], find_unused_parameters=True)
def _run_batch(self, source, targets):
self.optimizer.zero_grad()
output = self.model(source)
loss = F.cross_entropy(output, targets)
loss.backward()
self.optimizer.step()
return loss
def _run_epoch(self, epoch):
b_sz = len(next(iter(self.train_data))[0])
# print(f"GPU{self.gpu_id}] Epoch {epoch} | Batchsize: {b_sz} | Steps: {len(self.train_data)}")
self.train_data.sampler.set_epoch(epoch)
loss_ = []
for source, targets in self.train_data:
source = source.to(self.gpu_id)
targets = targets.to(self.gpu_id)
loss = self._run_batch(source, targets)
loss_.append(loss.item())
return np.mean(loss_)
def _run_val_epoch(self, epoch):
b_sz = len(next(iter(self.val_data))[0])
# print(f"[GPU{self.gpu_id}] Epoch {epoch} | Batchsize: {b_sz} | Steps: {len(self.train_data)}")
self.val_data.sampler.set_epoch(epoch)
loss_ = []
for source, targets in self.val_data:
source = source.to(self.gpu_id)
targets = targets.to(self.gpu_id)
output = self.model(source)
loss = F.cross_entropy(output, targets)
loss_.append(loss.item())
return np.mean(loss_)
def _save_checkpoint(self, epoch):
ckp = self.model.module.state_dict()
PATH = "ddp_checkpoint.pt"
torch.save(ckp, PATH)
print(f"Epoch {epoch} | Training checkpoint saved at {PATH}")
def train(self, max_epochs):
total_loss = {}
total_loss['train_loss'] = []
total_loss['val_loss'] = []
for epoch in range(max_epochs):
train_loss = self._run_epoch(epoch)
val_loss = self._run_val_epoch(epoch)
total_loss['train_loss'].append(train_loss)
total_loss['val_loss'].append(val_loss)
print(f"Epoch: {epoch}")
print(f"train loss: {train_loss}, val_loss: {val_loss}")
if self.gpu_id == 0 and epoch % self.save_every == 0:
self._save_checkpoint(epoch)
with open('loss.txt', 'w') as f:
f.write(str(total_loss))
f.close()
class Classifier(nn.Module):
''' this is a classifier'''
def __init__(self):
def forward(self, input)
def load_train_objs():
img_pth = '/home/images/'
train_df = '/home/train_df.csv'
val_df = '/home/val_df.csv'
train_set = LoadData(img_pth, train_df,
transform=T.Compose([T.Resize(size=(224, 224), antialias=True), T.Normalize(mean=(0.5), std=(0.5)), T.ToPILImage()]))
val_set = LoadData(img_pth, val_df,
transform=T.Compose([T.Resize(size=(224, 224), antialias=True), T.Normalize(mean=(0.5), std=(0.5)), T.ToPILImage()]))
model = Classifier()
optimizer = optim.Adam(params=model.parameters(), lr=1e-7, weight_decay= 1e-3)
return train_set,val_set, model, optimizer
def prepare_dataloader(dataset, batch_size):
return DataLoader(dataset, batch_size=batch_size, pin_memory=True, shuffle=False, sampler=DistributedSampler(dataset))
def main(rank, world_size, save_every, total_epochs, batch_size):
ddp_setup(rank, world_size)
train_dataset, val_dataset, model, optimizer = load_train_objs()
train_data = prepare_dataloader(train_dataset, batch_size)
val_data = prepare_dataloader(val_dataset, batch_size)
trainer = Trainer(model, train_data, val_data, optimizer, rank, save_every)
trainer.train(total_epochs)
destroy_process_group()
if __name__=='__main__':
import argparse
parser = argparse.ArgumentParser(description="distributed training")
parser.add_argument("total_epochs", type=int)
parser.add_argument("save_every", type=int)
parser.add_argument("--batch_size", type=int, default=32)
args = parser.parse_args()
world_size = torch.cuda.device_count()
mp.spawn(main, args=(world_size, args.save_every, args.total_epochs, args.batch_size), nprocs=world_size)
And with the python distributed.py 100 10 I am running the code but it only uses the memory not the gpu.