Hello everyone. I am facing an issue. I am explaining what I am trying to do.
I have a Traffic and Road sign dataset that contains 43 classes. I am trying to classify the images. I am using the resnet34 pre-trained model. I have AMD RX6600 GPU that I use for running the model. For running the model on my AMD GPU I am using Pytorch Directml and using this code
to find the device. Using this dml instance, I push the mode and training data to the GPU. But the problem is weights do not update. After a lot for debugging, I found that the model grad becomes none in the training loop when using GPU. But in the CPU it works totally fine.
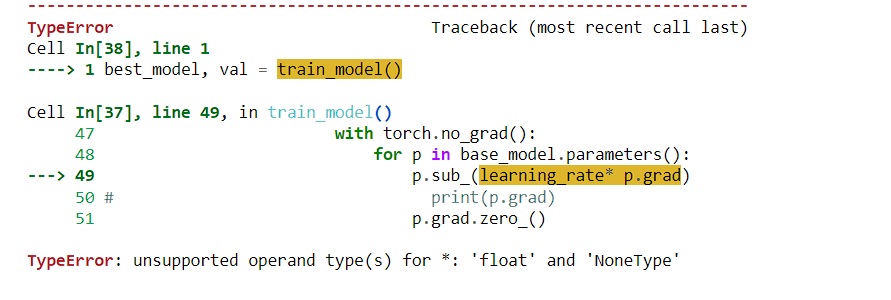
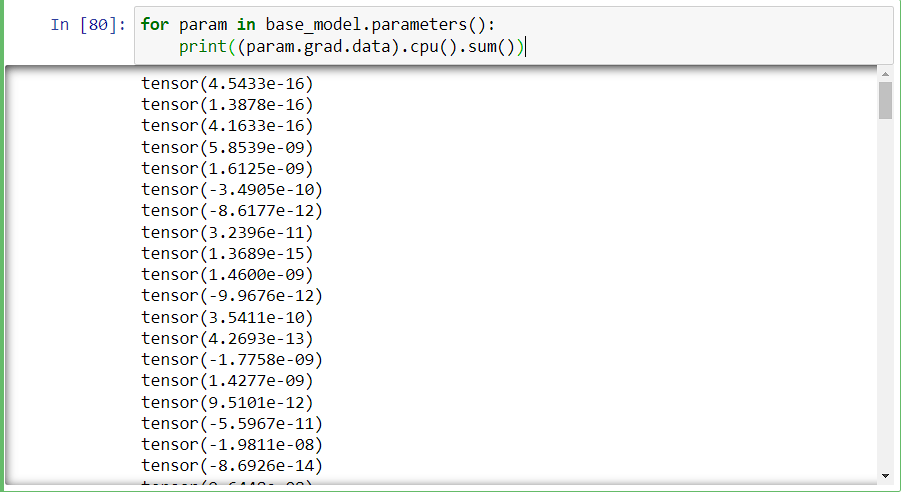
When I want to see the grad values, I found this issue. When the model is in CPU, this print statement prints some numbers. But when I run same code in GPU the following error occurs.
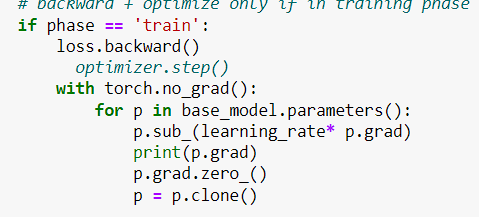
you can see p.grad become none. And that’s why when I use the optimizer.step() nothing is updated and the model does not learn anything. Can anyone help me with this issue? Thanks in advance
But when the model is in the GPU this error happens.
tensor(-4.5475e-13)
tensor(2.2737e-13)
tensor(4.5475e-13)
tensor(-1.3588e-06)
tensor(-1.8833e-06)
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
Cell In[91], line 2
1 for param in base_model.parameters():
----> 2 print((param.grad.data).cpu().sum())
AttributeError: 'NoneType' object has no attribute 'data'
Some of the model parameters are none. I think this is the root cause of the issue.
My manual one iteration code is given below
num_classes = 2
num_epochs = 40
learning_rate = 1e-4
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.AdamW(base_model.parameters(), lr=learning_rate)
#taking only the first batch
for batch in dataloaders['train']:
batch = {k: v.to(dml) for k, v in batch.items()}
break
#forward pass
base_model.train()
outputs = base_model(**batch)
labels = batch['Type']
#backward pass
loss = criterion(outputs, labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
#to see any parameters get updated
for param in base_model.parameters():
print((param.grad.data).cpu().sum())
Can you please tell me why this happens when I run the model in GPU?