I am dealing with a classification problem (5000 classes).
My network has 3 MLP layers followed by 1 LSTM block.
class Model(nn.Module):
def __init__(self, embedding_dim, hidden_dim, output_size, num_selected, layer_size=1):
super(Model, self).__init__()
self.layer_size = layer_size
self.hidden_size = hidden_dim
self.fc = nn.Sequential(
nn.Linear(4000, 1024),
nn.ReLU(),
nn.Linear(1024, 512),
nn.ReLU(),
nn.Linear(512, embedding_dim),
nn.ReLU(),
)
self.lstm = nn.LSTM(embedding_dim, hidden_dim, bidirectional=True, num_layers=layer_size)
self.hidden2tag = nn.Linear(2*hidden_dim, output_size)
def forward(self, input_vector):
embeddings = self.fc(input_vector)
lstm_output, _ = self.lstm(embeddings)
logits = self.hidden2tag(lstm_output)
return logits
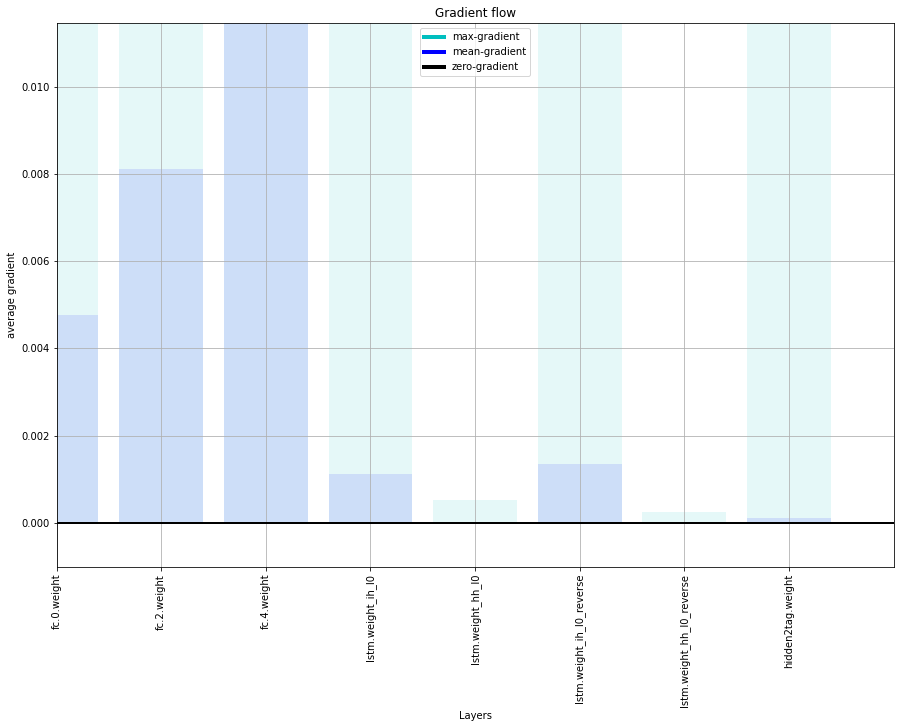
This is the gradient flow observed. Are my gradients exploding in the Linear layers and vanishing in the LSTM? How do I bring uniformity to this flow?
Performance is also affected as the network always predicts a single class as output