Hi, I’m training faster RCNN with ResNet 50, I’m getting a question that whether my code completely utilize the GPU or not. When I monitored the task manager I see the GPU utilization is minimal or my understanding is wrong.
Can some help me to utilize the GPU maximum.
when I tried to add the num_workers I’m getting bottleneck error.
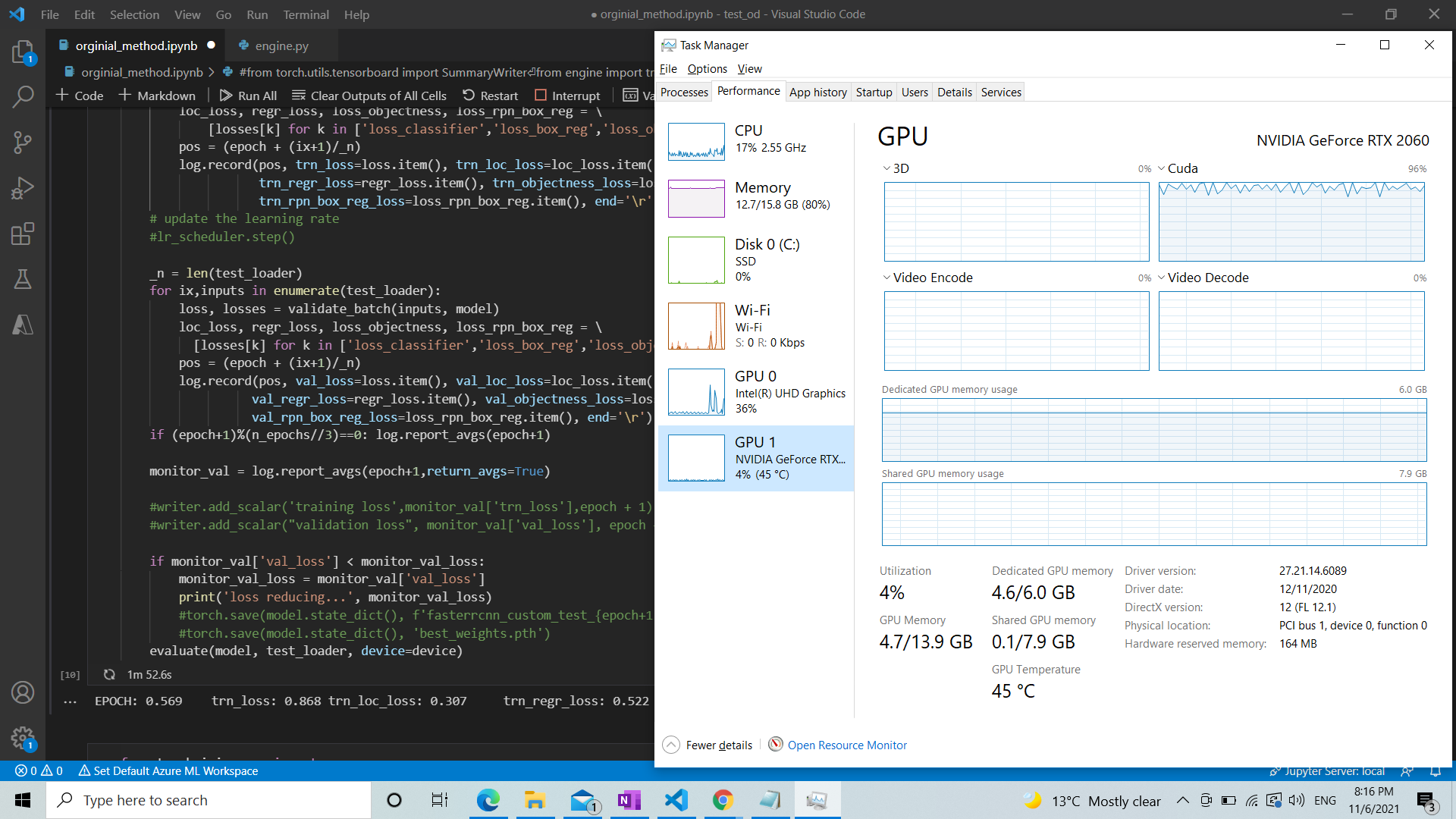
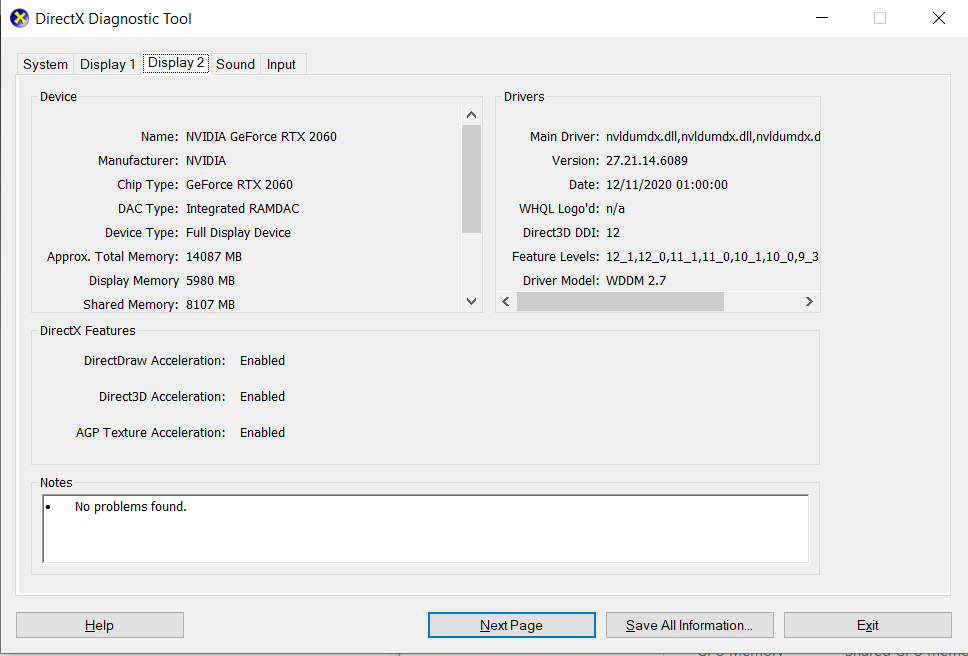
System configuration:
windows 10, GEFORCE RTX 2060, python 3.7.11, torch = 1.8.1
please find my code below
from torch_snippets import *
from PIL import Image
import glob, numpy as np, cv2, warnings,random, albumentations as A
from albumentations.pytorch.transforms import ToTensorV2
warnings.filterwarnings('ignore')
def seed_everything(seed):
random.seed(seed)
os.environ['PYTHONHASHSEED'] = str(seed)
np.random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = True
seed_everything(42)
IMAGE_ROOT = 'images'
DF_RAW = pd.read_csv('train_labels.csv')
DF_RAW['image_id'] = DF_RAW['filename'].apply(lambda x: x.split('.')[0])
DF_RAW['labels'] = DF_RAW['class'].apply(lambda x: 1 if x=='car' else 0)
label2target = {l:t+1 for t,l in enumerate(DF_RAW['class'].unique())}
label2target['background'] = 0
target2label = {t:l for l,t in label2target.items()}
background_class = label2target['background']
num_classes = len(label2target)
def preprocess_image(img):
img = torch.tensor(img).permute(2,0,1)
return img.to(device).float()
import torch
class OpenDataset(torch.utils.data.Dataset):
def __init__(self, df, image_folder=IMAGE_ROOT,transforms=None):
self.root = image_folder
self.df = df
self.unique_images = df['image_id'].unique()
self.transforms = transforms
def __len__(self): return len(self.unique_images)
def __getitem__(self, ix):
image_id = self.unique_images[ix]
image_id_ = torch.tensor([ix])
image_path = f'{image_id}.jpg'
img = Image.open('images/'+image_path).convert("RGB")
img = np.array(img)/255
df = self.df.copy()
df = df[df['image_id'] == image_id]
boxes = df[['xmin','ymin','xmax','ymax']].values
classes = df['class'].values
boxes = torch.as_tensor(boxes, dtype=torch.float32)
# area of the bounding boxes
area = (boxes[:, 3] - boxes[:, 1]) * (boxes[:, 2] - boxes[:, 0])
# no crowd instances
iscrowd = torch.zeros((boxes.shape[0],), dtype=torch.int64)
# labels to tensor
labels = torch.as_tensor([label2target[i] for i in classes],dtype=torch.int64)
# prepare the final `target` dictionary
target = {}
target["boxes"] = boxes
target["labels"] = labels
target["area"] = area
target["iscrowd"] = iscrowd
