Hello, I am doing feature extraction and fine tuning of an efficientnet_b0 model. I am using a machine with a Nvidia A10G, 16 CPUs and 64 Gb of RAM.
While training the gpu usage seems not to be stable. In fact, this is the output of nvidia-smi dmon :
gpu pwr gtemp mtemp sm mem enc dec mclk pclk
# Idx W C C % % % % MHz MHz
0 201 41 - 86 78 0 0 6250 1710
0 82 35 - 0 0 0 0 6250 1710
0 60 35 - 0 0 0 0 6250 1710
0 136 41 - 85 86 0 0 6250 1710
0 148 41 - 87 78 0 0 6250 1710
0 175 41 - 84 79 0 0 6250 1710
0 97 36 - 0 0 0 0 6250 1710
0 60 36 - 0 0 0 0 6250 1710
0 60 35 - 0 0 0 0 6250 1710
0 149 41 - 87 88 0 0 6250 1710
0 86 36 - 0 0 0 0 6250 1710
0 60 35 - 0 0 0 0 6250 1710
0 104 37 - 72 60 0 0 6250 1710
0 118 40 - 84 77 0 0 6250 1710
0 124 37 - 0 0 0 0 6250 1710
0 60 36 - 0 0 0 0 6250 1710
0 60 36 - 0 0 0 0 6250 1710
0 112 36 - 0 0 0 0 6250 1710
0 60 35 - 0 0 0 0 6250 1710
0 60 35 - 0 0 0 0 6250 1710
0 111 36 - 0 0 0 0 6250 1710
0 60 35 - 0 0 0 0 6250 1710
0 60 35 - 0 0 0 0 6250 1710
0 122 36 - 7 5 0 0 6250 1710
0 60 35 - 0 0 0 0 6250 1710
0 60 35 - 0 0 0 0 6250 1710
0 167 41 - 87 86 0 0 6250 1710
0 138 36 - 0 0 0 0 6250 1710
0 60 35 - 0 0 0 0 6250 1710
0 60 35 - 0 0 0 0 6250 1710
0 105 38 - 88 65 0 0 6250 1710
0 130 38 - 88 82 0 0 6250 1710
0 175 37 - 0 0 0 0 6250 1710
0 105 38 - 85 73 0 0 6250 1710
0 62 36 - 0 0 0 0 6250 1710
0 60 35 - 0 0 0 0 6250 1710
0 82 38 - 44 36 0 0 6250 1710
0 148 37 - 17 15 0 0 6250 1710
0 103 40 - 88 82 0 0 6250 1710
0 135 40 - 79 73 0 0 6250 1710
0 150 37 - 0 0 0 0 6250 1710
0 60 35 - 0 0 0 0 6250 1710
0 77 39 - 51 45 0 0 6250 1710
0 87 35 - 0 0 0 0 6250 1710
# gpu pwr gtemp mtemp sm mem enc dec mclk pclk
# Idx W C C % % % % MHz MHz
0 60 35 - 0 0 0 0 6250 1710
0 60 36 - 5 0 0 0 6250 1710
0 104 35 - 0 0 0 0 6250 1710
0 79 38 - 64 57 0 0 6250 1710
0 112 35 - 0 0 0 0 6250 1710
0 60 35 - 0 0 0 0 6250 1710
0 60 35 - 0 0 0 0 6250 1710
0 60 34 - 0 0 0 0 6250 1710
0 153 40 - 87 86 0 0 6250 1710
0 148 36 - 0 0 0 0 6250 1710
As you can see the GPU usage goes up for a while and then it goes back to 0.
The CPU usage is relatively low.
I am using a batch size of 448 images. It can’t be bigger because I am almost running out of VRAM. I initialize the data loaders with the following settings:
DataLoader(
..... dataset .....,
batch_size=448,
num_workers=..., # I tried different numbers from 16 to 448 * 2
pin_memory=True,
persistent_workers=True,
prefetch_factor=2 # I also tried to increase this
)
How can I increase the GPU usage? I was wondering if the performance I am seeing are expected. Maybe the low usage is caused by the model being relatively small and the batch size being relatively big: it takes more time to copy the data to the GPU than to process it.
