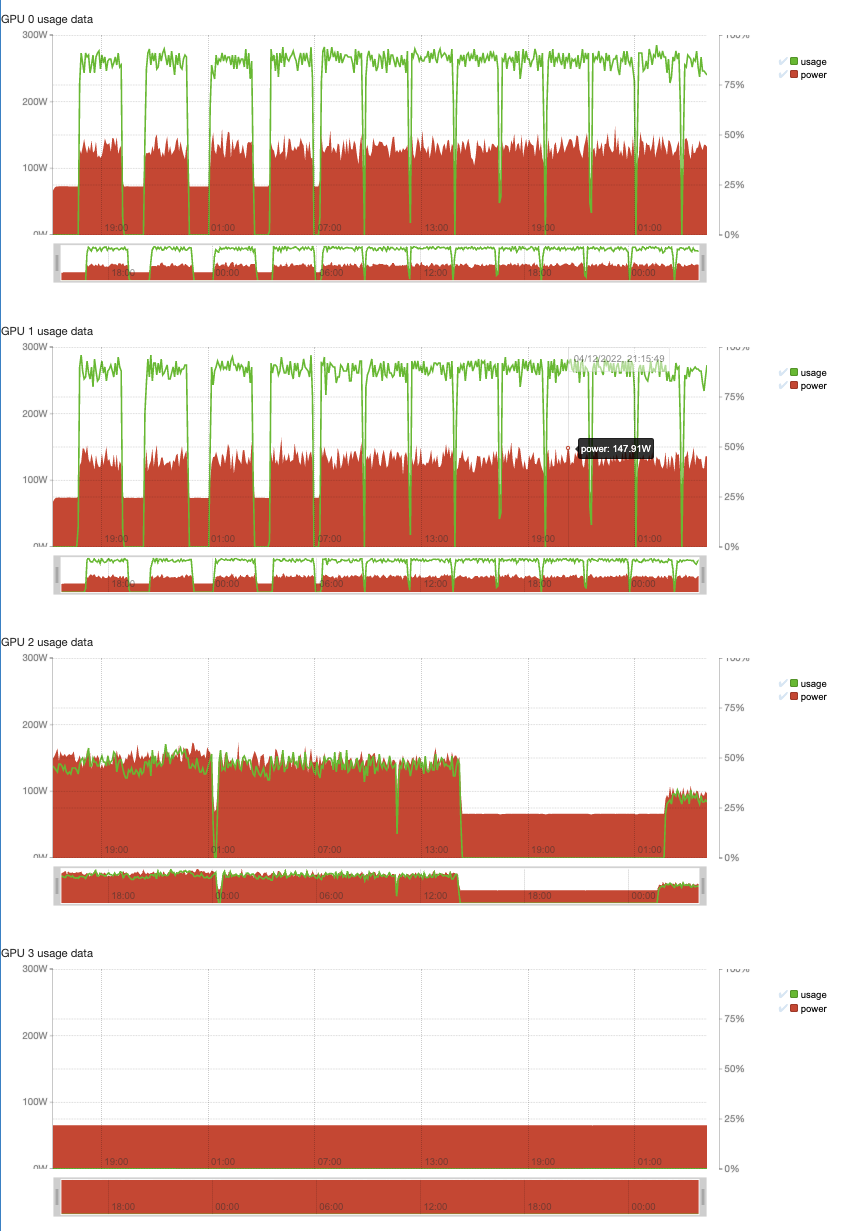
I am trying to train a CLIP model on a cluster at my institute using 4 A100 GPUs. When I try to train it on a dataset of 3M images, the cluster shows that only 2 GPUs are being properly utilized (screenshot). On the other hand, when I try to train it on a subset containing only 500k images, all 4 GPUs get utilized. Everything else is the same, I just change the location of the training data. I am not sure why this is happening, and how I can even begin to diagnose this issue. What can I do to get the most out of my GPUs?
The model reads a csv file containing the locations of training images and their corresponding captions, and the training data is stored on a hard drive on the cluster.
This sounds like an I/O issue. Are you using an iterable dataset? If not, random reading and writing on a spinning hard drive are extremely slow. Therefore, your GPUs are waiting for the data.
You can solve this by sharding your datasets and reading the data sequentially.
Thanks for your reply. I would like to make minimal changes to the implementation provided in the Github repository, so I’ll keep sharding as a last resort. Regarding your first point, I don’t understand why this issue doesn’t happen for 500k samples and only for 3M samples.
It’s hard to say exactly why this happens without knowing more about the dataset, the dataset pipeline and the setup.
Regarding your question, reading across a large section of your drive can be a possible cause, especially if you are making random reads and writing calls.
You could use tools like viztracer to find the bottleneck, This should give you a better idea of what could be causing it and point you in the right direction. Another common mistake is not setting num_workers to load and parse the data.
If the machine has a faster drive (such as an NVME drive), you could try moving your dataset onto it.
TLDR in order of ease:
Try using large num_workers
Move the dataset to a faster drive NVME or SATA SDD if possible
use viztracer or similar tool to visualise time-consuming task