import torch
data = torch.tensor([[1.,2.,3.,4.], [5.,6.,7.,8.]], requires_grad=True)
batch = data.shape[0]
t_data = data.reshape(batch, 2, 2)
tf_data = torch.zeros((batch, 3, 2, 2))
for i in range(batch):
tf_data[i] = t_data[i].expand_as(tf_data[i])
loss = torch.sum(tf_data)
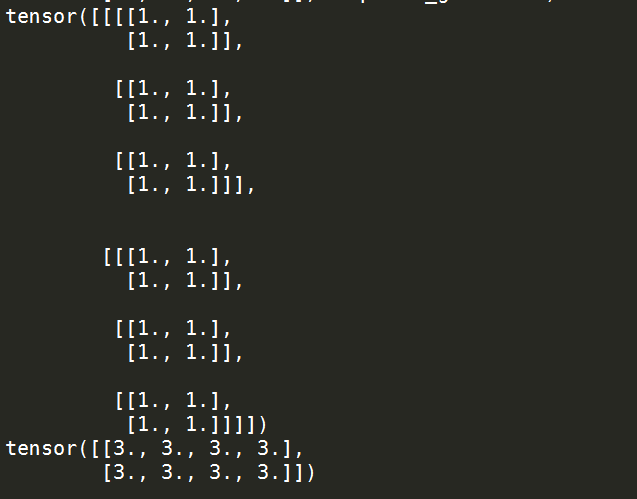
print('tf_data\n', tf_data)
print('data\n', data)
tf_data.register_hook(print)
data.register_hook(print)
loss.backward()
I want to know the gradient flow for some tensor operation like reshape or expand_as, so I wrote above code to test. I got below output.
the grad of data and tf_data is all 3 and 1 no matter how I changed data, can anyone explain the gradient flow for this case in pytorch? How does the pytorch calculate the gradient for this case?
Well, the tf_data grads are very logical since loss = sum (tf_data) .No matter what your code looks like before, and since loss = tf_data[0,0,0,0] + tf_data[0,0,0,1] + ... + tf_data[1,2,1,1] the grad will be just a differentiation with respect to each element which means 1.
Now for data grads, this line tf_data[i] = t_data[i].expand_as(tf_data[i]) is basically repeating (by stacking) t_data[i] ( shape = ( 2, 2) in this case) a number of times until it reaches tf_data[i] dimensions ( (3, 2, 2) in this case). means you are repeating 3 times.
So loss = sum(tf_data) = 3 * sum (t_data) = 3 * sum (data) means whatever your code looks like before ( without changing dimensions) you will get grads = 3.
3 * sum (t_data) = 3 * sum (data) because summing two tensors with same elements and different shapes, will result in the same result.