I’m trying to train two sequential neural networks in one optimizer. I read that this can be done by defining the optimizer as follows:
optimizer_domain = torch.optim.SGD(list(sentences_model.parameters()) + list(words_model.parameters()),lr=0.001)
This also works for simple models after testing. However, my model is a bit more complex. A schematic overview is shown below:
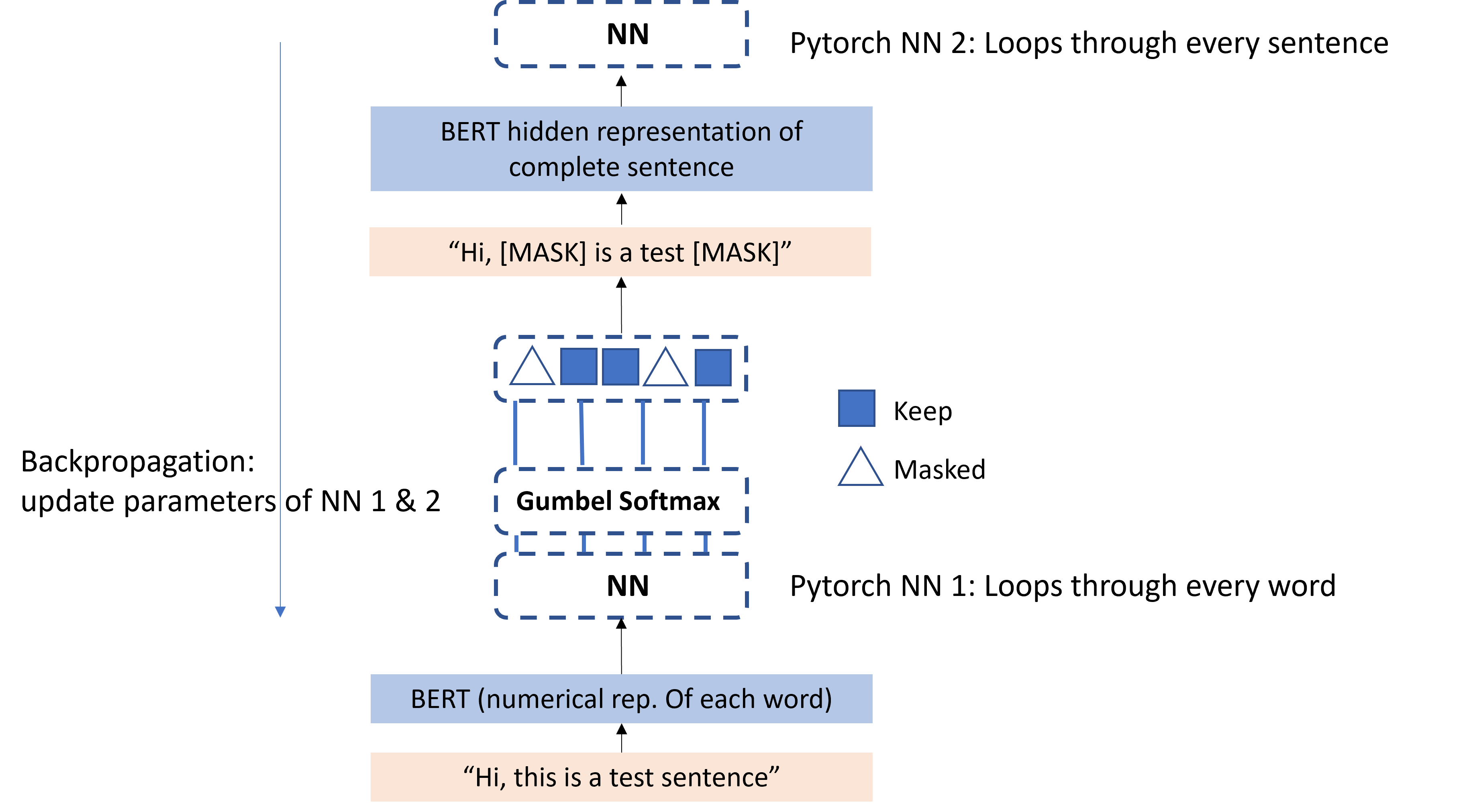
The code for the model is found below:
criterion = nn.MSELoss()
optimizer_domain = torch.optim.SGD(list(words_model.parameters()) + list(sentences_model.parameters()),lr=0.001)
epochs = 2
costval_shared_d = []
data = Data(df_xy, yi_train)
train_loader=DataLoader(data,batch_size=batch_size_Tanh,shuffle=True)
for j in range(epochs):
for x,y in train_loader:
words_model_output = words_model(x,y)
if (all words of a sentence have passed):
adjusted_sentence = some_functions(words_model_output)
train_loader_sentences = DataLoader(adjusted_sentences,batch_size=batch_size_sentences,shuffle=True)
for x_sentence,y_sentence in train_loader_sentences:
output_sentences = sentences_model(x_sentence)
#calculating loss
cost_shared_d = criterion(y_sentence,y_real)
print(words_model.param1.grad,sentences_model.grad) #Here the gradients of all parameters of words_model are None
optimizer_domain.zero_grad()
cost_shared_d.backward()
print(words_model.param1.grad,sentences_model.grad) #Here too grad=None of words_model
optimizer_domain.step()
costval_shared_d.append(cost_shared_d)
As you can see in the code above I’m first loading a dataset of all (numerical representations of) words and I’m passing them through words_model to decide if the words should be masked in the sentence. Then, if it has been decided which words in the sentence should be masked, the new sentence with masked words is passed on through some functions to obtain the representation of the sentence. Then the sentence is passed onto a train_loader that feeds the sentence to sentences_model, which is the second neural network. This model tries to classify the domain of the sentence.
Then the loss is calculated and the optimizer makes a step. But then I see that only the parameters of the sentences_model are updated and not the parameters of the words_model where the gradient is zero.
I’m not sure how I can also train the first neural network, the words_model, at the same time. Because the input of the second neural network is the output of the first neural network and the sequential network is trained on a classification task that only uses the output of the second network, it is important that those networks are updated simultaneously.
I’m suspecting that I break some sort of a gradient ‘line’ somewhere when I perform the functions on the outputs of the first model. But I’m not finding the underlying cause.
Any thoughts or help would be greatly appreciated.
