Hi all,
Currently, I am working on a model with the following setup :
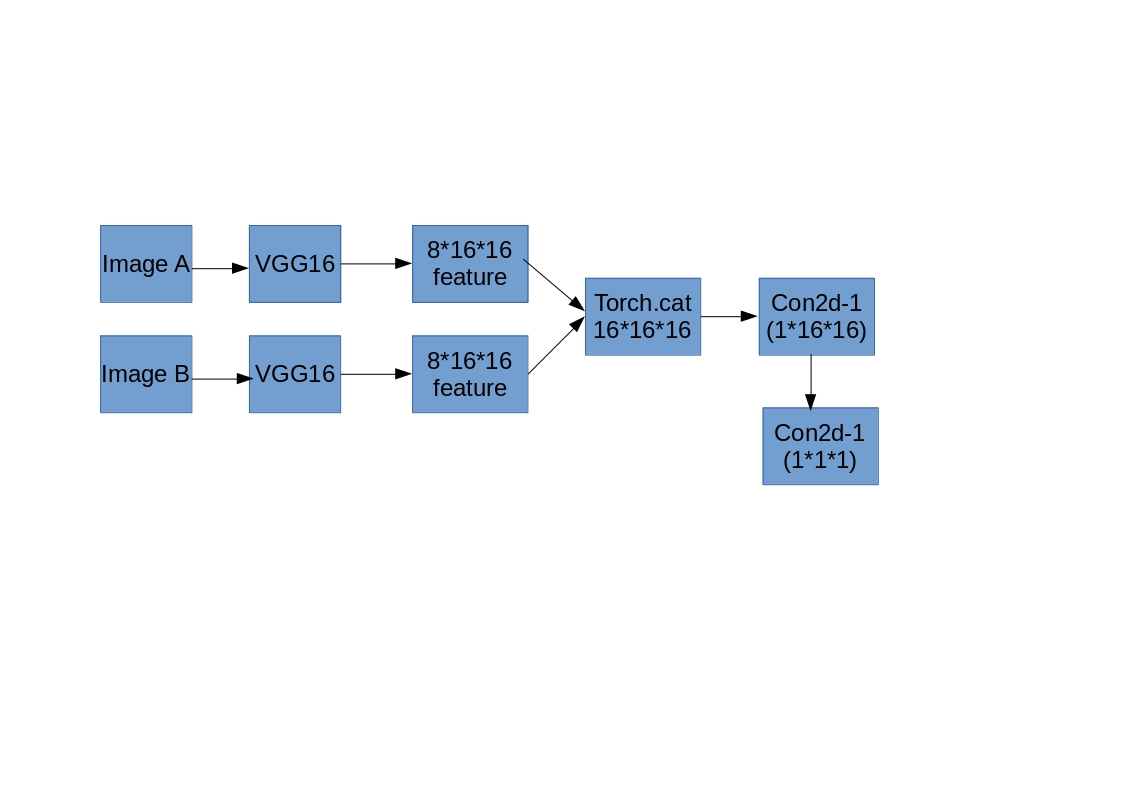
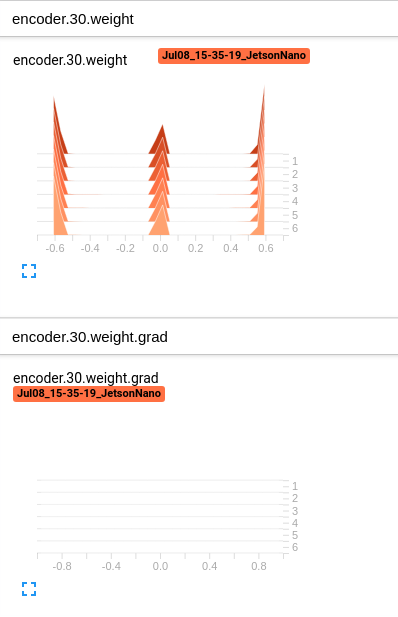
However, it is found that there is no weight.grad for those encoder layers (before torch.cat) in vgg16 from tensorboard as following screen capture : (Picture 1)
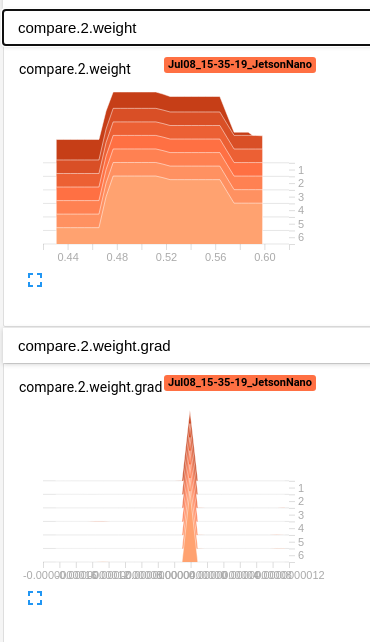
In compare to those Conv2d layers after torch.cat (Picture 2)
Is the torch.cat blocking the loss.backward working in the model ?
Thanks ~ Dick
Here is some code snap for reference :
Model :
class Vgg16PairInput(nn.Module):
def weight_init(self,m):
classname=m.__class__.__name__
if classname.find('ConvTran')!=-1:
m.weight.data.normal_(0,0.1)
def __init__(self):
super(Vgg16PairInput,self).__init__()
self.pretrained_model = models.vgg16(pretrained=True)
self.encoder = nn.Sequential(*list(self.pretrained_model.features.children())[:-1],
nn.Conv2d(512,8,kernel_size=3,stride=1,padding=1),
nn.Sigmoid()
)
self.compare=nn.Sequential(
nn.Conv2d(16,1,kernel_size=3,stride=1,padding=1),
nn.Sigmoid(),
nn.Conv2d(1,1,kernel_size=16,stride=1,padding=0)
#nn.Sigmoid()
)
del self.pretrained_model
def encode(self,images):
code=self.encoder(images)
return code
def forward(self,leftimage,rightimage):
lcode = self.encoder(leftimage)
#print(lcode.shape)
rcode = self.encoder(rightimage)
#print(rcode.shape)
combin = torch.cat((lcode,rcode),1)
#print(combin.shape)
result = self.compare(combin)
return result.to(torch.double)
Main for for training :
lossfunction=nn.BCEWithLogitsLoss()
optimizer = torch.optim.Adam(model.parameters(),lr=0.1)
for epoch in range(epochs):
print('epoch [{}/{}]'.format(epoch+1, epochs))
loss_train = 0
loss_val = 0
totaldiff = 0
model.train()
for i, data in enumerate(trainloader):
tampimg,maskimg,result=data
output=model(tampimg.cuda(),maskimg.cuda())
output=output.view(output.shape[0])
loss=lossfunction(output,result.cuda())
optimizer.zero_grad()
loss.backward()
optimizer.step()
loss_train += loss.data.cpu()
print("Training batch : {} , loss : {:.4f}, Output: {}, Target : {}".format(i,loss.data.cpu(),str(output.sigmoid()),str(result)))
torch.cuda.empty_cache()
 ).
).