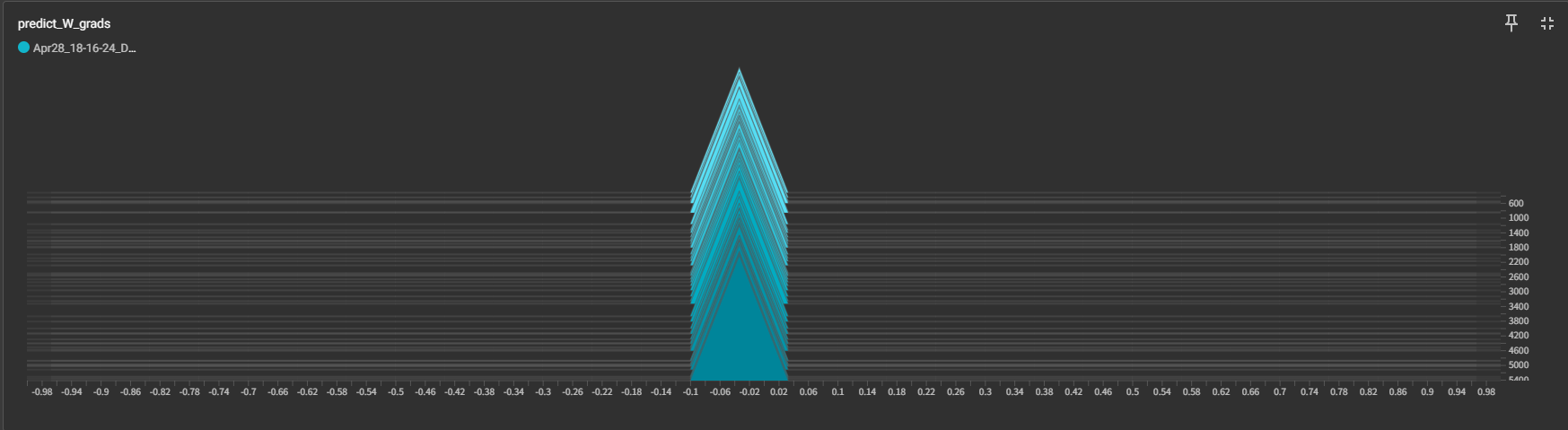
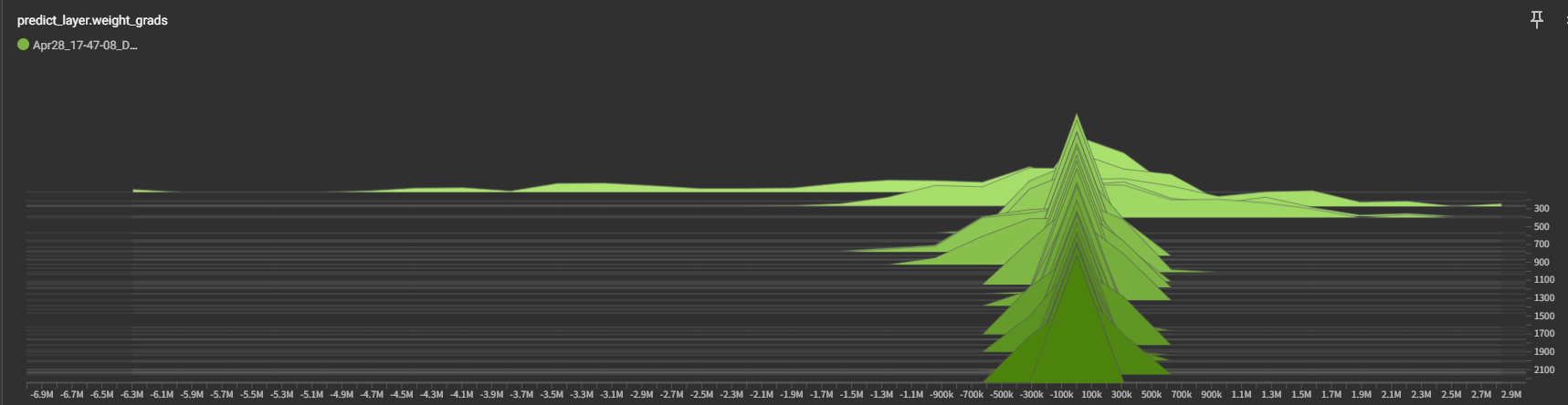
Here is my gradients variation diagram in trial 1.
