Hello,
I am trying to understand how the number of checkpoints in gradient checkpointing affects the memory and runtime for computing gradients.
I found this notebook that explains how gradient checkpointing works. I modified it a bit and ran a couple of experiments to see how the use_reentrant and the segments arguments affect the memory and runtime.
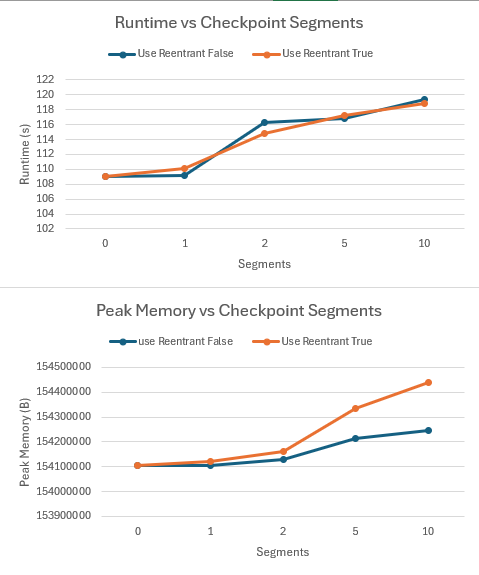
I was surprised to find the following results
- For memory, the data shows almost no improvement when checkpointing is enabled compared to no checkpointing, no matter the number of checkpoints and whether we are using reentrant. From this thread, I understand that the optimal number of checkpoints depends on the specific scenario. However, I still expected at least some improvement in the memory consumption. I’m not quite sure why this is?
- For runtime, the experiment shows the runtime increases as the number of checkpoints increases. However, from the Chen2016 [1] paper, my understanding is the runtime should roughly increase by 30% when checkpointing is enabled due to the extra forward pass, and should remain roughly the same regardless the number of checkpoints. Is the increasing runtime due to the extra overhead required for keeping more checkpoints?
Bellow are my results and their corresponding graphs. Note segments=0 means no checkpointing is enabled.
Any insight will help, and thanks in advance ![]()
| use_reentrant | segments | Runtime (s) | Current Memory (B) | Peak Memory (B) |
|---|---|---|---|---|
| FALSE | 0 | 109.1 | 413527 | 154106538 |
| TRUE | 0 | 109.1 | 413527 | 154106538 |
| FALSE | 1 | 109.12 | 402938 | 154105009 |
| TRUE | 1 | 110.14 | 394474 | 154121963 |
| FALSE | 2 | 116.23 | 382560 | 154127403 |
| TRUE | 2 | 114.86 | 378951 | 154162031 |
| FALSE | 5 | 116.82 | 428681 | 154214720 |
| TRUE | 5 | 117.23 | 507778 | 154334766 |
| FALSE | 10 | 119.44 | 384482 | 154244424 |
| TRUE | 10 | 118.84 | 515236 | 154438154 |
[1] Chen, Tianqi, Bing Xu, Chiyuan Zhang, and Carlos Guestrin. “Training deep nets with sublinear memory cost.” arXiv preprint arXiv:1604.06174 (2016).