Hi! Here I am with a (maybe) rather weird problem.
So, the big picture is that I am trying to use Pytorch’s optimizers to perform non-linear curve fitting. I have an overall code that is working, but now I need to tweek things to actually work with the model I am interested in.
I will share here a simplified model, to make it easier to understand the issue.
Let’s consider this image:
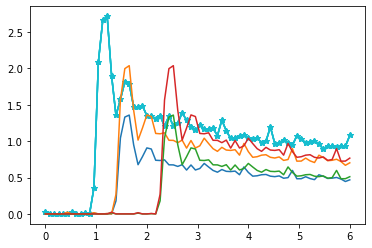
The cyan curve is the “original” input. It known and measured.
The other 4 curves are obtained by scaling in aplitude and translating in time the first one. So our model has 2 parameters: onset time (i.e. temporal translation, ton) and scaling (vp).
TRUE VALUES
tensor([[ 5.0000, 0.5000],
[ 5.0000, 0.7500],
[15.0000, 0.5000],
[15.0000, 0.7500]])
ESTIMATES
tensor([[0.0000, 0.4203],
[0.0000, 0.6305],
[0.0000, 0.3271],
[0.0000, 0.4906]])
As you can see, the first parameter (ton) is not updated at all from its starting value. And that obviuosly affects also the estimate of the amplitude (vp).
I am quite sure that the way I coded my model is such that autograd is unable to compute ita gradient correctly. But I am kind of out of ideas, since I am just trying to port this code from Matlab to pytorch, and with a similar implementation Matlab is able to optimize the value of that parameter.
Here is the whole code I am testing. It should be a self contained working example.
Any idea will be greatly appreciated!!
import torch
import torch.nn as nn
device = 'cuda' if torch.cuda.is_available() else 'cpu'
print(device)
import matplotlib.pyplot as plt
from tqdm import tqdm
class Net(nn.Module):
def __init__(self, p, t, IF, y):
super().__init__()
self.pars = nn.Parameter(p)
self.t = t
self.IF = IF
self.y = y
def forward(self):
self.pars.detach()
return self.cost(self.pars)
def cost(self,p):
out = kmodel(p,self.t,self.IF) - self.y
return torch.sum(out**2)
################
def kmodel(p,t,Cp,device=0):
torch.autograd.set_detect_anomaly(True)
Nv = p.shape[0]
Nt = t.shape[1]
ton = p[:,0].view(Nv,1).int()
vp = p[:,1].view(Nv,1).to(device)
# this is how I tried to introduce the temporal shift
# and here is where I probably lost Autograd ...
for i in range(Nv):
Cp[i,ton[i]:] = Cp[i,:Nt-ton[i]]
Cp[i,:ton[i]] = 0
out = vp*Cp
return out
##################
# Simulate data
##################
n = 2
p0 = torch.linspace(5, 15, n) # ton
p1 = torch.linspace(0.5, 0.75, n) # vp
p_true = []
for i in range(n):
for j in range(n):
p_true.append([p0[i], p1[j]])
p_true = torch.tensor(p_true).to(device)
Nv = p_true.shape[0]
print(Nv)
IF = torch.tensor([[0.0309, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0220, 0.0000, 0.0000,
0.0074, 0.0000, 0.3594, 2.0850, 2.6615, 2.7160, 1.8999, 1.3524, 1.5733,
1.8137, 1.7839, 1.4743, 1.4680, 1.4860, 1.3490, 1.3471, 1.3055, 1.3520,
1.2053, 1.3447, 1.2073, 1.2478, 1.3872, 1.2890, 1.1951, 1.1463, 1.2195,
1.1701, 1.1634, 1.1765, 1.0766, 1.2907, 1.1409, 1.0373, 1.0479, 1.0766,
1.0842, 1.0371, 1.0241, 1.0439, 0.9803, 0.9966, 1.1955, 0.9665, 0.9679,
1.0223, 0.9714, 0.9415, 1.0756, 1.0336, 0.9744, 0.9825, 1.0016, 0.9592,
0.8908, 0.9362, 0.9347, 0.9198, 0.9353, 0.9279, 1.0776]]).to(device)
IF = torch.repeat_interleave(IF, repeats=Nv, dim=0).to(device)
t = torch.unsqueeze(torch.linspace(0, 2400*150/1000/60, 70), dim=0).to(device)
t = torch.repeat_interleave(t, repeats=Nv, dim=0)
y_true = kmodel(p_true,t.clone(),IF.clone()).to(device)
y = y_true + 0.00*torch.randn(y_true.size()).to(device)
plt.figure()
plt.plot(t.cpu().numpy()[0,:].T,IF.cpu().numpy().T,'-*', color='C9')
plt.plot(t.cpu().numpy()[:16,:].T,y.cpu().numpy()[:16,:].T);
plt.show()
##################
# Optimization
##################
def loss(y_pred, y_true):
return y_pred
training_steps = 10000
lr = 0.01
p = torch.tensor([[0.0,0.0]]*Nv)
model = Net(p,t, IF, y)
with tqdm(total=training_steps) as pbar:
for epoch in range(training_steps ):
# trying to change the value of the learning rate
# it didn't really help ...
if epoch % 1000 == 0:
lr *= 0.1
optim = torch.optim.Adamax(model.parameters(), lr = lr)
optim.zero_grad()
ypred = model()
ll = loss(ypred, _)
ll.backward()
optim.step()
# progress bar settings
pbar.set_postfix(loss=ll.item(),p_est=list(model.parameters())[0].data[0], lr = lr, refresh=False)
pbar.update(1)
if ll.item() <= 1e-4:
break
p_est = list(model.parameters())[0].data
print(p_est)
print(p_true)
y_est = kmodel(p_est,t,IF)
plt.figure(figsize=(20,10))
plt.plot(t.cpu().numpy()[0,:].T,IF.cpu().numpy().T, color='C4');
plt.plot(t.cpu().numpy()[0:16,:].T,y.cpu().numpy()[0:16,:].T, '-*',color='C1');
plt.plot(t.cpu().numpy()[0:16,:].T,y_est.cpu().numpy()[0:16,:].T, color='C2');