Here are my codes.
# dataset definition
class PandasDataset(Dataset):
def __init__(self, data: pd.DataFrame):
self.features = data.copy().drop(columns=["SalePrice", "Id"])
self.labels = data["SalePrice"]
assert len(self.features) == len(self.labels)
def __len__(self):
return len(self.features)
def __getitem__(self, index):
feature: pd.Series = self.features.iloc[index]
return torch.tensor(feature.to_numpy(dtype=np.float32), dtype=torch.float32), torch.tensor(self.labels.iloc[index], dtype=torch.float32)
And my data looks like:
Id,MSSubClass,MSZoning,LotFrontage,LotArea,Neighborhood,OverallQual,OverallCond,YearBuilt,YearRemodAdd,Exterior1st,Exterior2nd,ExterQual,Foundation,BsmtQual,BsmtFinType1,BsmtFinSF1,BsmtUnfSF,TotalBsmtSF,HeatingQC,1stFlrSF,2ndFlrSF,GrLivArea,FullBath,KitchenQual,TotRmsAbvGrd,Fireplaces,FireplaceQu,GarageType,GarageYrBlt,GarageFinish,GarageCars,GarageArea,WoodDeckSF,OpenPorchSF,SalePrice,Lack_of_feature_index,Total_Close_Live_Area,Outside_live_area,Total_usable_area,Area_Quality_Indicator,Area_Qual_Cond_Indicator,TotalBath,House_Age,Quality_conditition,Quality_conditition_2,House_Age2
1,60,0,65.0,8450,0,7,5,2003,2003,0,0,3,0,4,6,706,150,856,4,856,854,1710,2,3,8,0,0,0,2003.0,2,2,548,0,61,208500,5,2566,61,2627,18389,91945,3.5,5,35,12,5
2,20,0,80.0,9600,1,6,8,1976,1976,1,1,2,1,4,5,978,284,1262,4,1262,0,1262,2,2,6,1,3,0,1976.0,2,2,460,298,0,181500,5,2524,298,2822,16932,135456,2.5,31,48,14,31
3,60,0,68.0,11250,0,7,5,2001,2002,0,0,3,0,4,6,486,434,920,4,920,866,1786,2,3,6,1,3,0,2001.0,2,2,608,0,42,223500,4,2706,42,2748,19236,96180,3.5,7,35,12,6
4,70,0,60.0,9550,2,7,5,1915,1970,2,2,2,2,3,5,216,540,756,3,961,756,1717,1,3,7,1,4,1,1998.0,1,3,642,0,35,140000,5,2473,307,2780,19460,97300,2.0,91,35,12,36
5,60,0,84.0,14260,3,8,5,2000,2000,0,0,3,0,4,6,655,490,1145,4,1145,1053,2198,2,3,9,1,3,0,2000.0,2,3,836,192,84,250000,4,3343,276,3619,28952,144760,3.5,8,40,13,8
6,50,0,85.0,14115,4,5,5,1993,1995,0,0,2,3,4,6,732,64,796,4,796,566,1362,1,2,5,0,0,0,1993.0,1,2,480,40,30,143000,4,2158,390,2548,12740,63700,2.5,16,25,10,14
7,20,0,75.0,10084,5,8,5,2004,2005,0,0,3,0,5,6,1369,317,1686,4,1694,0,1694,2,3,7,1,4,0,2004.0,2,2,636,255,57,307000,4,3380,312,3692,29536,147680,3.0,3,40,13,2
8,60,0,0.0,10382,6,7,6,1973,1973,3,3,2,1,4,5,859,216,1107,4,1107,983,2090,2,2,7,2,3,0,1973.0,2,2,484,235,204,200000,3,3197,667,3864,27048,162288,3.5,36,42,13,36
9,50,1,51.0,6120,7,7,5,1931,1950,4,2,2,2,3,1,0,952,952,3,1022,752,1774,2,2,8,2,3,1,1931.0,1,2,468,90,0,129900,5,2726,295,3021,21147,105735,2.0,77,35,12,58
10,190,0,50.0,7420,8,5,6,1939,1950,1,1,2,2,3,6,851,140,991,4,1077,0,1077,1,2,5,2,3,0,1939.0,2,1,205,0,4,118000,5,2068,4,2072,10360,62160,2.0,69,30,11,58
This data comes from kaggle and has been preprocessed.
