Hi all, I have an exploding gradient problem when train the minibatch for 150-200 epochs with batch size = 256 and there’s about 30-60 minibatch (This depends on my specific config). But I have an exploding gradient issues even if I add the code below.

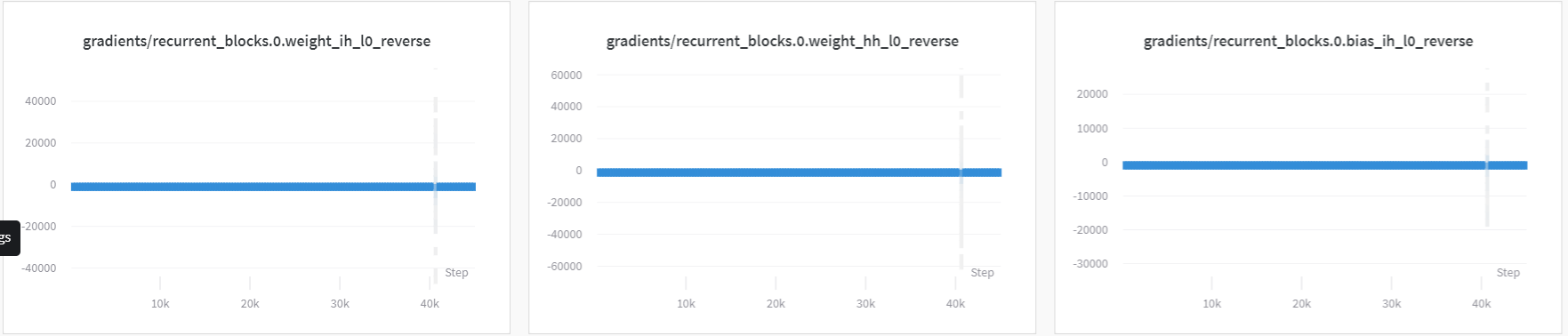
As you can see this below images, notice that in step about 40k there’s the swing of gradients between ± 20k, 40k and 60k respectively. I don’t know why this happens because i use the clip_grad_value_ above. Also Using the learning rate decay from 0.01 to about 0.008 at step 40k.
Or do I need to update the weight parameters by myself something like this

But i think optimizer.step() should do the job and the clip_grad_value_ is an inplace operation so i don’t need to take the return value from function. Please correct if i did anything wrong. Thank you very much
Best regards,
Mint