Hello everyone! I am trying to train a simple 2 layer MLP on tabular input for a reinforcement learning task with ReLU activations in between and no activation in the end (network predicts log scores). Because of ReLU activations, the training becomes unstable quickly and loss shoots up very high during training. I have added gradient clipping to stabilize the training, but it’s not working always. I have added the clipping as follows:
optimizer.zero_grad()
obj.backward()
torch.nn.utils.clip_grad_value_(doc_scorer.parameters(), 0.9)
` optimizer.step()
However, the gradient values are not getting clipped, as can be seen from the wandb log attached
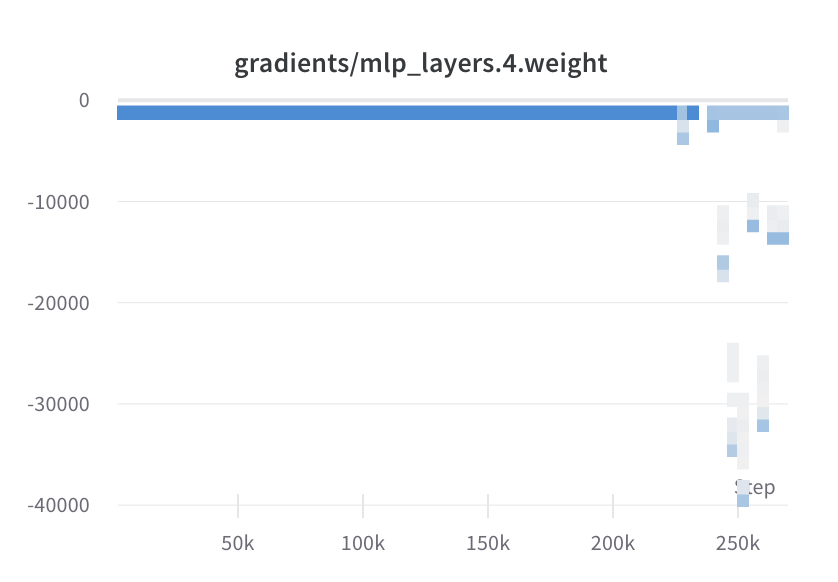
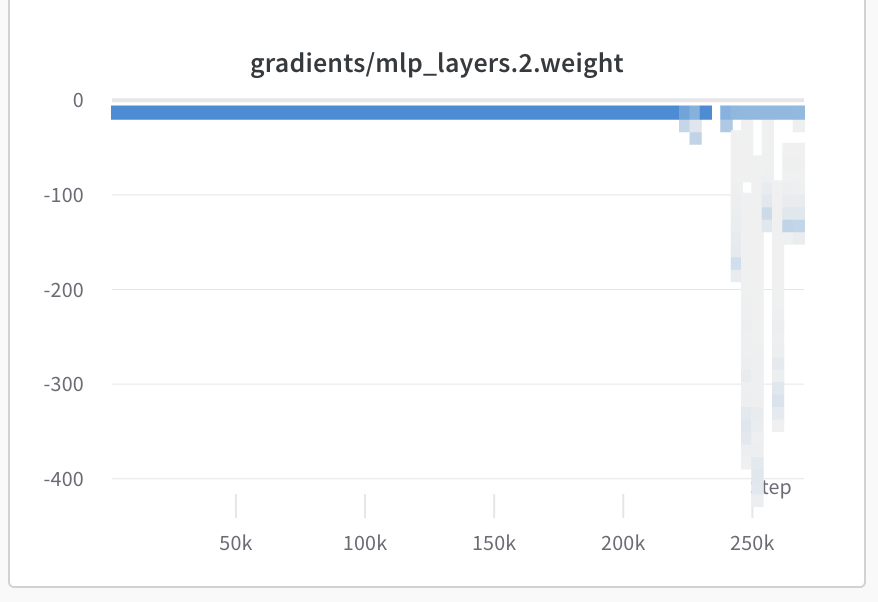
I have read that wandb logs gradient before applying the clipping operations, but if gradient clipping were to function properly, the parameters of the network should not increase in magnitude over time
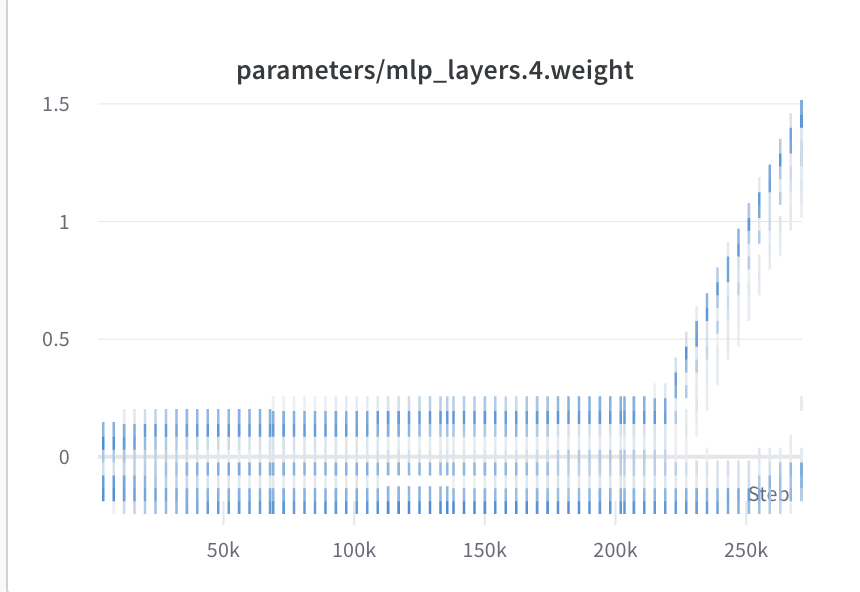
Can anyone help me with any suggestions or pointers to solve this problem? Thanks.