image_id = torch.tensor([image_id_])
target["image_id"] = image_id
# apply the image transforms
if self.transforms:
sample = self.transforms(image = img,
bboxes = target['boxes'],
labels = labels)
image_resized = sample['image']
target['boxes'] = torch.Tensor(sample['bboxes'])
img = preprocess_image(img)
return img, target
def collate_fn(self, batch):
return tuple(zip(*batch))
import albumentations as A
from albumentations.pytorch import ToTensorV2
def get_train_transform():
return A.Compose([
A.Flip(0.5),
A.RandomRotate90(0.5),
A.MotionBlur(p=0.2),
A.Blur(blur_limit=3, p=0.1),
ToTensorV2(p=1.0),
], bbox_params={
'format': 'pascal_voc',
'label_fields': ['labels']
})
# define the validation transforms
def get_valid_transform():
return A.Compose([
ToTensorV2(p=1.0),
], bbox_params={
'format': 'pascal_voc',
'label_fields': ['labels']
})
from sklearn.model_selection import train_test_split
trn_ids, val_ids = train_test_split(DF_RAW['image_id'].unique(), test_size=0.1, random_state=99)
trn_df, val_df = DF_RAW[DF_RAW['image_id'].isin(trn_ids)], DF_RAW[DF_RAW['image_id'].isin(val_ids)]
print(len(trn_df), len(val_df))
train_ds = OpenDataset(trn_df,transforms = get_train_transform())
test_ds = OpenDataset(val_df,transforms = get_valid_transform())
train_loader = DataLoader(train_ds, batch_size=2, collate_fn=train_ds.collate_fn, drop_last=False,shuffle=True)
#train_test_loader = DataLoader(train_ds, batch_size=1, collate_fn=train_ds.collate_fn, drop_last=False,shuffle=True)
test_loader = DataLoader(test_ds, batch_size=1, collate_fn=test_ds.collate_fn, drop_last=False,shuffle=False)
import torchvision
from torchvision.models.detection.faster_rcnn import FastRCNNPredictor
device = 'cuda' if torch.cuda.is_available() else 'cpu'
def get_model():
model = torchvision.models.detection.fasterrcnn_resnet50_fpn(pretrained=True)
in_features = model.roi_heads.box_predictor.cls_score.in_features
model.roi_heads.box_predictor = FastRCNNPredictor(in_features, num_classes)
return model
# Defining training and validation functions for a single batch
def train_batch(inputs, model, optimizer):
model.train()
input_, targets = inputs
input_ = list(image.to(device) for image in input_)
targets = [{k: v.to(device) for k, v in t.items()} for t in targets]
optimizer.zero_grad()
losses = model(input_, targets)
loss = sum(loss for loss in losses.values())
loss.backward()
optimizer.step()
return loss, losses
@torch.no_grad() # this will disable gradient computation in the function below
def validate_batch(inputs, model):
