Hello all.
Here again, still new to PyTorch so bear with me here.
I’m trying to train a network for the purpose of segmentation of 1 class. Namely humans. I got some pretty good results using resnet+unet as found on this repo; Repo ; The problem is that I’m now trying to add more data and when trying I noticed the gpu isn’t being fully used. I played around with the batch size and also noticed that its being fully used on big batch sizes and not on small ones. So is there another bottleneck I presume? (for small batches?)
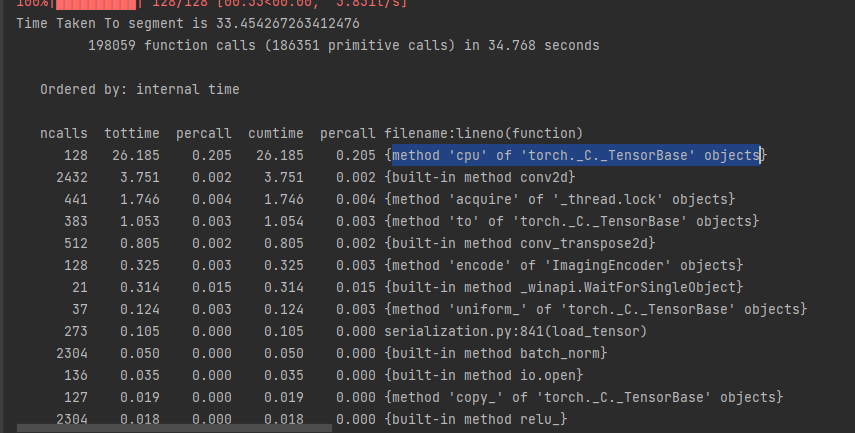
This is the (top)output of profiling on a very small subset, with less than 30% GPU utilization:
Tell me if I’m wrong here, but decode is prolly splitting my .png images in triple channel?
ncalls tottime percall cumtime percall filename:lineno(function)
26202 16.601 0.001 16.601 0.001 {method 'decode' of 'ImagingDecoder' objects}
1616 11.061 0.007 11.172 0.007 {method 'to' of 'torch._C._TensorBase' objects}
500 7.693 0.015 7.693 0.015 {method 'run_backward' of 'torch._C._EngineBase' objects}
2034 7.032 0.003 7.032 0.003 {method 'convert' of 'ImagingCore' objects}
1620 5.496 0.003 5.496 0.003 {method 'cpu' of 'torch._C._TensorBase' objects}
17820 3.803 0.000 3.803 0.000 {built-in method conv2d}
86000 3.200 0.000 3.200 0.000 {method 'mul_' of 'torch._C._TensorBase' objects}
86000 3.065 0.000 3.065 0.000 {method 'add_' of 'torch._C._TensorBase' objects}
43000 2.309 0.000 2.309 0.000 {method 'sqrt' of 'torch._C._TensorBase' objects}
10800 1.537 0.000 1.537 0.000 {built-in method batch_norm}
43000 1.438 0.000 1.438 0.000 {method 'addcdiv_' of 'torch._C._TensorBase' objects}
2160 1.432 0.001 1.432 0.001 {method 'resize' of 'ImagingCore' objects}
43000 1.393 0.000 1.393 0.000 {method 'addcmul_' of 'torch._C._TensorBase' objects}
2432 1.170 0.000 1.170 0.000 {method '_write_file' of 'torch._C.CudaFloatStorageBase' objects}
46428 1.072 0.000 1.072 0.000 {method 'zero_' of 'torch._C._TensorBase' objects}
560 0.750 0.001 0.750 0.001 {method 'copy' of 'ImagingCore' objects}
10800 0.719 0.000 28.263 0.003 Trainer.py:61(__getitem__)
500 0.603 0.001 12.074 0.024 adam.py:49(step)
15660 0.559 0.000 0.559 0.000 {built-in method threshold_}
97619 0.495 0.000 0.495 0.000 {method 'read' of '_io.BufferedReader' objects}
10800 0.484 0.000 2.160 0.000 batchnorm.py:58(forward)
2700 0.337 0.000 0.337 0.000 {built-in method cat}
540 0.286 0.001 0.286 0.001 {built-in method binary_cross_entropy_with_logits}
2196 0.245 0.000 0.245 0.000 {built-in method io.open}
4320 0.220 0.000 4.246 0.001 resnet.py:38(forward)
The code is the following;
'''
Overwriting the pytorch dataset
'''
class QCDataset(Dataset):
def __init__(self, paths, numberOfItems=1, transform=None):
self.paths = paths
self.transform = transform
ds = qc_ds.Dataset(0, 0, 0, 0)
(frontImages, frontMasks, sideImages, sideMasks) = ds.get_file_names(paths)
self.frontImages = frontImages[0:numberOfItems]
self.frontMasks = frontMasks[0:numberOfItems]
