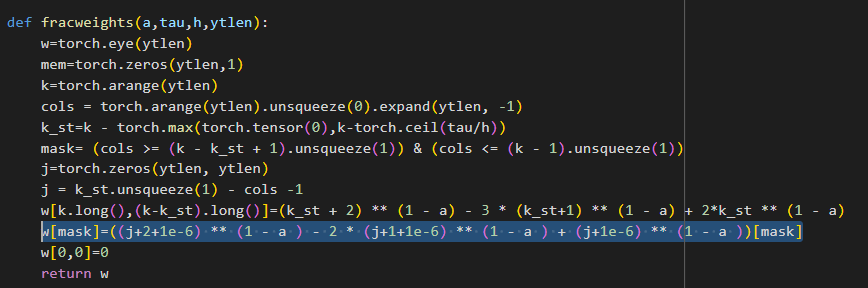
I am trying to use it as pat of the computational graph. I found out that the gradient of the returned matrix w with respect to a is returned as Nan. Hence the optimiser takes NaN value for the learnable parameter a in a PINN routine.How do I solve the NaN problem?
It’s a bit hard to say with this but my best guess is that you’re using your “mask” to remove unvalid values. Unfortunately that means you fall into the “non differentiable” part of the computation and that can play tricks for you.
I would suggest:
If any part of your computation is generating invalid values, you should mask them out BEFORE they’re computed in the forward. If you do it after, then in the backward, these invalid values will happen after the masking and thus lead to NaN
Its quite amusing when i define the weights using for loop , the gradient computation seems to flow properly. But i am trying to vectorize a Finite difference scheme for a numerical solver. I checked the computation in forward pass , it seems to work fine. I did check the anomaly mode in autograd for the backward pass. And the highlighted part of the code is the culprit for the NaN gradient. I tried using a custom gradient evaluation for the weight matrix( using a finite difference for gradient evaluation) and linked it to the chain rule of autodiff. Prediction seems of as gradient of learnable parameter is very small