Hi,
I am training a model and I saw that the GPU usage increases epoch after epoch, even by calling torch.cuda.empty_cache().
Here is a snippet of code:
for sample_id, (packed_blocks, packed_sequences) in tqdm(enumerate(data_loader)):
monitored_quantities = step(packed_blocks, packed_sequences, train=train)
means = {
key: value + means[key]
for key, value in monitored_quantities.items()
}
torch.cuda.empty_cache()
Before the first loop, GPU memory usage is 489MB. I assume it corresponds to the model stored in GPU. But at the beginning of each new loop, the GPU memory is higher and higher. And yet:
forward and backward pass are computed inside of step function
packed_blocks and packed_sequences are on CPU when the dataloader drops them, they are loaded on GPU inside of step function
monitored_quantities and means are dicts of floats
Since no new CUDA tensor is created in the scope of the for loop, I assume that after calling torch.cuda.empty_cache() the GPU memory usage would be the same than at the beginning of the iteration. But in practice it keeps growing.
Do the dicts contain CUDATensors or CPUTensors?
In the former case, you should detach them, if you don’t want to use them for the gradient calculation anymore, as they might store the whole computation graph otherwise.
Also, check your code for any storage of CUDATensors, which would be used for printing/logging purposes and are not detached.
Concerning the dicts, means is initialized as a defaultdict(float) and monitored_quantities is defined as {'loss': loss.item()}. So both dicts are dicts of Python floats, and none of them contain any tensor, whether on CPU or GPU.
Moreover, all operations I realize inside of the for loop are written in the snippet and in particular nothing is printed in the loop. I did not include the code of the step function because I assume that local tensors created in this function are out-of-scope and thus should be removed from GPU memory when I call torch.cuda.empty_cache(). Am I right on this point?
EDIT: I tried replacing loss.item() by loss.detach().cpu().item() in the monitored_quantities computation but it changed nothing.
I realized new experiments and it seems that my issue is somehow related to APEX!
When I do not use apex.amp, the GPU memory increases at the end of the first loop but then remains constant (489 MB before the first iteration and then 807MB at the beginning of all other iterations)
On the other hand, when I use apex.amp, the GPU memory seems to increase during the first iterations to some point (between 900MB and 1GB) and then varies in this interval.
Then my two questions are:
why does the GPU memory usage vary from one iteration to the other?
why the GPU memory usage is higher using apex than using standard PyTorch?
I don’t know to what extent it is still relevant to ask such question in this forum since it seems to be not directly related to PyTorch. Please tell me if you prefer me to close that topic and open an issue directly on apex repo.
I’m a bit confused regarding the initial issue.
Are you seeing an icreased memory usage in each epoch or just a varying one?
The latter case might be expected, especially if you are manually clearing the cache (which will not save any memory, but slow down your code).
Is the allocated memory higher using apex or just the reserved?
You can check it via torch.cuda.memory_allocated() and torch.cuda.memory_reserved().
The reserved memory might be higher, if some intermediate tensors are additionally created and it also depends on the opt_level you are using.
That being said, we recommend to check out the native mixed-precision implementation, which can be used by installing the nightly binaries or by building from source.
During the ~10 first iterations, the GPU memory increases, and after this it is varying but it seems to remain in the same interval. When I wrote this topic first, I measured the GPU usage only during the first epochs, hence the confusion.
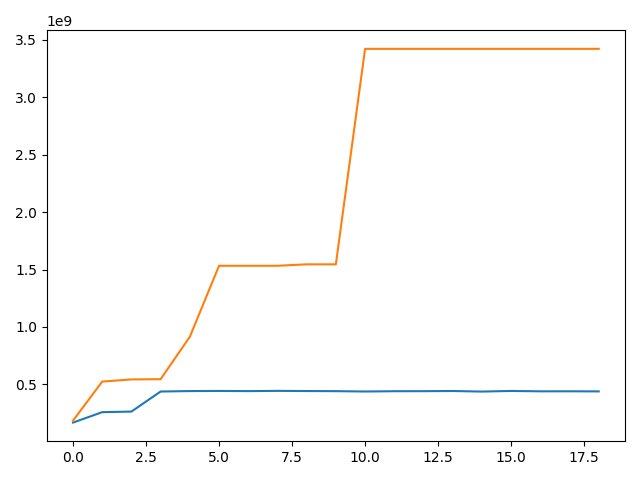
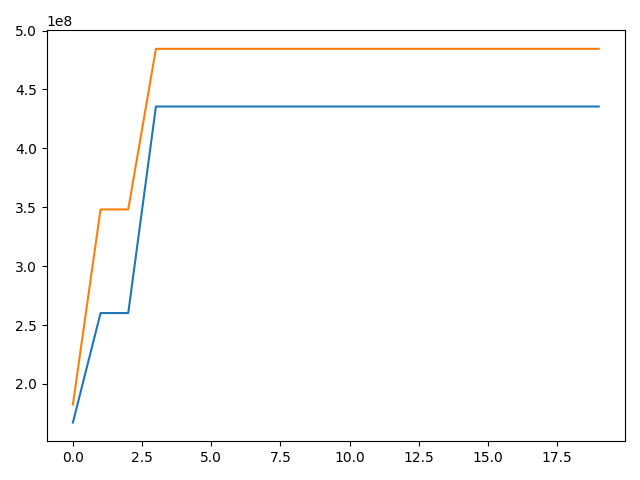
Here is a plot of the evolution of memory allocated (blue) and reserved (orange) as calculated by respectively torch.cuda.memory_allocated() and torch.cuda.memory_reserved() when I don’t call torch.cuda.empty_cache() at the end of each iter.