self.images = [None] * numberOfItems
self.masks = [None] * numberOfItems
self.length = numberOfItems
def __len__(self):
return self.length
def __getitem__(self, idx):
if( self.images[idx] is None and self.masks[idx] is None ):
image = Image.open(self.frontImages[idx]).convert('RGB')
mask = Image.open(self.frontMasks[idx]).convert('1')
image = self.transform(image)
mask = mask.resize((input_size, input_size))
mask = torch.tensor(np.asarray(mask, dtype=np.uint8))
self.images[idx] = image
self.masks[idx] = mask
return self.images[idx], self.masks[idx]
def calc_loss(pred, target, metrics, bce_weight=0.5):
pred = pred.squeeze(1)
bce = F.binary_cross_entropy_with_logits(pred, target)
pred = F.sigmoid(pred)
dice = dice_loss(pred, target)
loss = bce * bce_weight + dice * (1 - bce_weight)
metrics['bce'] += bce.data.cpu().numpy() * target.size(0)
metrics['dice'] += dice.data.cpu().numpy() * target.size(0)
metrics['loss'] += loss.data.cpu().numpy() * target.size(0)
return loss
def print_metrics(metrics, epoch_samples, phase):
outputs = []
for k in metrics.keys():
outputs.append("{}: {:4f}".format(k, metrics[k] / epoch_samples))
print("{}: {}".format(phase, ", ".join(outputs)))
def train_model(model, optimizer, scheduler, num_epochs=25, dataloaders=None):
best_model_wts = copy.deepcopy(model.state_dict())
best_loss = 1e10
for epoch in range(num_epochs):
print('Epoch {}/{}'.format(epoch, num_epochs - 1))
print('-' * 10)
if epoch % 10 is 0:
printGPUStats()
since = time.time()
# Each epoch has a training and validation phase
for phase in ['train', 'val']:
if phase == 'train':
scheduler.step()
for param_group in optimizer.param_groups:
print("LR", param_group['lr'])
model.train() # Set model to training mode
else:
model.eval() # Set model to evaluate mode
metrics = defaultdict(float)
epoch_samples = 0
loss = None
for inputs, labels in dataloaders[phase]:
inputs = inputs.to(device)
labels = labels.to(device)
inputs = inputs.float()
labels = labels.float()
# print(inputs.shape,' ' , labels.shape)
# zero the parameter gradients
optimizer.zero_grad()
# forward
# track history if only in train
with torch.set_grad_enabled(phase == 'train'):
outputs = model(inputs)
# print(outputs.shape)
loss = calc_loss(outputs, labels, metrics)
# backward + optimize only if in training phase
if phase == 'train':
loss.backward()
optimizer.step()
# statistics
epoch_samples += inputs.size(0)
print_metrics(metrics, epoch_samples, phase)
epoch_loss = metrics['loss'] / epoch_samples
# deep copy the model
if phase == 'val' and epoch_loss < best_loss:
print("saving best model")
best_loss = epoch_loss
best_model_wts = copy.deepcopy(model.state_dict())
torch.save(model.state_dict(), './result/currentBest.h5')
time_elapsed = time.time() - since
print('{:.0f}m {:.0f}s'.format(time_elapsed // 60, time_elapsed % 60))
print('Best val loss: {:4f}'.format(best_loss))
# load best model weights
model.load_state_dict(best_model_wts)
return model
'''
Setup the model and train it.
