Hello!
My intention is to use two networks, in which the output of the first one is modified before used as input to the second one. Here the picture shows that I am using two inputs X_n+1 and P_n, the output of the first net is thought of as an incremental value of P. Then, the sum of P_n and incremental P is P_n+1 which is used for the second network.
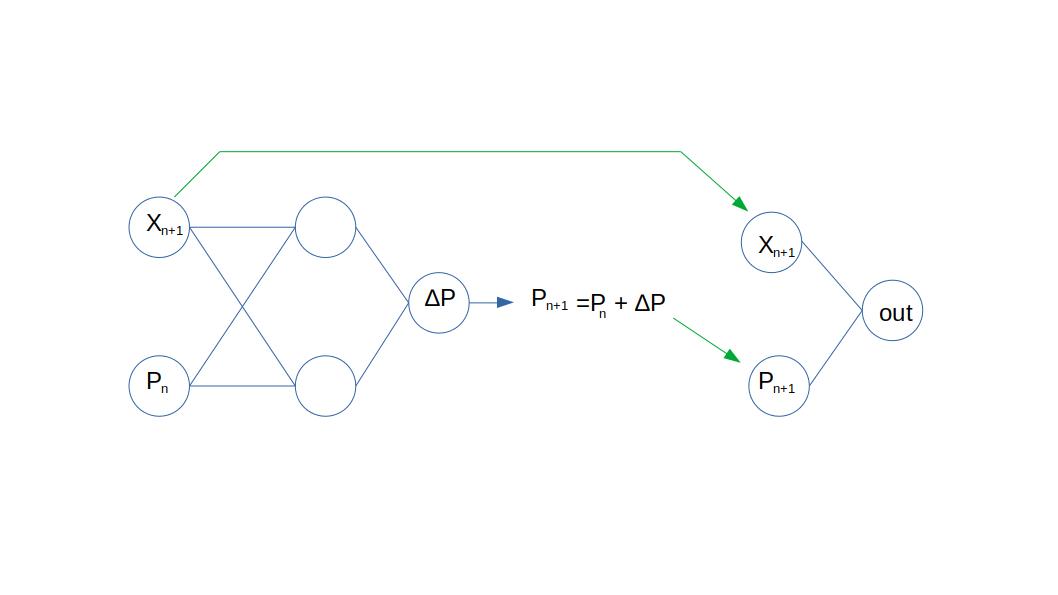
I tried to do this using a single forward pass, the problem is that during the backward process there is an error:
File "/home/eugeniomuttio/anaconda3/envs/py37torch/lib/python3.7/site-packages/torch/tensor.py", line 245, in backward
torch.autograd.backward(self, gradient, retain_graph, create_graph, inputs=inputs)
File "/home/eugeniomuttio/anaconda3/envs/py37torch/lib/python3.7/site-packages/torch/autograd/__init__.py", line 147, in backward
allow_unreachable=True, accumulate_grad=True) # allow_unreachable flag
RuntimeError: one of the variables needed for gradient computation has been modified by an inplace operation: [torch.FloatTensor [2, 1]], which is output 0 of TBackward, is at version 2; expected version 1 instead. Hint: enable anomaly detection to find the operation that failed to compute its gradient, with torch.autograd.set_detect_anomaly(True).
Is there a consistent way to use two networks like this?
My forward pass is:
def forward(self, x):
batch_size, features = x.size()
# First Network
relu_1_out = torch.relu(self.relu_1(x))
internal_inc = self.linear_1(relu_1_out)
# Adding previous internal variable
internal_var = torch.add(x[:, 1], internal_inc)
x2 = torch.cat((x[:, 0], internal_var[:, 0]), dim=0)
# Second Network
out = self.linear_2(x2)
return out, internal_var
Here I am using X that effectively is X = [X_n+1, P_n], internal_var is incremental P and then I add this with P_n to obtain X2 = [X_n+1, P_n+1]. I return internal_var because outside this I update X for the next forward pass.