I’ve looked at many articles and have been Googling for a few days now without being able to fix the issue I’m having. I am having an issue with the autograd PyTorch function in my sequential models. I am trying to implement the PPO algorithm, but for some reason, the gradients don’t propagate to my networks after calling backward on the loss term as seen below in my critic network
In fact, the gradients propagate all the way to the vector of outputs from the network, but they don’t actually propagate through the network (currCriticVals is an array storing values directly from the critic network):
(Sorry for the link. As a new user, I can only have one embed and two links)
Also, note that I am running this on my CPU at the moment if that may cause any problems.
The full code can be found at the following GitHub link:
I have a few debugging lines near the backward function in case you realize it looks a bit messy.
I’m not sure which parameters should get gradients but don’t so could you explain the issue a bit more?
PS: you can post code snippets by wrapping them into three backticks ``` which allows to debug the code easier
Based on the linked code you have to check if you are (accidentally) detaching the tensors form the computation graph vi:
using numpy (Autograd won’t be able to track these operations so you should use PyTorch methods instead. If that’s not possible, write a custom autograd.Function as described here)
rewrapping tensors via x = torch.tensor(x) where x was a tensor attached to a graph
using non-differentiable functions such as torch.argmax
Thank you for your reply! I’m hoping to update both the Actor and Discriminator networks in terms of the L_Final loss function where the Actor network is updated through the L_CLIP loss function and the Critic network is updated through the L_VF function. Both L_CLIP and L_VF are added together to make L_Final which is what .backward() is called on. S is just some noise added on to the loss which shouldn’t affect the backward pass and is why I set it to “requires_grad=False”
L_CLIP = torch.min(r_ts*advantages, torch.clip(r_ts, 1-epsilon, 1+epsilon)*advantages).mean()
# Calculate the critic loss (L_VF)
L_VF = torch.pow(rewards-currCriticVals, 2).mean()
# Get the entropy bonus from a normal distribution
S = torch.tensor(np.random.normal(), dtype=torch.float, requires_grad=False)
#Calculate the final loss (L_CLIP_VF_S)
L_Final = L_CLIP - self.c1*L_VF + self.c2*S
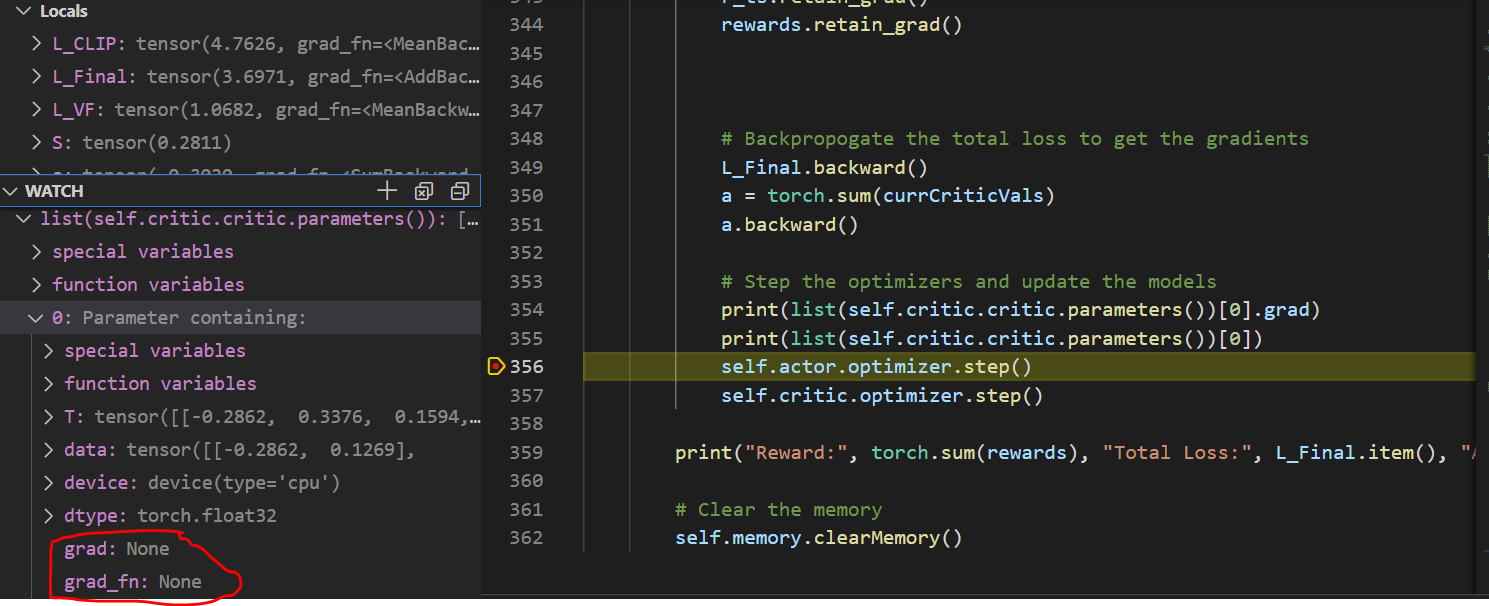
What I’m hoping is that the Critic and Actor networks get a gradient for all parameters. In a simple case, L_VF is the loss for the critic and is what I’m mostly paying attention to when debugging. L_VF is composed of the values received from the critic. So, the process to calculate L_VF is as follows:
collect n critic values and put them in an array currCriticVal = self.critic(observation) # Get value from critic self.storeMemory(...,currCriticVal,...) # Store value in list
turn the array into a tensor and remove the last value: currCriticVals = torch.tensor(currCriticVals[0:advantages.shape[0]], dtype=torch.float, requires_grad=True, device=device)
Calculate the L_VF loss for the critic network L_VF = torch.pow(rewards-currCriticVals, 2).mean()
The interesting part is that currCriticVals receives a grad, but the Critic parameters do not and this is the problem I am having.
I reviewed my code again, I didn’t notice any of the following potential causes you mentioned. I used numpy once, but that was for input into the Critic network, and that value shouldn’t need a gradient. Before calculating the loss, I did rewrap a few tensors, but changing the values from say x = torch.tensor(x) to x2 = torch.tensor(x) didn’t solve the gradient issue. I also used argmax once, but the value received from argmax didn’t need a gradient as it’s just input into one of the networks.
currCriticVals is a new tensor, which requires gradients without any history and will thus detach the computation graph.
This fits into the “rewrapping tensors” point. Assuming currCriticVals is a tensor attached to the computation graph and you want to create a new tensor with its slices, try to use torch.cat or torch.stack instead.
Oh I see now. I didn’t realize changing the list to a torch tensor with torch.tensor removes it from the gradient history. Instead of using currCriticVals = torch.tensor(currCriticVals[0:advantages.shape[0]], dtype=torch.float, requires_grad=True, device=device)
I used currCriticValss = torch.cat(currCriticVals[0:advantages.shape[0]])
Where currCriticVals is a list of tensors.
Now that I changed it, the gradients propagate through the network. Looking back at torch.tensor vs. torch.cat makes perfect sense as to why it wasn’t working before.