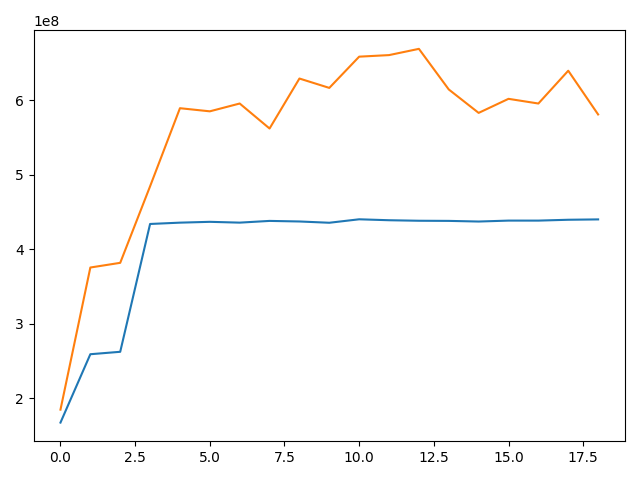
Here is a similar plot when I call torch.cuda.empty_cache() at the end of each iter:
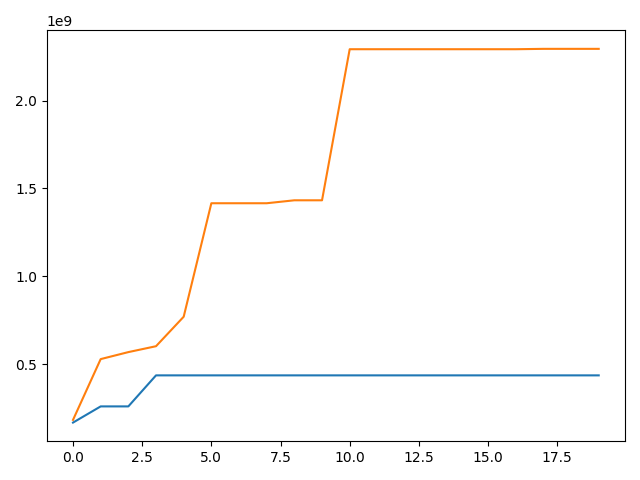
Finally, here is the GPU memory usage when I don’t use apex and I call empty_cache() at the end of each epoch:
Both allocated and reserved memories are higher using apex. I used opt_level O1.
I am aware that calling torch.cuda.empty_cache() does not reduce the memory usage but I assumed that it would enable me to get more accurate measurements (please tell me if it’s not the case). Before this answer, I only measured the GPU memory usage by looking at nvidia-smi.
Does those elements help you seeing what could be my problem?
Thanks a lot,
Alain
Thanks for the detailed analysis!
From the plots it seems that the allocated memory stays approx. at the same level.
Could you try the native amp implementation in PyTorch 1.6.0 and check the memory usage?
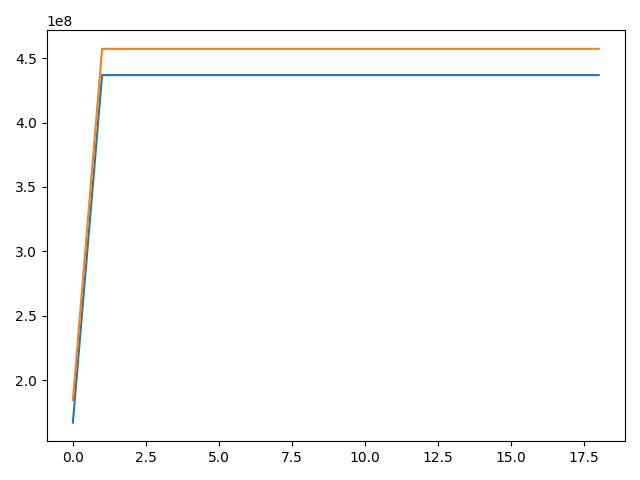
With the native AMP implementation, GPU memory usage seems to be stable.
Here is the plot without calling empty_cache():
Same when calling empty_cache():