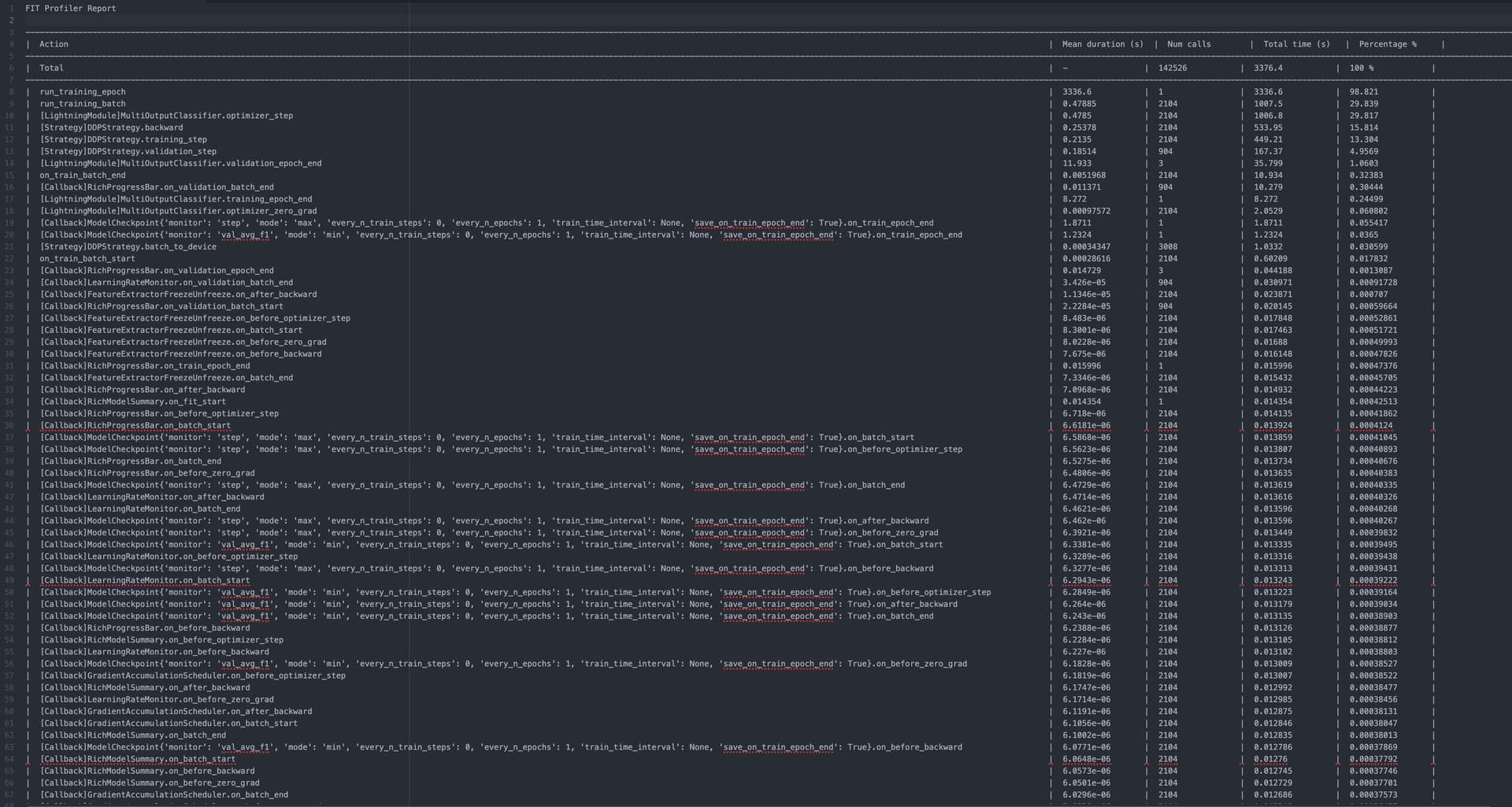
Since I am using Torch Lightning I tried to use its profiling functionalities. You can find the output of the profiling tool both as a text and as a screenshot attached. I didn’t include it all because it was too long.
