I was wondering whether calling optimizer.zero_grad() after after optimizer.step() has the same effect as the usual order within a single iteration? The reason for this is because I am trying to use gradient accumulation in Detectron2 for my model as memory size is limited. However, in Detectron2 every iteration step is defined as a function, including zeroing out gradients, backpropogation and weight update. Therefore, if I put optimizer.zero_grad at first, as step() is called for a new iteration, it will just zero out all gradients instead of accumulating it. If I were to accumulate gradients for a specified number of iterations, I was thinking to put optimizer.zero_grad() after the optimizer step() like the following:
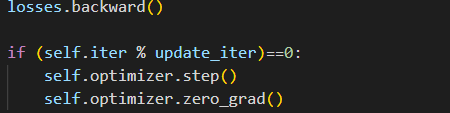
In this case, I will only zero out graidents at a certain number of iterations. I am wondering if my thought process is correct? Thanks (model is trained with DDP).