# loss
class RMSELoss(nn.Module):
def __init__(self):
super().__init__()
self.mse_loss = nn.MSELoss()
def forward(self, predict: torch.Tensor, target: torch.Tensor) -> torch.Tensor:
return torch.sqrt(self.mse_loss(predict, target))
# model
class FFN(nn.Module):
def __init__(self, feature: int = 79, inter_dim: int = 512, bias: bool = False):
super(FFN, self).__init__()
self.W1 = nn.Parameter(torch.ones(inter_dim, feature))
self.W2 = nn.Parameter(torch.ones(feature, inter_dim))
self.bias = bias
if bias:
self.b1 = nn.Parameter(torch.zeros(1, inter_dim))
self.b2 = nn.Parameter(torch.zeros(1, feature))
def forward(self, x: torch.tensor) -> torch.Tensor:
if self.bias:
h = F.leaky_relu(F.linear(x, self.W1, self.b1))
h = x + F.leaky_relu(F.linear(h, self.W2, self.b2))
else:
h = F.leaky_relu(F.linear(x, self.W1))
h = x + F.leaky_relu(F.linear(h, self.W2))
return h
class PredictNetwork(nn.Module):
def __init__(self):
super(PredictNetwork, self).__init__()
self.n_layers = 16
self.layers = ModuleList()
self.bias = False
for _ in range(self.n_layers):
self.layers.append(FFN(45, 512, False))
self.predict_W = nn.Parameter(torch.ones(1, 512))
def forward(self, x: torch.tensor) -> torch.Tensor:
h = torch.squeeze(x, dim=-1)
for layer in self.layers:
h = layer(h)
h = F.leaky_relu(F.linear(h, self.predict_W))
return h
And here I provided my codes of training model:
# train device
device = "cuda" if torch.cuda.is_available() else "cpu"
torch.set_default_device(device)
#model
ffn=PredictNetwork()
# dataset
train_set = PandasDataset(train_data)
train_set, valid_set = random_split(
train_set,
[0.8, 0.2],
generator=torch.Generator(device=device)
)
# dataloader
dataloader = torch.utils.data.DataLoader(
train_set,
batch_size=16,
shuffle=True,
generator=torch.Generator(device=device)
)
valid_loader = torch.utils.data.DataLoader(
valid_set,
batch_size=16,
shuffle=False,
generator=torch.Generator(device=device)
)
# Optimizer
optim = torch.optim.Adam(
ffn.parameters(),
lr=adam_lr
)
# loss
loss_func = RMSELoss().to(device)
# init parameter
size = 0
initial_generator = torch.Generator(device=device)
for parameter in ffn.parameters():
if len(parameter.shape) < 2:
torch.nn.init.kaiming_uniform_(parameter.unsqueeze(0), generator=initial_generator)
else:
torch.nn.init.kaiming_uniform_(parameter, generator=initial_generator)
parameter.requires_grad = True
# training
ffn.train()
for epoch in trange(epoches):
for step, (data, label) in enumerate(dataloader):
optim.zero_grad()
predict = ffn(data)
loss: torch.Tensor = loss_func(predict, label)
loss.backward()
# for n, p in ffn.named_parameters():
# print(f"name: {n}, grad: {p.grad}, is leaf: {p.is_leaf}")
optim.step()
Here is all, thanks for help again!