FIT Profiler Report
--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
| Action | Mean duration (s) | Num calls | Total time (s) | Percentage % |
--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
| Total | - | 142526 | 3376.4 | 100 % |
--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
| run_training_epoch | 3336.6 | 1 | 3336.6 | 98.821 |
| run_training_batch | 0.47885 | 2104 | 1007.5 | 29.839 |
| [LightningModule]MultiOutputClassifier.optimizer_step | 0.4785 | 2104 | 1006.8 | 29.817 |
| [Strategy]DDPStrategy.backward | 0.25378 | 2104 | 533.95 | 15.814 |
| [Strategy]DDPStrategy.training_step | 0.2135 | 2104 | 449.21 | 13.304 |
| [Strategy]DDPStrategy.validation_step | 0.18514 | 904 | 167.37 | 4.9569 |
| [LightningModule]MultiOutputClassifier.validation_epoch_end | 11.933 | 3 | 35.799 | 1.0603 |
| on_train_batch_end | 0.0051968 | 2104 | 10.934 | 0.32383 |
| [Callback]RichProgressBar.on_validation_batch_end | 0.011371 | 904 | 10.279 | 0.30444 |
| [LightningModule]MultiOutputClassifier.training_epoch_end | 8.272 | 1 | 8.272 | 0.24499 |
| [LightningModule]MultiOutputClassifier.optimizer_zero_grad | 0.00097572 | 2104 | 2.0529 | 0.060802 |
| [Callback]ModelCheckpoint{'monitor': 'step', 'mode': 'max', 'every_n_train_steps': 0, 'every_n_epochs': 1, 'train_time_interval': None, 'save_on_train_epoch_end': True}.on_train_epoch_end | 1.8711 | 1 | 1.8711 | 0.055417 |
| [Callback]ModelCheckpoint{'monitor': 'val_avg_f1', 'mode': 'min', 'every_n_train_steps': 0, 'every_n_epochs': 1, 'train_time_interval': None, 'save_on_train_epoch_end': True}.on_train_epoch_end | 1.2324 | 1 | 1.2324 | 0.0365 |
| [Strategy]DDPStrategy.batch_to_device | 0.00034347 | 3008 | 1.0332 | 0.030599 |
| on_train_batch_start | 0.00028616 | 2104 | 0.60209 | 0.017832 |
| [Callback]RichProgressBar.on_validation_epoch_end | 0.014729 | 3 | 0.044188 | 0.0013087 |
| [Callback]LearningRateMonitor.on_validation_batch_end | 3.426e-05 | 904 | 0.030971 | 0.00091728 |
| [Callback]FeatureExtractorFreezeUnfreeze.on_after_backward | 1.1346e-05 | 2104 | 0.023871 | 0.000707 |
| [Callback]RichProgressBar.on_validation_batch_start | 2.2284e-05 | 904 | 0.020145 | 0.00059664 |
| [Callback]FeatureExtractorFreezeUnfreeze.on_before_optimizer_step | 8.483e-06 | 2104 | 0.017848 | 0.00052861 |
| [Callback]FeatureExtractorFreezeUnfreeze.on_batch_start | 8.3001e-06 | 2104 | 0.017463 | 0.00051721 |
| [Callback]FeatureExtractorFreezeUnfreeze.on_before_zero_grad | 8.0228e-06 | 2104 | 0.01688 | 0.00049993 |
| [Callback]FeatureExtractorFreezeUnfreeze.on_before_backward | 7.675e-06 | 2104 | 0.016148 | 0.00047826 |
| [Callback]RichProgressBar.on_train_epoch_end | 0.015996 | 1 | 0.015996 | 0.00047376 |
| [Callback]FeatureExtractorFreezeUnfreeze.on_batch_end | 7.3346e-06 | 2104 | 0.015432 | 0.00045705 |
| [Callback]RichProgressBar.on_after_backward | 7.0968e-06 | 2104 | 0.014932 | 0.00044223 |
| [Callback]RichModelSummary.on_fit_start | 0.014354 | 1 | 0.014354 | 0.00042513 |
| [Callback]RichProgressBar.on_before_optimizer_step | 6.718e-06 | 2104 | 0.014135 | 0.00041862 |
| [Callback]RichProgressBar.on_batch_start | 6.6181e-06 | 2104 | 0.013924 | 0.0004124 |
| [Callback]ModelCheckpoint{'monitor': 'step', 'mode': 'max', 'every_n_train_steps': 0, 'every_n_epochs': 1, 'train_time_interval': None, 'save_on_train_epoch_end': True}.on_batch_start | 6.5868e-06 | 2104 | 0.013859 | 0.00041045 |
| [Callback]ModelCheckpoint{'monitor': 'step', 'mode': 'max', 'every_n_train_steps': 0, 'every_n_epochs': 1, 'train_time_interval': None, 'save_on_train_epoch_end': True}.on_before_optimizer_step | 6.5623e-06 | 2104 | 0.013807 | 0.00040893 |
| [Callback]RichProgressBar.on_batch_end | 6.5275e-06 | 2104 | 0.013734 | 0.00040676 |
| [Callback]RichProgressBar.on_before_zero_grad | 6.4806e-06 | 2104 | 0.013635 | 0.00040383 |