'''
def continue_training(model_path, numberOfClasses=1, learningRate=1e-4, input_size=256, stepSize=100, numberOfEpochs=50, outputName='res_2.h5', loaders=None):
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
#model = UNet.UNet(n_class=numberOfClasses)
# model = FCN.FCN(n_class=1)
model = ResNetUNet.ResNetUNet(n_class=numberOfClasses)
model = model.to(device)
model.load_state_dict(torch.load(model_path))
model.cuda()
# check keras-like model summary using torchsummary
#summary(model, input_size=(3, input_size, input_size))
optimizer_ft = optim.Adam(filter(lambda p: p.requires_grad, model.parameters()), lr=learningRate)
exp_lr_scheduler = lr_scheduler.StepLR(optimizer_ft, step_size=stepSize, gamma=0.1)
model = train_model(model, optimizer_ft, exp_lr_scheduler, num_epochs=numberOfEpochs, dataloaders=loaders)
torch.save(model.state_dict(), output_path + outputName)
'''
Setup the model and train it.
'''
def new_training(numberOfClasses=1, learningRate=1e-4, input_size=256, stepSize=100, numberOfEpochs=50, outputName='res.h5', loaders=None):
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
#model = UNet.UNet(n_class=numberOfClasses)
#model = FCN.FCN(n_class=1)
model = ResNetUNet.ResNetUNet(n_class=1)
model = model.to(device)
model.cuda()
# check keras-like model summary using torchsummary
#summary(model, input_size=(3, input_size, input_size))
optimizer_ft = optim.Adam(filter(lambda p: p.requires_grad, model.parameters()), lr=learningRate)
exp_lr_scheduler = lr_scheduler.StepLR(optimizer_ft, step_size=stepSize, gamma=0.1)
model = train_model(model, optimizer_ft, exp_lr_scheduler, num_epochs=numberOfEpochs, dataloaders=loaders)
torch.save(model.state_dict(), output_path + outputName)
def printGPUStats():
print('Using device:', device)
print()
# Additional Info when using cuda
if device.type == 'cuda':
print(torch.cuda.get_device_name(0))
print('Memory Usage:')
print('Allocated:', round(torch.cuda.memory_allocated(0) / 1024 ** 3, 1), 'GB')
print('Cached: ', round(torch.cuda.memory_cached(0) / 1024 ** 3, 1), 'GB')
if __name__ == '__main__':
'''
Define some transforms
'''
trans = transforms.Compose([
transforms.Resize((input_size,input_size)),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]) # imagenet
])
ds = qc_ds.Dataset(0, 0, 0, 0)
#public_train_set = QCDataset(ds.getPublicTrainingPaths(), transform=trans, numberOfItems=2984)
#public_validation_set = QCDataset(ds.getPublicValidationPaths(), transform=trans, numberOfItems=1420)
#train_qc_set = QCDataset(ds.getPrivateTrainingPaths(), transform=trans, numberOfItems=1065)
#val_set = QCDataset(ds.getPrivateValidationPaths(), transform=trans, numberOfItems=20)
public_train_set = QCDataset(ds.getPublicTrainingPaths(), transform=trans, numberOfItems=2500)
public_validation_set = QCDataset(ds.getPublicValidationPaths(), transform=trans, numberOfItems=200)
train_qc_set = QCDataset(ds.getPrivateTrainingPaths(), transform=trans, numberOfItems=800)
val_set = QCDataset(ds.getPrivateValidationPaths(), transform=trans, numberOfItems=20)
batch_size = 20
public_dataloaders = {
'train': DataLoader(public_train_set, batch_size=batch_size, shuffle=True, num_workers=0),
'val': DataLoader(public_validation_set, batch_size=batch_size, shuffle=True, num_workers=0)
}
private_dataloaders = {
'train': DataLoader(train_qc_set, batch_size=batch_size, shuffle=True, num_workers=0),
'val': DataLoader(val_set, batch_size=batch_size, shuffle=True, num_workers=0)
}
out = 'tunet_model.h5'
out2 = 'double_trained_model.h5'
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
pr.enable()
new_training(numberOfClasses=1, learningRate=1e-4, input_size=256, stepSize=200, numberOfEpochs=500,outputName=out, loaders=public_dataloaders)
continue_training(output_path+out, numberOfClasses=1, learningRate=1e-4, input_size=256, stepSize=200, numberOfEpochs=500, outputName=out2, loaders=private_dataloaders)
pr.disable()
pr.print_stats(sort='time')