I’m using MAE to pretrain a ViT model on my custom dataset with 4 A800 GPU.
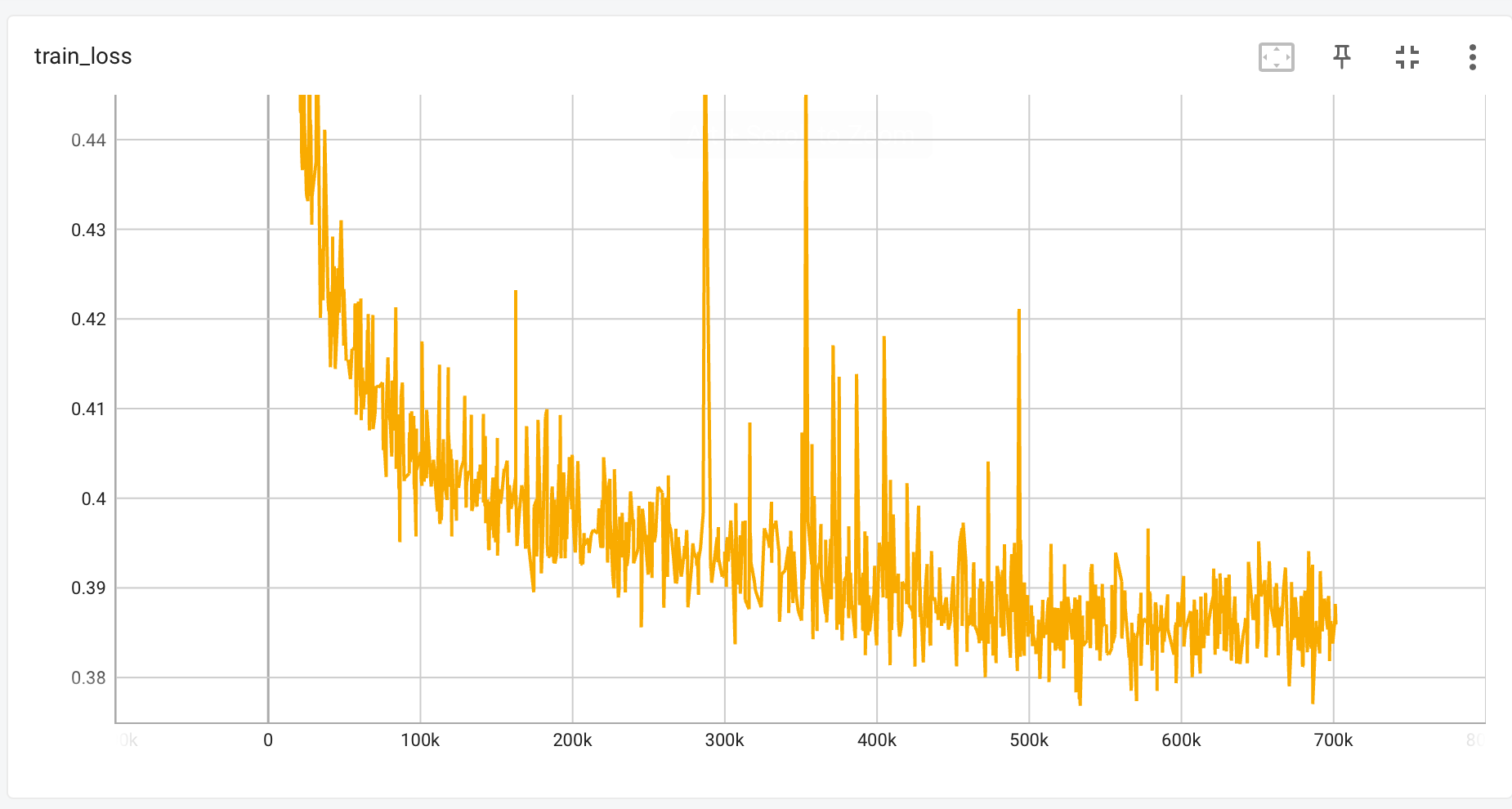
I found that all gradients are nan after epoch 486. (The grad here is manually saved and printed)
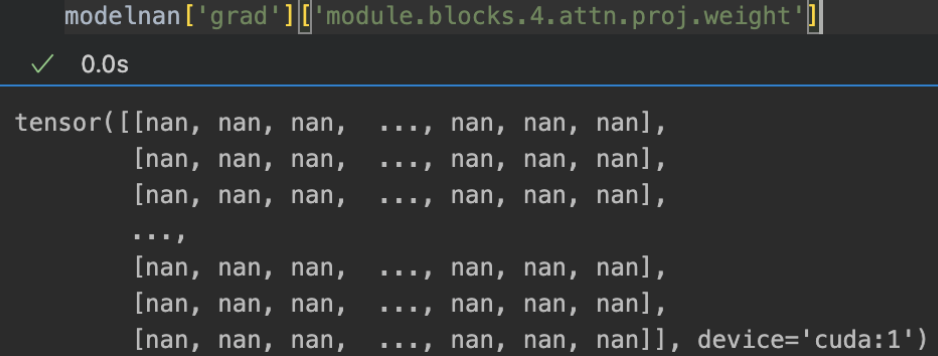
There loss looks good during the triaining, no nan or inf in the loss. But the model’s parameters won’t update anymore.