| [Callback]ModelCheckpoint{'monitor': 'step', 'mode': 'max', 'every_n_train_steps': 0, 'every_n_epochs': 1, 'train_time_interval': None, 'save_on_train_epoch_end': True}.on_batch_end | 6.4729e-06 | 2104 | 0.013619 | 0.00040335 |
| [Callback]LearningRateMonitor.on_after_backward | 6.4714e-06 | 2104 | 0.013616 | 0.00040326 |
| [Callback]LearningRateMonitor.on_batch_end | 6.4621e-06 | 2104 | 0.013596 | 0.00040268 |
| [Callback]ModelCheckpoint{'monitor': 'step', 'mode': 'max', 'every_n_train_steps': 0, 'every_n_epochs': 1, 'train_time_interval': None, 'save_on_train_epoch_end': True}.on_after_backward | 6.462e-06 | 2104 | 0.013596 | 0.00040267 |
| [Callback]ModelCheckpoint{'monitor': 'step', 'mode': 'max', 'every_n_train_steps': 0, 'every_n_epochs': 1, 'train_time_interval': None, 'save_on_train_epoch_end': True}.on_before_zero_grad | 6.3921e-06 | 2104 | 0.013449 | 0.00039832 |
| [Callback]ModelCheckpoint{'monitor': 'val_avg_f1', 'mode': 'min', 'every_n_train_steps': 0, 'every_n_epochs': 1, 'train_time_interval': None, 'save_on_train_epoch_end': True}.on_batch_start | 6.3381e-06 | 2104 | 0.013335 | 0.00039495 |
| [Callback]LearningRateMonitor.on_before_optimizer_step | 6.3289e-06 | 2104 | 0.013316 | 0.00039438 |
| [Callback]ModelCheckpoint{'monitor': 'step', 'mode': 'max', 'every_n_train_steps': 0, 'every_n_epochs': 1, 'train_time_interval': None, 'save_on_train_epoch_end': True}.on_before_backward | 6.3277e-06 | 2104 | 0.013313 | 0.00039431 |
| [Callback]LearningRateMonitor.on_batch_start | 6.2943e-06 | 2104 | 0.013243 | 0.00039222 |
| [Callback]ModelCheckpoint{'monitor': 'val_avg_f1', 'mode': 'min', 'every_n_train_steps': 0, 'every_n_epochs': 1, 'train_time_interval': None, 'save_on_train_epoch_end': True}.on_before_optimizer_step | 6.2849e-06 | 2104 | 0.013223 | 0.00039164 |
| [Callback]ModelCheckpoint{'monitor': 'val_avg_f1', 'mode': 'min', 'every_n_train_steps': 0, 'every_n_epochs': 1, 'train_time_interval': None, 'save_on_train_epoch_end': True}.on_after_backward | 6.264e-06 | 2104 | 0.013179 | 0.00039034 |
| [Callback]ModelCheckpoint{'monitor': 'val_avg_f1', 'mode': 'min', 'every_n_train_steps': 0, 'every_n_epochs': 1, 'train_time_interval': None, 'save_on_train_epoch_end': True}.on_batch_end | 6.243e-06 | 2104 | 0.013135 | 0.00038903 |
| [Callback]RichProgressBar.on_before_backward | 6.2388e-06 | 2104 | 0.013126 | 0.00038877 |
| [Callback]RichModelSummary.on_before_optimizer_step | 6.2284e-06 | 2104 | 0.013105 | 0.00038812 |
| [Callback]LearningRateMonitor.on_before_backward | 6.227e-06 | 2104 | 0.013102 | 0.00038803 |
| [Callback]ModelCheckpoint{'monitor': 'val_avg_f1', 'mode': 'min', 'every_n_train_steps': 0, 'every_n_epochs': 1, 'train_time_interval': None, 'save_on_train_epoch_end': True}.on_before_zero_grad | 6.1828e-06 | 2104 | 0.013009 | 0.00038527 |
| [Callback]GradientAccumulationScheduler.on_before_optimizer_step | 6.1819e-06 | 2104 | 0.013007 | 0.00038522 |
| [Callback]RichModelSummary.on_after_backward | 6.1747e-06 | 2104 | 0.012992 | 0.00038477 |
| [Callback]LearningRateMonitor.on_before_zero_grad | 6.1714e-06 | 2104 | 0.012985 | 0.00038456 |
| [Callback]GradientAccumulationScheduler.on_after_backward | 6.1191e-06 | 2104 | 0.012875 | 0.00038131 |
| [Callback]GradientAccumulationScheduler.on_batch_start | 6.1056e-06 | 2104 | 0.012846 | 0.00038047 |
| [Callback]RichModelSummary.on_batch_end | 6.1002e-06 | 2104 | 0.012835 | 0.00038013 |
| [Callback]ModelCheckpoint{'monitor': 'val_avg_f1', 'mode': 'min', 'every_n_train_steps': 0, 'every_n_epochs': 1, 'train_time_interval': None, 'save_on_train_epoch_end': True}.on_before_backward | 6.0771e-06 | 2104 | 0.012786 | 0.00037869 |
| [Callback]RichModelSummary.on_batch_start | 6.0648e-06 | 2104 | 0.01276 | 0.00037792 |
| [Callback]RichModelSummary.on_before_backward | 6.0573e-06 | 2104 | 0.012745 | 0.00037746 |
| [Callback]RichModelSummary.on_before_zero_grad | 6.0501e-06 | 2104 | 0.012729 | 0.00037701 |
Thank you!
