When I am running the same code on cpu its working perfectly but when I am running this on GPU it is throwing x.grad is None.
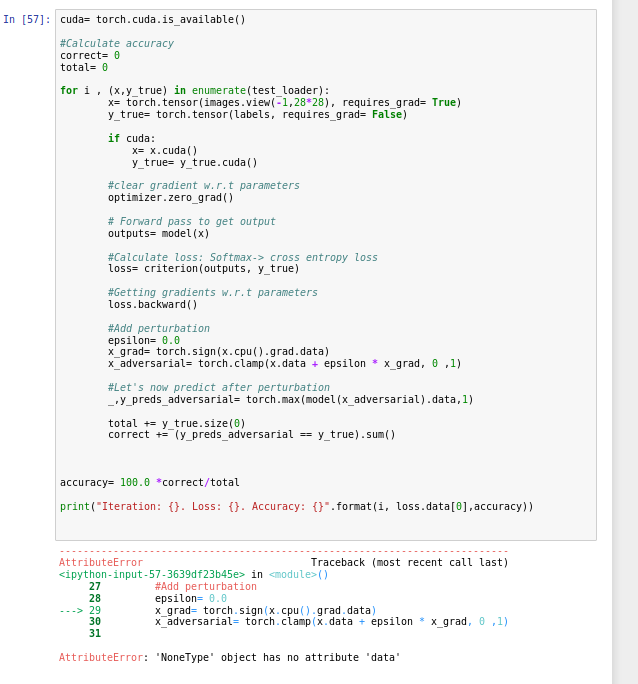
The problem is x = x.cuda() here. The reason is that the gradients will only accumulate in leaf variables of the graph and that is still on the CPU.
So you can either do
x = torch.tensor(..., device=('cuda' if cuda else 'cpu'))
or leave out the requires_grad for the x creation and do
x = x.cuda().detach().requires_grad_()
where you have the transfer to cuda now.
Note that if you have integer labels, requiring grad for them is not the right thing to do.
Best regards
Thomas
P.S.: If you put your code into code block instead of a picture, people can search and find it when they have a similar question.
Thanks Thomas for you help. Now I am able to run but when I’m doing loss.backward(), I am getting an error say saying" RuntimeError: CUDA error: out of memory " Even though it’s only me who is using the CUDA alone.
Then what’s using your GPU memory? I think we’ve all run into this error message, and what’s going wrong clearly depends on what you’re doing.
1 Like