I tried to use torch.autograd.detect_anomaly() to figure out where the issue comes from:
/usr/local/anaconda3/envs/jiarun_mae/lib/python3.8/site-packages/torch/autograd/__init__.py:197: UserWarning: Error detected in MulBackward0. Traceback of forward call that caused the error:
File "main_pretrain.py", line 229, in <module>
main(args)
File "main_pretrain.py", line 198, in main
train_stats = train_one_epoch(
File "/home/jiarunliu/Documents/scaling/mae/engine_pretrain.py", line 69, in train_one_epoch
loss, _, _ = model(samples, mask_ratio=args.mask_ratio)
File "/usr/local/anaconda3/envs/jiarun_mae/lib/python3.8/site-packages/torch/nn/modules/module.py", line 1190, in _call_impl
return forward_call(*input, **kwargs)
File "/usr/local/anaconda3/envs/jiarun_mae/lib/python3.8/site-packages/torch/nn/parallel/distributed.py", line 1040, in forward
output = self._run_ddp_forward(*inputs, **kwargs)
File "/usr/local/anaconda3/envs/jiarun_mae/lib/python3.8/site-packages/torch/nn/parallel/distributed.py", line 1000, in _run_ddp_forward
return module_to_run(*inputs[0], **kwargs[0])
File "/usr/local/anaconda3/envs/jiarun_mae/lib/python3.8/site-packages/torch/nn/modules/module.py", line 1190, in _call_impl
return forward_call(*input, **kwargs)
File "/home/jiarunliu/Documents/scaling/mae/models_mae.py", line 229, in forward
loss = self.forward_loss(imgs, pred, mask)
File "/home/jiarunliu/Documents/scaling/mae/models_mae.py", line 221, in forward_loss
loss = (loss * mask).sum() / mask.sum() # mean loss on removed patches
File "/usr/local/anaconda3/envs/jiarun_mae/lib/python3.8/site-packages/torch/fx/traceback.py", line 57, in format_stack
return traceback.format_stack()
(Triggered internally at ../torch/csrc/autograd/python_anomaly_mode.cpp:114.)
Traceback (most recent call last):
File "main_pretrain.py", line 229, in <module>
main(args)
File "main_pretrain.py", line 198, in main
train_stats = train_one_epoch(
File "/home/jiarunliu/Documents/scaling/mae/engine_pretrain.py", line 90, in train_one_epoch
loss_scaler(loss, optimizer,
File "/home/jiarunliu/Documents/scaling/mae/util/misc.py", line 302, in __call__
self._scaler.scale(loss).backward(create_graph=create_graph)
File "/usr/local/anaconda3/envs/jiarun_mae/lib/python3.8/site-packages/torch/_tensor.py", line 487, in backward
torch.autograd.backward(
File "/usr/local/anaconda3/envs/jiarun_mae/lib/python3.8/site-packages/torch/autograd/__init__.py", line 197, in backward
Variable._execution_engine.run_backward( # Calls into the C++ engine to run the backward pass
RuntimeError: Function 'MulBackward0' returned nan values in its 0th output.
The corresponding code in the traceback is:
Besides, I use amp + bf16 during training, otherwise the loss will become nan at about epoch 380.
I have tried following strategies but none of them works:
- reduce/increase learning rate
- clip gradient by 1.0 or 0.1
- replace the AdamW optimizer with Adam
- enable/disable norm_pix_loss
- use amp+bf16
- use fp32
Additionally, use a larger learning rate will produce inf in gradients:
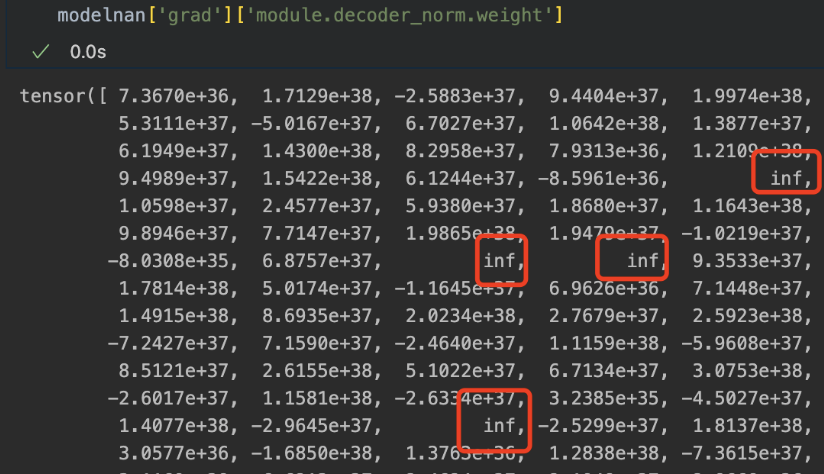
Is there any possible reason for this issue? My package version is torch==1.13.0+cu117, timm==0.3.2.
Thank you!