Two identical models implemented in different ways have discrepant performances. How to identify the possible causes and how to solve them?
From a learning perspective, I’m implementing a Variational Autoencoder in order to achieve a performance close to the implementation of AutoencoderKL. However, my implementation is not performing properly and I’m looking for help to understand the possible reasons for the bottleneck.
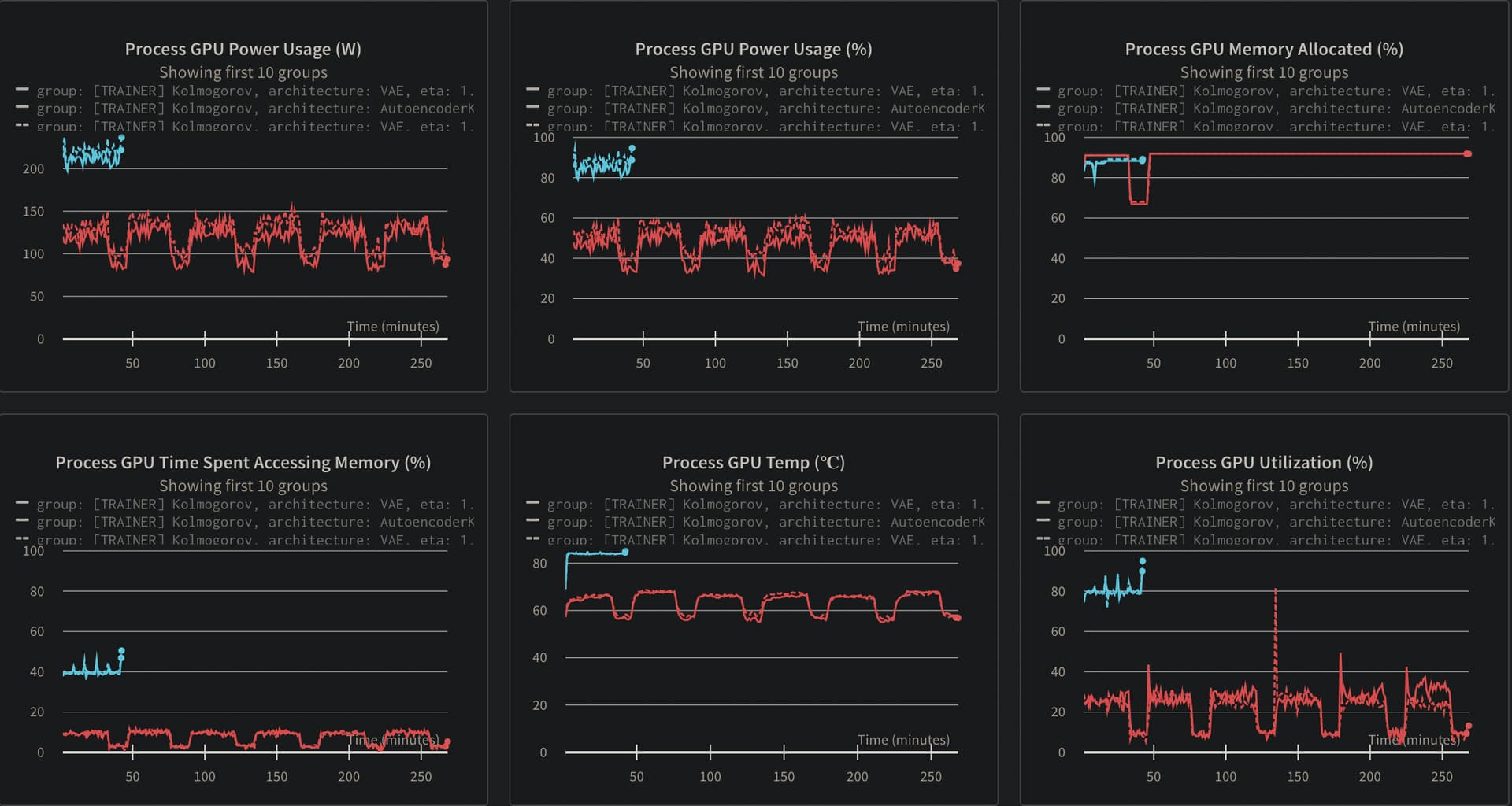
For context, here’s a comparison of GPU usage for the same run with the two different models. Although they are similar in terms of memory consumption, as the models have the same architecture, the use of the GPU in my implementation falls short. Furthermore, it is noted that, for the same number of epochs, the training time is 5-6x worse than the benchmark.
In addition, I profiled both runs with torch.profiler.profile. I have a lot of data in tensorboard from this profiling that I can share, I’m just not sure what information to share that might contribute to this diagnosis. If you have any suggestions on which views would be interesting, let me know and I’ll share them.
As a new user, I can only share one media in the post, however, I noticed a significant discrepancy when I look at the DIFF view on the tensorboard between both models. In this view, my model has a much higher execution than the benchmark.
Finally, both models share all training code, which includes DDP, AMP, and gradient norm clipping. Here is the code that is being used for training:
total = 0.
self.model.train()
self.train_data.sampler.set_epoch(epoch)
scaler = torch.cuda.amp.GradScaler()
for images, _ in data:
self.optimiser.zero_grad(set_to_none=True)
images = images.to(self.device)
with torch.autocast(device_type='cuda'
if torch.cuda.is_available() else 'cpu',
dtype=torch.float16):
if self.architecture == "AutoencoderKL":
posterior = self.model.module.encode(images).latent_dist
z = posterior.sample()
recon = self.model.module.decode(z).sample
else:
recon, posterior = self.model(images)
loss = (self.criterion()(recon, images) +
self.eta * posterior.kl().sum())
scaler.scale(loss).backward()
scaler.unscale_(self.optimiser)
torch.nn.utils.clip_grad_norm_(self.model.parameters(), 1.0)
scaler.step(self.optimiser)
scale = scaler.get_scale()
scaler.update()
self.optimiser.zero_grad(set_to_none=True)
total += loss.item() * images.size(0) / len(data.dataset)
del loss
if self.scheduler is not None:
if not scale > scaler.get_scale():
self.scheduler.step()
return total
Thanks in advance for the support. I am available for further clarification.