model.train() # to obtain the losses, model needs to be in train mode only. # #Note that here we are not defining the model's forward method
#and hence need to work per the way the model class is defined
input_, targets = inputs
input_ = list(image.to(device) for image in input_)
targets = [{k: v.to(device) for k, v in t.items()} for t in targets]
optimizer.zero_grad()
losses = model(input_, targets)
loss = sum(loss for loss in losses.values())
return loss, losses
model = get_model().to(device)
optimizer = torch.optim.SGD(model.parameters(), lr=0.005,
momentum=0.9, weight_decay=0.0005)
lr_scheduler = torch.optim.lr_scheduler.MultiStepLR(optimizer, milestones=[3,8], gamma=0.1)
n_epochs = 10
log = Report(n_epochs)
#from torch.utils.tensorboard import SummaryWriter
from engine import train_one_epoch, evaluate
#writer = SummaryWriter('runs/object_detection_1')
monitor_val_loss = float('inf')
for epoch in range(n_epochs):
_n = len(train_loader)
for ix, inputs in enumerate(train_loader):
loss, losses = train_batch(inputs, model, optimizer)
loc_loss, regr_loss, loss_objectness, loss_rpn_box_reg = \
[losses[k] for k in ['loss_classifier','loss_box_reg','loss_objectness','loss_rpn_box_reg']]
pos = (epoch + (ix+1)/_n)
log.record(pos, trn_loss=loss.item(), trn_loc_loss=loc_loss.item(),
trn_regr_loss=regr_loss.item(), trn_objectness_loss=loss_objectness.item(),
trn_rpn_box_reg_loss=loss_rpn_box_reg.item(), end='\r')
# update the learning rate
lr_scheduler.step()
_n = len(test_loader)
for ix,inputs in enumerate(test_loader):
loss, losses = validate_batch(inputs, model)
loc_loss, regr_loss, loss_objectness, loss_rpn_box_reg = \
[losses[k] for k in ['loss_classifier','loss_box_reg','loss_objectness','loss_rpn_box_reg']]
pos = (epoch + (ix+1)/_n)
log.record(pos, val_loss=loss.item(), val_loc_loss=loc_loss.item(),
val_regr_loss=regr_loss.item(), val_objectness_loss=loss_objectness.item(),
val_rpn_box_reg_loss=loss_rpn_box_reg.item(), end='\r')
if (epoch+1)%(n_epochs//10)==0: log.report_avgs(epoch+1)
monitor_val = log.report_avgs(epoch+1,return_avgs=True)
#writer.add_scalar('training loss',monitor_val['trn_loss'],epoch + 1)
#writer.add_scalar("validation loss", monitor_val['val_loss'], epoch + 1)
if monitor_val['val_loss'] < monitor_val_loss:
monitor_val_loss = monitor_val['val_loss']
print('loss reducing...', monitor_val_loss)
#torch.save(model.state_dict(), f'fasterrcnn_custom_test_{epoch+1}_loss_{monitor_val_loss}.pth')
#torch.save(model.state_dict(), 'best_weights.pth')
evaluate(model, test_loader, device=device)
can anyone guide me to utilize maximum GPU,please?
